 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Tilt Matching
Apr 20, 2026Masked diffusion large language models (dLLMs) are a promising alternative to autoregressive generation. While reinforcement learning (RL) methods have recently been adapted to dLLM fine-tuning, their objectives typically depend on sequence-level marginal likelihoods, which are intractable for masked diffusion models. To address this, we derive Discrete Tilt Matching (DTM), a likelihood-free method that recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting. DTM takes the form of a weighted cross-entropy objective with explicit minimizer, and admits control variates that improve training stability. On a synthetic maze-planning task, we analyze how DTM's annealing schedule and control variates affect training stability and prevent mode collapse. At scale, fine-tuning LLaDA-8B-Instruct with DTM yields strong gains on Sudoku and Countdown while remaining competitive on MATH500 and GSM8K.
CUTEv2: Unified and Configurable Matrix Extension for Diverse CPU Architectures with Minimal Design Overhead
Apr 13, 2026Matrix extensions have emerged as an essential feature in modern CPUs to address the surging demands of AI workloads. However, existing designs often incur substantial hardware and software design overhead. Tight coupling with the CPU pipeline complicates integration across diverse CPUs, while fine-grained synchronous instructions hinder the development of high-performance kernels. This paper proposes a unified and configurable CPU matrix extension architecture. By decoupling matrix units from the CPU pipeline, the design enables low-overhead integration while maintaining close coordination with existing compute and memory resources. The configurable matrix unit supports mixed-precision operations and adapts to diverse compute demands and memory bandwidth constraints. An asynchronous matrix multiplication abstraction with flexible granularity conceals hardware details, simplifies matrix-vector overlap, and supports a unified software stack. The architecture is integrated into four open-source CPU RTL platforms and evaluated on representative AI models. Matrix unit utilization under GEMM workloads exceeds 90% across all platforms. When configured with compute throughput and memory bandwidth comparable to Intel AMX, our design achieves speedups of 1.57x, 1.57x, and 2.31x on ResNet, BERT, and Llama3, with over 30% of the gains attributed to overlapped matrix-vector execution. A 4 TOPS@2GHz matrix unit occupies only 0.53 mm\textsuperscript{2} in 14nm CMOS. These results demonstrate strong cross-platform adaptability and effective hardware-software co-optimization, offering a practical matrix extension for the open-source community.
RoboRouter: Training-Free Policy Routing for Robotic Manipulation
Mar 12, 2026Research on robotic manipulation has developed a diverse set of policy paradigms, including vision-language-action (VLA) models, vision-action (VA) policies, and code-based compositional approaches. Concrete policies typically attain high success rates on specific task distributions but lim-ited generalization beyond it. Rather than proposing an other monolithic policy, we propose to leverage the complementary strengths of existing approaches through intelligent policy routing. We introduce RoboRouter, a training-free framework that maintains a pool of heterogeneous policies and learns to select the best-performing policy for each task through accumulated execution experience. Given a new task, RoboRouter constructs a semantic task representation, retrieves historical records of similar tasks, predicts the optimal policy choice without requiring trial-and-error, and incorporates structured feedback to refine subsequent routing decisions. Integrating a new policy into the system requires only lightweight evaluation and incurs no training overhead. Across simulation benchmark and real-world evaluations, RoboRouter consistently outperforms than in-dividual policies, improving average success rate by more than 3% in simulation and over 13% in real-world settings, while preserving execution efficiency. Our results demonstrate that intelligent routing across heterogeneous, off-the-shelf policies provides a practical and scalable pathway toward building more capable robotic systems.
T-Rex: Task-Adaptive Spatial Representation Extraction for Robotic Manipulation with Vision-Language Models
Jun 24, 2025Building a general robotic manipulation system capable of performing a wide variety of tasks in real-world settings is a challenging task. Vision-Language Models (VLMs) have demonstrated remarkable potential in robotic manipulation tasks, primarily due to the extensive world knowledge they gain from large-scale datasets. In this process, Spatial Representations (such as points representing object positions or vectors representing object orientations) act as a bridge between VLMs and real-world scene, effectively grounding the reasoning abilities of VLMs and applying them to specific task scenarios. However, existing VLM-based robotic approaches often adopt a fixed spatial representation extraction scheme for various tasks, resulting in insufficient representational capability or excessive extraction time. In this work, we introduce T-Rex, a Task-Adaptive Framework for Spatial Representation Extraction, which dynamically selects the most appropriate spatial representation extraction scheme for each entity based on specific task requirements. Our key insight is that task complexity determines the types and granularity of spatial representations, and Stronger representational capabilities are typically associated with Higher overall system operation costs. Through comprehensive experiments in real-world robotic environments, we show that our approach delivers significant advantages in spatial understanding, efficiency, and stability without additional training.
AntiGrounding: Lifting Robotic Actions into VLM Representation Space for Decision Making
Jun 14, 2025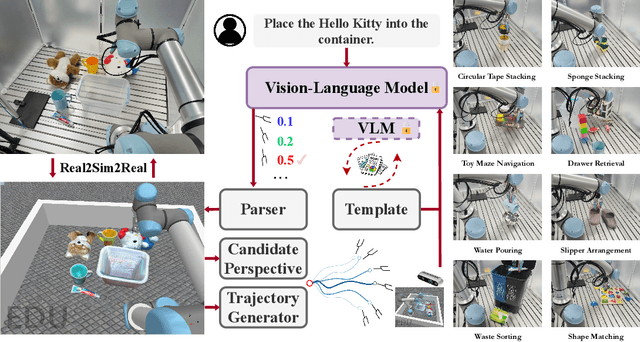
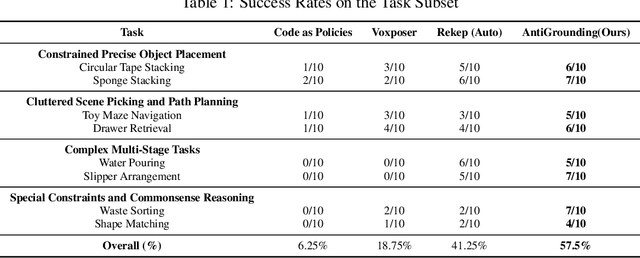
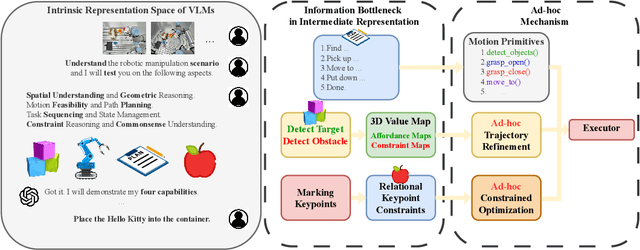

Vision-Language Models (VLMs) encode knowledge and reasoning capabilities for robotic manipulation within high-dimensional representation spaces. However, current approaches often project them into compressed intermediate representations, discarding important task-specific information such as fine-grained spatial or semantic details. To address this, we propose AntiGrounding, a new framework that reverses the instruction grounding process. It lifts candidate actions directly into the VLM representation space, renders trajectories from multiple views, and uses structured visual question answering for instruction-based decision making. This enables zero-shot synthesis of optimal closed-loop robot trajectories for new tasks. We also propose an offline policy refinement module that leverages past experience to enhance long-term performance. Experiments in both simulation and real-world environments show that our method outperforms baselines across diverse robotic manipulation tasks.
M2UD: A Multi-model, Multi-scenario, Uneven-terrain Dataset for Ground Robot with Localization and Mapping Evaluation
Mar 16, 2025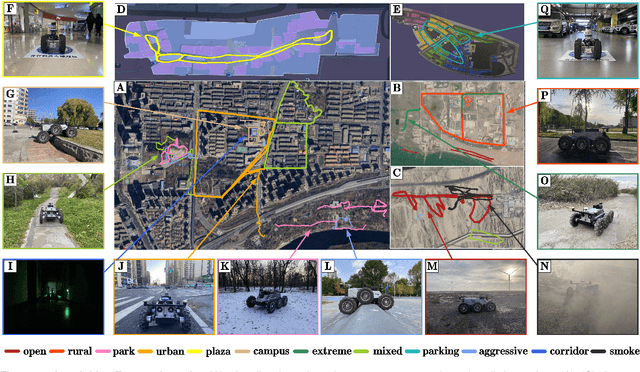
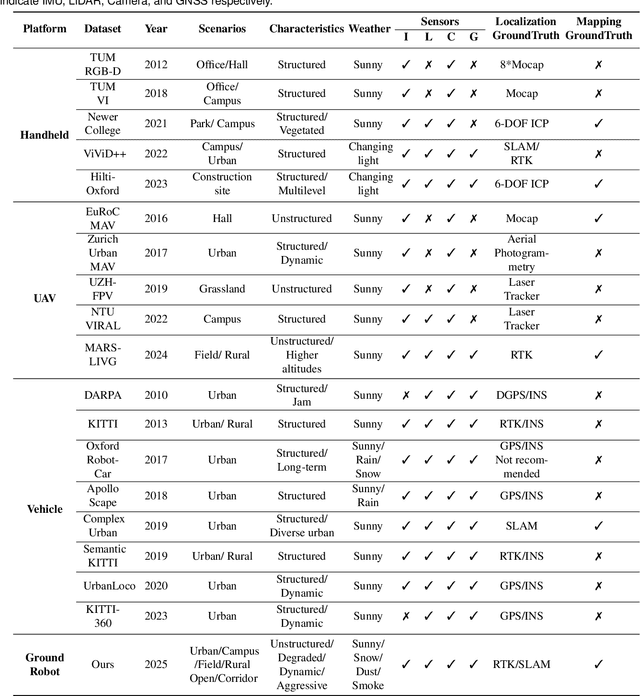
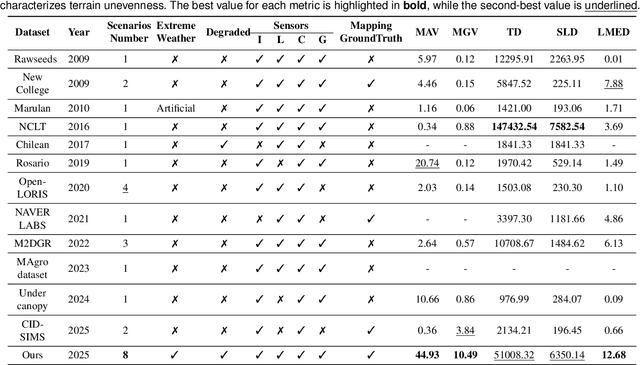

Ground robots play a crucial role in inspection, exploration, rescue, and other applications. In recent years, advancements in LiDAR technology have made sensors more accurate, lightweight, and cost-effective. Therefore, researchers increasingly integrate sensors, for SLAM studies, providing robust technical support for ground robots and expanding their application domains. Public datasets are essential for advancing SLAM technology. However, existing datasets for ground robots are typically restricted to flat-terrain motion with 3 DOF and cover only a limited range of scenarios. Although handheld devices and UAV exhibit richer and more aggressive movements, their datasets are predominantly confined to small-scale environments due to endurance limitations. To fill these gap, we introduce M2UD, a multi-modal, multi-scenario, uneven-terrain SLAM dataset for ground robots. This dataset contains a diverse range of highly challenging environments, including cities, open fields, long corridors, and mixed scenarios. Additionally, it presents extreme weather conditions. The aggressive motion and degradation characteristics of this dataset not only pose challenges for testing and evaluating existing SLAM methods but also advance the development of more advanced SLAM algorithms. To benchmark SLAM algorithms, M2UD provides smoothed ground truth localization data obtained via RTK and introduces a novel localization evaluation metric that considers both accuracy and efficiency. Additionally, we utilize a high-precision laser scanner to acquire ground truth maps of two representative scenes, facilitating the development and evaluation of mapping algorithms. We select 12 localization sequences and 2 mapping sequences to evaluate several classical SLAM algorithms, verifying usability of the dataset. To enhance usability, the dataset is accompanied by a suite of development kits.
Will Large Language Models be a Panacea to Autonomous Driving?
Sep 24, 2024



Artificial intelligence (AI) plays a crucial role in autonomous driving (AD) research, propelling its development towards intelligence and efficiency. Currently, the development of AD technology follows two main technical paths: modularization and end-to-end. Modularization decompose the driving task into modules such as perception, prediction, planning, and control, and train them separately. Due to the inconsistency of training objectives between modules, the integrated effect suffers from bias. End-to-end attempts to address this issue by utilizing a single model that directly maps from sensor data to control signals. This path has limited learning capabilities in a comprehensive set of features and struggles to handle unpredictable long-tail events and complex urban traffic scenarios. In the face of challenges encountered in both paths, many researchers believe that large language models (LLMs) with powerful reasoning capabilities and extensive knowledge understanding may be the solution, expecting LLMs to provide AD systems with deeper levels of understanding and decision-making capabilities. In light of the challenges faced by both paths, many researchers believe that LLMs, with their powerful reasoning abilities and extensive knowledge, could offer a solution. To understand if LLMs could enhance AD, this paper conducts a thorough analysis of the potential applications of LLMs in AD systems, including exploring their optimization strategies in both modular and end-to-end approaches, with a particular focus on how LLMs can tackle the problems and challenges present in current solutions. Furthermore, we discuss an important question: Can LLM-based artificial general intelligence (AGI) be a key to achieve high-level AD? We further analyze the potential limitations and challenges that LLMs may encounter in promoting the development of AD technology.
Coupling AI and Citizen Science in Creation of Enhanced Training Dataset for Medical Image Segmentation
Sep 04, 2024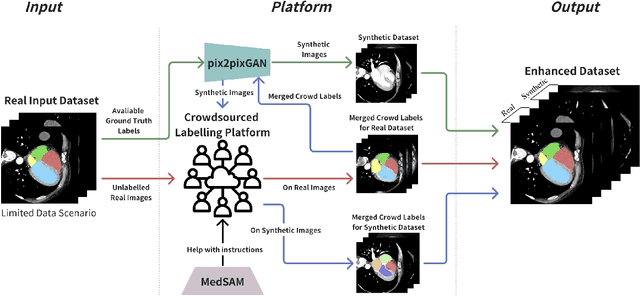
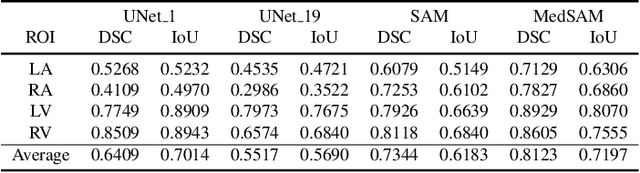
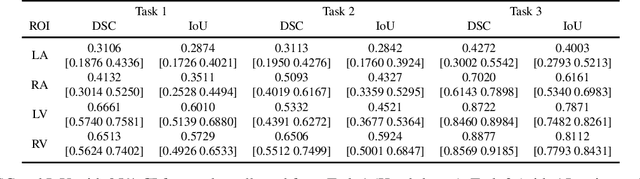
Recent advancements in medical imaging and artificial intelligence (AI) have greatly enhanced diagnostic capabilities, but the development of effective deep learning (DL) models is still constrained by the lack of high-quality annotated datasets. The traditional manual annotation process by medical experts is time- and resource-intensive, limiting the scalability of these datasets. In this work, we introduce a robust and versatile framework that combines AI and crowdsourcing to improve both the quality and quantity of medical image datasets across different modalities. Our approach utilises a user-friendly online platform that enables a diverse group of crowd annotators to label medical images efficiently. By integrating the MedSAM segmentation AI with this platform, we accelerate the annotation process while maintaining expert-level quality through an algorithm that merges crowd-labelled images. Additionally, we employ pix2pixGAN, a generative AI model, to expand the training dataset with synthetic images that capture realistic morphological features. These methods are combined into a cohesive framework designed to produce an enhanced dataset, which can serve as a universal pre-processing pipeline to boost the training of any medical deep learning segmentation model. Our results demonstrate that this framework significantly improves model performance, especially when training data is limited.
Probing Perfection: The Relentless Art of Meddling for Pulmonary Airway Segmentation from HRCT via a Human-AI Collaboration Based Active Learning Method
Jul 03, 2024
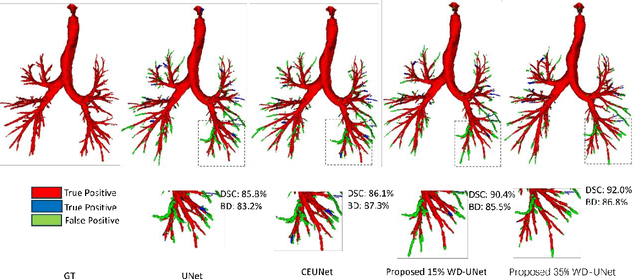


In pulmonary tracheal segmentation, the scarcity of annotated data is a prevalent issue in medical segmentation. Additionally, Deep Learning (DL) methods face challenges: the opacity of 'black box' models and the need for performance enhancement. Our Human-Computer Interaction (HCI) based models (RS_UNet, LC_UNet, UUNet, and WD_UNet) address these challenges by combining diverse query strategies with various DL models. We train four HCI models and repeat these steps: (1) Query Strategy: The HCI models select samples that provide the most additional representative information when labeled in each iteration and identify unlabeled samples with the greatest predictive disparity using Wasserstein Distance, Least Confidence, Entropy Sampling, and Random Sampling. (2) Central line correction: Selected samples are used for expert correction of system-generated tracheal central lines in each training round. (3) Update training dataset: Experts update the training dataset after each DL model's training epoch, enhancing the trustworthiness and performance of the models. (4) Model training: The HCI model is trained using the updated dataset and an enhanced UNet version. Experimental results confirm the effectiveness of these HCI-based approaches, showing that WD-UNet, LC-UNet, UUNet, and RS-UNet achieve comparable or superior performance to state-of-the-art DL models. Notably, WD-UNet achieves this with only 15%-35% of the training data, reducing physician annotation time by 65%-85%.
Fuzzy Attention-based Border Rendering Network for Lung Organ Segmentation
Jun 23, 2024



Automatic lung organ segmentation on CT images is crucial for lung disease diagnosis. However, the unlimited voxel values and class imbalance of lung organs can lead to false-negative/positive and leakage issues in advanced methods. Additionally, some slender lung organs are easily lost during the recycled down/up-sample procedure, e.g., bronchioles & arterioles, causing severe discontinuity issue. Inspired by these, this paper introduces an effective lung organ segmentation method called Fuzzy Attention-based Border Rendering (FABR) network. Since fuzzy logic can handle the uncertainty in feature extraction, hence the fusion of deep networks and fuzzy sets should be a viable solution for better performance. Meanwhile, unlike prior top-tier methods that operate on all regular dense points, our FABR depicts lung organ regions as cube-trees, focusing only on recycle-sampled border vulnerable points, rendering the severely discontinuous, false-negative/positive organ regions with a novel Global-Local Cube-tree Fusion (GLCF) module. All experimental results, on four challenging datasets of airway & artery, demonstrate that our method can achieve the favorable performance significantly.