 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Fairness amid Social Determinants: Reflection, Characterization, and Approach
Aug 10, 2025



Social determinants are variables that, while not directly pertaining to any specific individual, capture key aspects of contexts and environments that have direct causal influences on certain attributes of an individual. Previous algorithmic fairness literature has primarily focused on sensitive attributes, often overlooking the role of social determinants. Our paper addresses this gap by introducing formal and quantitative rigor into a space that has been shaped largely by qualitative proposals regarding the use of social determinants. To demonstrate theoretical perspectives and practical applicability, we examine a concrete setting of college admissions, using region as a proxy for social determinants. Our approach leverages a region-based analysis with Gamma distribution parameterization to model how social determinants impact individual outcomes. Despite its simplicity, our method quantitatively recovers findings that resonate with nuanced insights in previous qualitative debates, that are often missed by existing algorithmic fairness approaches. Our findings suggest that mitigation strategies centering solely around sensitive attributes may introduce new structural injustice when addressing existing discrimination. Considering both sensitive attributes and social determinants facilitates a more comprehensive explication of benefits and burdens experienced by individuals from diverse demographic backgrounds as well as contextual environments, which is essential for understanding and achieving fairness effectively and transparently.
SmartCLIP: Modular Vision-language Alignment with Identification Guarantees
Jul 29, 2025
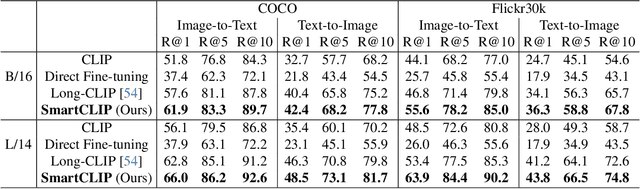
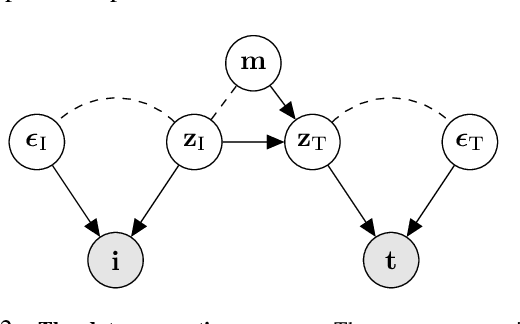
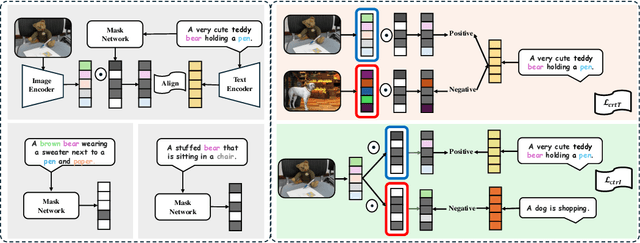
Contrastive Language-Image Pre-training (CLIP)~\citep{radford2021learning} has emerged as a pivotal model in computer vision and multimodal learning, achieving state-of-the-art performance at aligning visual and textual representations through contrastive learning. However, CLIP struggles with potential information misalignment in many image-text datasets and suffers from entangled representation. On the one hand, short captions for a single image in datasets like MSCOCO may describe disjoint regions in the image, leaving the model uncertain about which visual features to retain or disregard. On the other hand, directly aligning long captions with images can lead to the retention of entangled details, preventing the model from learning disentangled, atomic concepts -- ultimately limiting its generalization on certain downstream tasks involving short prompts. In this paper, we establish theoretical conditions that enable flexible alignment between textual and visual representations across varying levels of granularity. Specifically, our framework ensures that a model can not only \emph{preserve} cross-modal semantic information in its entirety but also \emph{disentangle} visual representations to capture fine-grained textual concepts. Building on this foundation, we introduce \ours, a novel approach that identifies and aligns the most relevant visual and textual representations in a modular manner. Superior performance across various tasks demonstrates its capability to handle information misalignment and supports our identification theory. The code is available at https://github.com/Mid-Push/SmartCLIP.
Should Bias Always be Eliminated? A Principled Framework to Use Data Bias for OOD Generation
Jul 22, 2025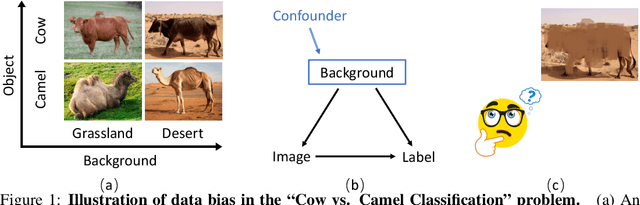
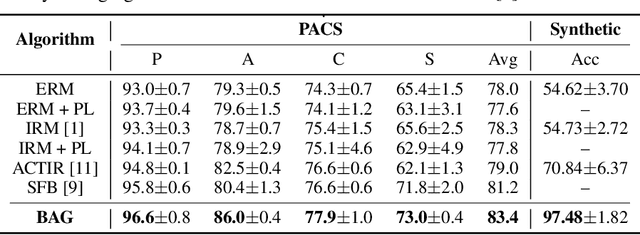
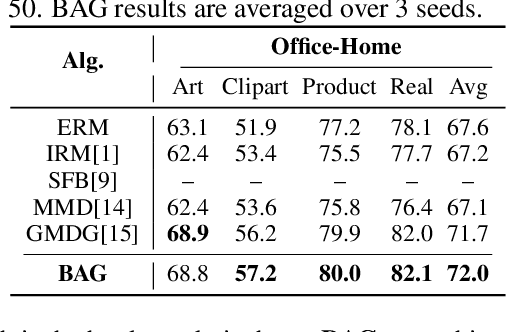
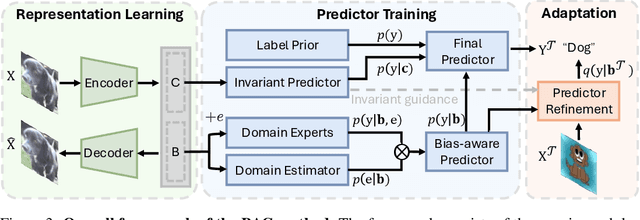
Most existing methods for adapting models to out-of-distribution (OOD) domains rely on invariant representation learning to eliminate the influence of biased features. However, should bias always be eliminated -- and if not, when should it be retained, and how can it be leveraged? To address these questions, we first present a theoretical analysis that explores the conditions under which biased features can be identified and effectively utilized. Building on this theoretical foundation, we introduce a novel framework that strategically leverages bias to complement invariant representations during inference. The framework comprises two key components that leverage bias in both direct and indirect ways: (1) using invariance as guidance to extract predictive ingredients from bias, and (2) exploiting identified bias to estimate the environmental condition and then use it to explore appropriate bias-aware predictors to alleviate environment gaps. We validate our approach through experiments on both synthetic datasets and standard domain generalization benchmarks. Results consistently demonstrate that our method outperforms existing approaches, underscoring its robustness and adaptability.
Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs
May 26, 2025Sparse Autoencoders (SAEs) are a prominent tool in mechanistic interpretability (MI) for decomposing neural network activations into interpretable features. However, the aspiration to identify a canonical set of features is challenged by the observed inconsistency of learned SAE features across different training runs, undermining the reliability and efficiency of MI research. This position paper argues that mechanistic interpretability should prioritize feature consistency in SAEs -- the reliable convergence to equivalent feature sets across independent runs. We propose using the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) as a practical metric to operationalize consistency and demonstrate that high levels are achievable (0.80 for TopK SAEs on LLM activations) with appropriate architectural choices. Our contributions include detailing the benefits of prioritizing consistency; providing theoretical grounding and synthetic validation using a model organism, which verifies PW-MCC as a reliable proxy for ground-truth recovery; and extending these findings to real-world LLM data, where high feature consistency strongly correlates with the semantic similarity of learned feature explanations. We call for a community-wide shift towards systematically measuring feature consistency to foster robust cumulative progress in MI.
When Selection Meets Intervention: Additional Complexities in Causal Discovery
Mar 10, 2025We address the common yet often-overlooked selection bias in interventional studies, where subjects are selectively enrolled into experiments. For instance, participants in a drug trial are usually patients of the relevant disease; A/B tests on mobile applications target existing users only, and gene perturbation studies typically focus on specific cell types, such as cancer cells. Ignoring this bias leads to incorrect causal discovery results. Even when recognized, the existing paradigm for interventional causal discovery still fails to address it. This is because subtle differences in when and where interventions happen can lead to significantly different statistical patterns. We capture this dynamic by introducing a graphical model that explicitly accounts for both the observed world (where interventions are applied) and the counterfactual world (where selection occurs while interventions have not been applied). We characterize the Markov property of the model, and propose a provably sound algorithm to identify causal relations as well as selection mechanisms up to the equivalence class, from data with soft interventions and unknown targets. Through synthetic and real-world experiments, we demonstrate that our algorithm effectively identifies true causal relations despite the presence of selection bias.
* Appears at ICLR 2025 (oral)
Reflection-Window Decoding: Text Generation with Selective Refinement
Feb 05, 2025



The autoregressive decoding for text generation in large language models (LLMs), while widely used, is inherently suboptimal due to the lack of a built-in mechanism to perform refinement and/or correction of the generated content. In this paper, we consider optimality in terms of the joint probability over the generated response, when jointly considering all tokens at the same time. We theoretically characterize the potential deviation of the autoregressively generated response from its globally optimal counterpart that is of the same length. Our analysis suggests that we need to be cautious when noticeable uncertainty arises during text generation, which may signal the sub-optimality of the generation history. To address the pitfall of autoregressive decoding for text generation, we propose an approach that incorporates a sliding reflection window and a pausing criterion, such that refinement and generation can be carried out interchangeably as the decoding proceeds. Our selective refinement framework strikes a balance between efficiency and optimality, and our extensive experimental results demonstrate the effectiveness of our approach.
Controllable Video Generation with Provable Disentanglement
Feb 04, 2025



Controllable video generation remains a significant challenge, despite recent advances in generating high-quality and consistent videos. Most existing methods for controlling video generation treat the video as a whole, neglecting intricate fine-grained spatiotemporal relationships, which limits both control precision and efficiency. In this paper, we propose Controllable Video Generative Adversarial Networks (CoVoGAN) to disentangle the video concepts, thus facilitating efficient and independent control over individual concepts. Specifically, following the minimal change principle, we first disentangle static and dynamic latent variables. We then leverage the sufficient change property to achieve component-wise identifiability of dynamic latent variables, enabling independent control over motion and identity. To establish the theoretical foundation, we provide a rigorous analysis demonstrating the identifiability of our approach. Building on these theoretical insights, we design a Temporal Transition Module to disentangle latent dynamics. To enforce the minimal change principle and sufficient change property, we minimize the dimensionality of latent dynamic variables and impose temporal conditional independence. To validate our approach, we integrate this module as a plug-in for GANs. Extensive qualitative and quantitative experiments on various video generation benchmarks demonstrate that our method significantly improves generation quality and controllability across diverse real-world scenarios.
From Challenges and Pitfalls to Recommendations and Opportunities: Implementing Federated Learning in Healthcare
Sep 15, 2024
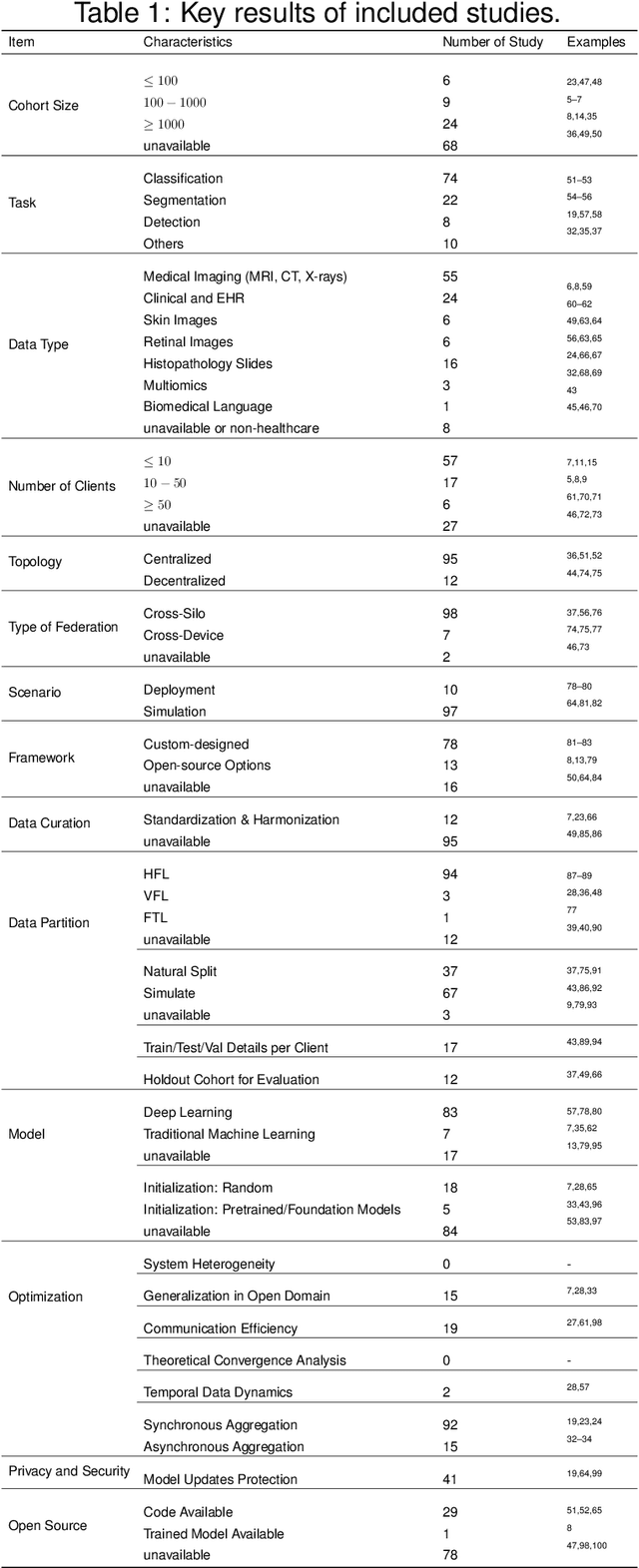
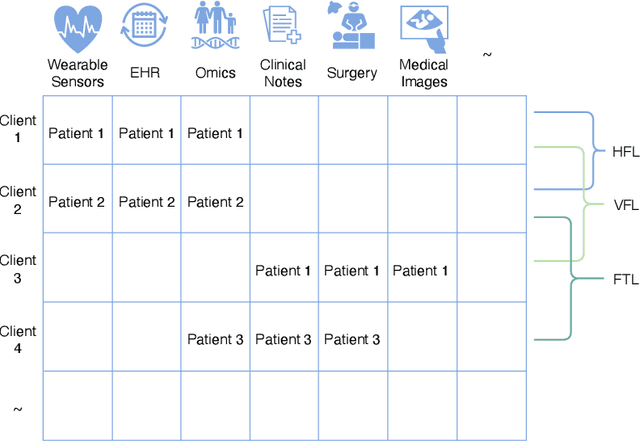

Federated learning holds great potential for enabling large-scale healthcare research and collaboration across multiple centres while ensuring data privacy and security are not compromised. Although numerous recent studies suggest or utilize federated learning based methods in healthcare, it remains unclear which ones have potential clinical utility. This review paper considers and analyzes the most recent studies up to May 2024 that describe federated learning based methods in healthcare. After a thorough review, we find that the vast majority are not appropriate for clinical use due to their methodological flaws and/or underlying biases which include but are not limited to privacy concerns, generalization issues, and communication costs. As a result, the effectiveness of federated learning in healthcare is significantly compromised. To overcome these challenges, we provide recommendations and promising opportunities that might be implemented to resolve these problems and improve the quality of model development in federated learning with healthcare.
Detecting and Identifying Selection Structure in Sequential Data
Jun 29, 2024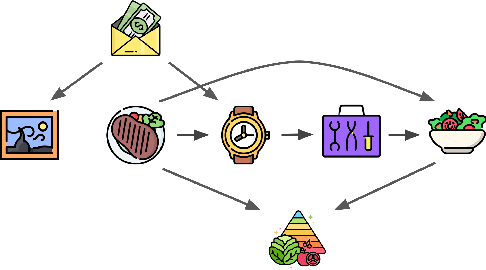
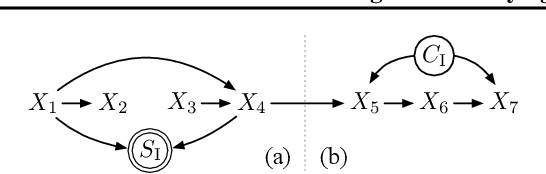
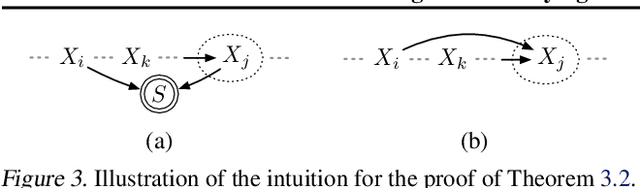
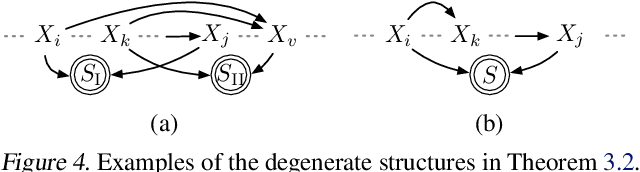
We argue that the selective inclusion of data points based on latent objectives is common in practical situations, such as music sequences. Since this selection process often distorts statistical analysis, previous work primarily views it as a bias to be corrected and proposes various methods to mitigate its effect. However, while controlling this bias is crucial, selection also offers an opportunity to provide a deeper insight into the hidden generation process, as it is a fundamental mechanism underlying what we observe. In particular, overlooking selection in sequential data can lead to an incomplete or overcomplicated inductive bias in modeling, such as assuming a universal autoregressive structure for all dependencies. Therefore, rather than merely viewing it as a bias, we explore the causal structure of selection in sequential data to delve deeper into the complete causal process. Specifically, we show that selection structure is identifiable without any parametric assumptions or interventional experiments. Moreover, even in cases where selection variables coexist with latent confounders, we still establish the nonparametric identifiability under appropriate structural conditions. Meanwhile, we also propose a provably correct algorithm to detect and identify selection structures as well as other types of dependencies. The framework has been validated empirically on both synthetic data and real-world music.
Long-Term Fairness Inquiries and Pursuits in Machine Learning: A Survey of Notions, Methods, and Challenges
Jun 10, 2024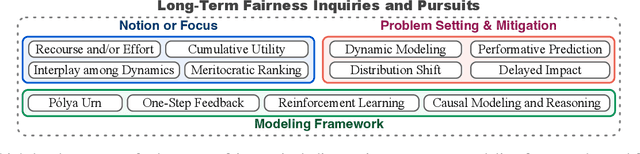

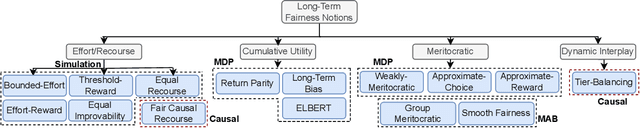

The widespread integration of Machine Learning systems in daily life, particularly in high-stakes domains, has raised concerns about the fairness implications. While prior works have investigated static fairness measures, recent studies reveal that automated decision-making has long-term implications and that off-the-shelf fairness approaches may not serve the purpose of achieving long-term fairness. Additionally, the existence of feedback loops and the interaction between models and the environment introduces additional complexities that may deviate from the initial fairness goals. In this survey, we review existing literature on long-term fairness from different perspectives and present a taxonomy for long-term fairness studies. We highlight key challenges and consider future research directions, analyzing both current issues and potential further explorations.