 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Selection Meets Intervention: Additional Complexities in Causal Discovery
Mar 10, 2025We address the common yet often-overlooked selection bias in interventional studies, where subjects are selectively enrolled into experiments. For instance, participants in a drug trial are usually patients of the relevant disease; A/B tests on mobile applications target existing users only, and gene perturbation studies typically focus on specific cell types, such as cancer cells. Ignoring this bias leads to incorrect causal discovery results. Even when recognized, the existing paradigm for interventional causal discovery still fails to address it. This is because subtle differences in when and where interventions happen can lead to significantly different statistical patterns. We capture this dynamic by introducing a graphical model that explicitly accounts for both the observed world (where interventions are applied) and the counterfactual world (where selection occurs while interventions have not been applied). We characterize the Markov property of the model, and propose a provably sound algorithm to identify causal relations as well as selection mechanisms up to the equivalence class, from data with soft interventions and unknown targets. Through synthetic and real-world experiments, we demonstrate that our algorithm effectively identifies true causal relations despite the presence of selection bias.
* Appears at ICLR 2025 (oral)
Causal Representation Learning from Multimodal Biological Observations
Nov 10, 2024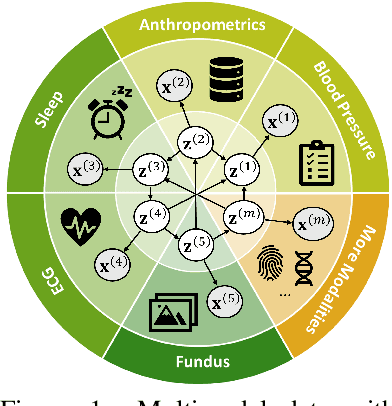

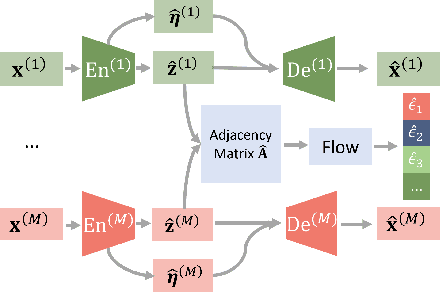
Prevalent in biological applications (e.g., human phenotype measurements), multimodal datasets can provide valuable insights into the underlying biological mechanisms. However, current machine learning models designed to analyze such datasets still lack interpretability and theoretical guarantees, which are essential to biological applications. Recent advances in causal representation learning have shown promise in uncovering the interpretable latent causal variables with formal theoretical certificates. Unfortunately, existing works for multimodal distributions either rely on restrictive parametric assumptions or provide rather coarse identification results, limiting their applicability to biological research which favors a detailed understanding of the mechanisms. In this work, we aim to develop flexible identification conditions for multimodal data and principled methods to facilitate the understanding of biological datasets. Theoretically, we consider a flexible nonparametric latent distribution (c.f., parametric assumptions in prior work) permitting causal relationships across potentially different modalities. We establish identifiability guarantees for each latent component, extending the subspace identification results from prior work. Our key theoretical ingredient is the structural sparsity of the causal connections among distinct modalities, which, as we will discuss, is natural for a large collection of biological systems. Empirically, we propose a practical framework to instantiate our theoretical insights. We demonstrate the effectiveness of our approach through extensive experiments on both numerical and synthetic datasets. Results on a real-world human phenotype dataset are consistent with established medical research, validating our theoretical and methodological framework.
Gene Regulatory Network Inference in the Presence of Dropouts: a Causal View
Mar 21, 2024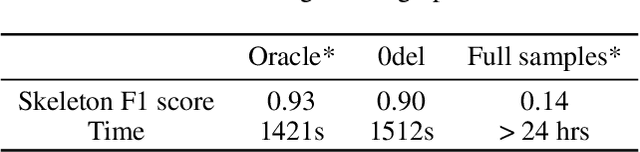
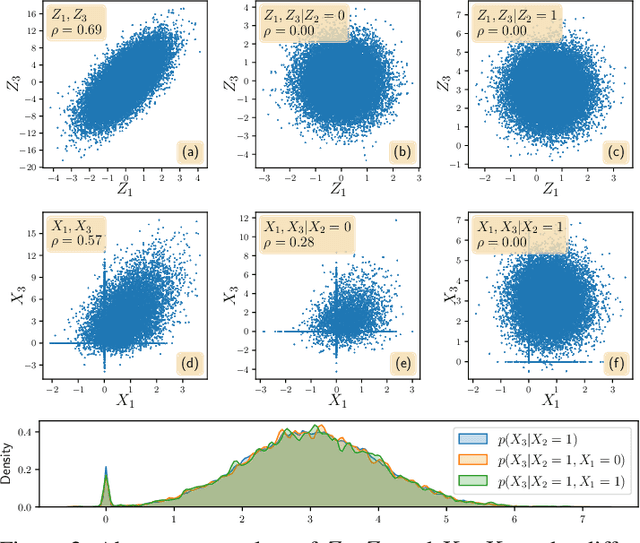
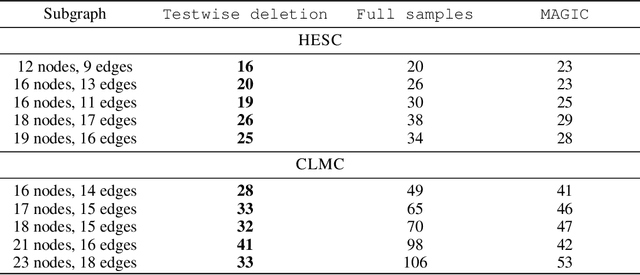
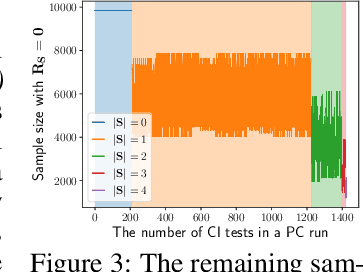
Gene regulatory network inference (GRNI) is a challenging problem, particularly owing to the presence of zeros in single-cell RNA sequencing data: some are biological zeros representing no gene expression, while some others are technical zeros arising from the sequencing procedure (aka dropouts), which may bias GRNI by distorting the joint distribution of the measured gene expressions. Existing approaches typically handle dropout error via imputation, which may introduce spurious relations as the true joint distribution is generally unidentifiable. To tackle this issue, we introduce a causal graphical model to characterize the dropout mechanism, namely, Causal Dropout Model. We provide a simple yet effective theoretical result: interestingly, the conditional independence (CI) relations in the data with dropouts, after deleting the samples with zero values (regardless if technical or not) for the conditioned variables, are asymptotically identical to the CI relations in the original data without dropouts. This particular test-wise deletion procedure, in which we perform CI tests on the samples without zeros for the conditioned variables, can be seamlessly integrated with existing structure learning approaches including constraint-based and greedy score-based methods, thus giving rise to a principled framework for GRNI in the presence of dropouts. We further show that the causal dropout model can be validated from data, and many existing statistical models to handle dropouts fit into our model as specific parametric instances. Empirical evaluation on synthetic, curated, and real-world experimental transcriptomic data comprehensively demonstrate the efficacy of our method.
Federated Causal Discovery from Heterogeneous Data
Feb 27, 2024



Conventional causal discovery methods rely on centralized data, which is inconsistent with the decentralized nature of data in many real-world situations. This discrepancy has motivated the development of federated causal discovery (FCD) approaches. However, existing FCD methods may be limited by their potentially restrictive assumptions of identifiable functional causal models or homogeneous data distributions, narrowing their applicability in diverse scenarios. In this paper, we propose a novel FCD method attempting to accommodate arbitrary causal models and heterogeneous data. We first utilize a surrogate variable corresponding to the client index to account for the data heterogeneity across different clients. We then develop a federated conditional independence test (FCIT) for causal skeleton discovery and establish a federated independent change principle (FICP) to determine causal directions. These approaches involve constructing summary statistics as a proxy of the raw data to protect data privacy. Owing to the nonparametric properties, FCIT and FICP make no assumption about particular functional forms, thereby facilitating the handling of arbitrary causal models. We conduct extensive experiments on synthetic and real datasets to show the efficacy of our method. The code is available at https://github.com/lokali/FedCDH.git.
Improving Zero-shot Multilingual Neural Machine Translation for Low-Resource Languages
Oct 02, 2021


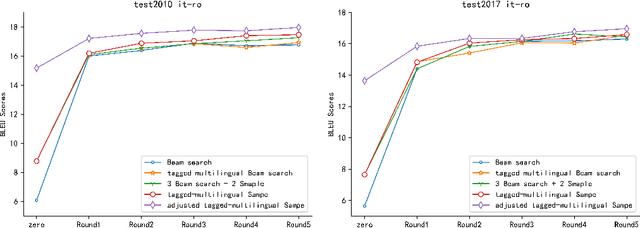
Although the multilingual Neural Machine Translation(NMT), which extends Google's multilingual NMT, has ability to perform zero-shot translation and the iterative self-learning algorithm can improve the quality of zero-shot translation, it confronts with two problems: the multilingual NMT model is prone to generate wrong target language when implementing zero-shot translation; the self-learning algorithm, which uses beam search to generate synthetic parallel data, demolishes the diversity of the generated source language and amplifies the impact of the same noise during the iterative learning process. In this paper, we propose the tagged-multilingual NMT model and improve the self-learning algorithm to handle these two problems. Firstly, we extend the Google's multilingual NMT model and add target tokens to the target languages, which associates the start tag with the target language to ensure that the source language can be translated to the required target language. Secondly, we improve the self-learning algorithm by replacing beam search with random sample to increases the diversity of the generated data and makes it properly cover the true data distribution. Experimental results on IWSLT show that the adjusted tagged-multilingual NMT separately obtains 9.41 and 7.85 BLEU scores over the multilingual NMT on 2010 and 2017 Romanian-Italian test sets. Similarly, it obtains 9.08 and 7.99 BLEU scores on Italian-Romanian zero-shot translation. Furthermore, the improved self-learning algorithm shows its superiorities over the conventional self-learning algorithm on zero-shot translations.
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
May 24, 2021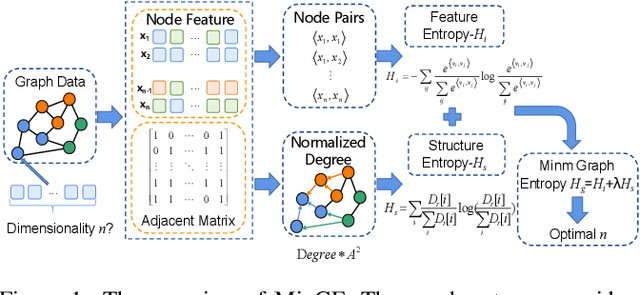

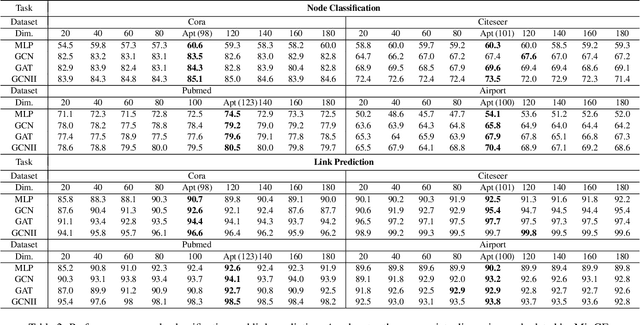
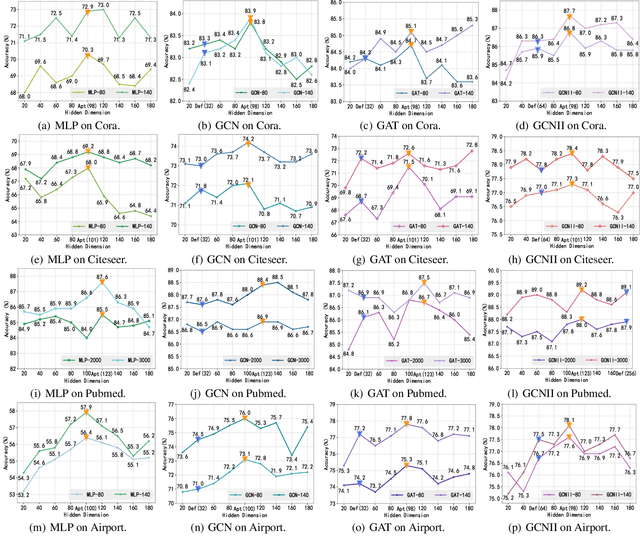
Graph representation learning has achieved great success in many areas, including e-commerce, chemistry, biology, etc. However, the fundamental problem of choosing the appropriate dimension of node embedding for a given graph still remains unsolved. The commonly used strategies for Node Embedding Dimension Selection (NEDS) based on grid search or empirical knowledge suffer from heavy computation and poor model performance. In this paper, we revisit NEDS from the perspective of minimum entropy principle. Subsequently, we propose a novel Minimum Graph Entropy (MinGE) algorithm for NEDS with graph data. To be specific, MinGE considers both feature entropy and structure entropy on graphs, which are carefully designed according to the characteristics of the rich information in them. The feature entropy, which assumes the embeddings of adjacent nodes to be more similar, connects node features and link topology on graphs. The structure entropy takes the normalized degree as basic unit to further measure the higher-order structure of graphs. Based on them, we design MinGE to directly calculate the ideal node embedding dimension for any graph. Finally, comprehensive experiments with popular Graph Neural Networks (GNNs) on benchmark datasets demonstrate the effectiveness and generalizability of our proposed MinGE.