 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Diabetic Macular Edema Treatment Responses Using OCT: Dataset and Methods of APTOS Competition
May 09, 2025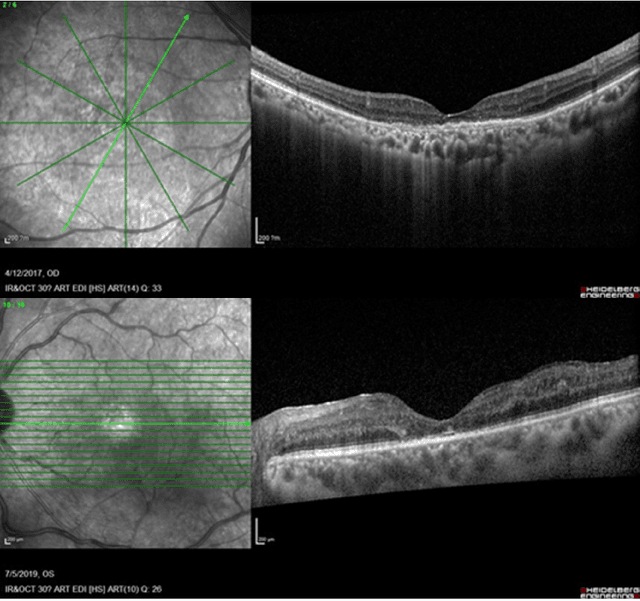
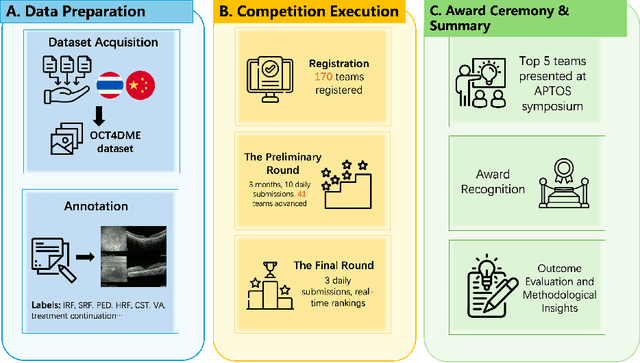

Diabetic macular edema (DME) significantly contributes to visual impairment in diabetic patients. Treatment responses to intravitreal therapies vary, highlighting the need for patient stratification to predict therapeutic benefits and enable personalized strategies. To our knowledge, this study is the first to explore pre-treatment stratification for predicting DME treatment responses. To advance this research, we organized the 2nd Asia-Pacific Tele-Ophthalmology Society (APTOS) Big Data Competition in 2021. The competition focused on improving predictive accuracy for anti-VEGF therapy responses using ophthalmic OCT images. We provided a dataset containing tens of thousands of OCT images from 2,000 patients with labels across four sub-tasks. This paper details the competition's structure, dataset, leading methods, and evaluation metrics. The competition attracted strong scientific community participation, with 170 teams initially registering and 41 reaching the final round. The top-performing team achieved an AUC of 80.06%, highlighting the potential of AI in personalized DME treatment and clinical decision-making.
GEMA-Score: Granular Explainable Multi-Agent Score for Radiology Report Evaluation
Mar 07, 2025



Automatic medical report generation supports clinical diagnosis, reduces the workload of radiologists, and holds the promise of improving diagnosis consistency. However, existing evaluation metrics primarily assess the accuracy of key medical information coverage in generated reports compared to human-written reports, while overlooking crucial details such as the location and certainty of reported abnormalities. These limitations hinder the comprehensive assessment of the reliability of generated reports and pose risks in their selection for clinical use. Therefore, we propose a Granular Explainable Multi-Agent Score (GEMA-Score) in this paper, which conducts both objective quantification and subjective evaluation through a large language model-based multi-agent workflow. Our GEMA-Score parses structured reports and employs NER-F1 calculations through interactive exchanges of information among agents to assess disease diagnosis, location, severity, and uncertainty. Additionally, an LLM-based scoring agent evaluates completeness, readability, and clinical terminology while providing explanatory feedback. Extensive experiments validate that GEMA-Score achieves the highest correlation with human expert evaluations on a public dataset, demonstrating its effectiveness in clinical scoring (Kendall coefficient = 0.70 for Rexval dataset and Kendall coefficient = 0.54 for RadEvalX dataset). The anonymous project demo is available at: https://github.com/Zhenxuan-Zhang/GEMA_score.
Decoding Report Generators: A Cyclic Vision-Language Adapter for Counterfactual Explanations
Nov 08, 2024
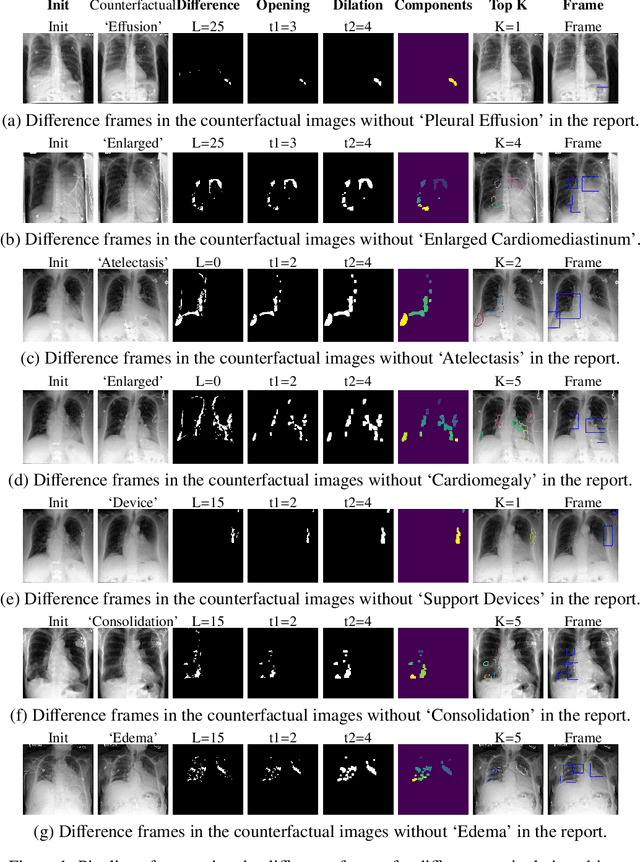
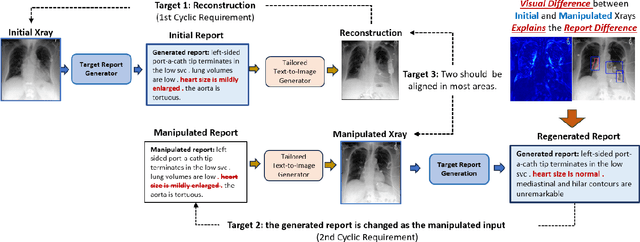
Despite significant advancements in report generation methods, a critical limitation remains: the lack of interpretability in the generated text. This paper introduces an innovative approach to enhance the explainability of text generated by report generation models. Our method employs cyclic text manipulation and visual comparison to identify and elucidate the features in the original content that influence the generated text. By manipulating the generated reports and producing corresponding images, we create a comparative framework that highlights key attributes and their impact on the text generation process. This approach not only identifies the image features aligned to the generated text but also improves transparency but also provides deeper insights into the decision-making mechanisms of the report generation models. Our findings demonstrate the potential of this method to significantly enhance the interpretability and transparency of AI-generated reports.
Diff3Dformer: Leveraging Slice Sequence Diffusion for Enhanced 3D CT Classification with Transformer Networks
Jun 24, 2024The manifestation of symptoms associated with lung diseases can vary in different depths for individual patients, highlighting the significance of 3D information in CT scans for medical image classification. While Vision Transformer has shown superior performance over convolutional neural networks in image classification tasks, their effectiveness is often demonstrated on sufficiently large 2D datasets and they easily encounter overfitting issues on small medical image datasets. To address this limitation, we propose a Diffusion-based 3D Vision Transformer (Diff3Dformer), which utilizes the latent space of the Diffusion model to form the slice sequence for 3D analysis and incorporates clustering attention into ViT to aggregate repetitive information within 3D CT scans, thereby harnessing the power of the advanced transformer in 3D classification tasks on small datasets. Our method exhibits improved performance on two different scales of small datasets of 3D lung CT scans, surpassing the state of the art 3D methods and other transformer-based approaches that emerged during the COVID-19 pandemic, demonstrating its robust and superior performance across different scales of data. Experimental results underscore the superiority of our proposed method, indicating its potential for enhancing medical image classification tasks in real-world scenarios.
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
Jun 21, 2024In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.