 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry
Apr 02, 2026General-purpose world models promise scalable policy evaluation, optimization, and planning, yet achieving the required level of robustness remains challenging. Unlike policy learning, which primarily focuses on optimal actions, a world model must be reliable over a much broader range of suboptimal actions, which are often insufficiently covered by action-labeled interaction data. To address this challenge, we propose World Action Verifier (WAV), a framework that enables world models to identify their own prediction errors and self-improve. The key idea is to decompose action-conditioned state prediction into two factors -- state plausibility and action reachability -- and verify each separately. We show that these verification problems can be substantially easier than predicting future states due to two underlying asymmetries: the broader availability of action-free data and the lower dimensionality of action-relevant features. Leveraging these asymmetries, we augment a world model with (i) a diverse subgoal generator obtained from video corpora and (ii) a sparse inverse model that infers actions from a subset of state features. By enforcing cycle consistency among generated subgoals, inferred actions, and forward rollouts, WAV provides an effective verification mechanism in under-explored regimes, where existing methods typically fail. Across nine tasks spanning MiniGrid, RoboMimic, and ManiSkill, our method achieves 2x higher sample efficiency while improving downstream policy performance by 18%.
Learning by Analogy: A Causal Framework for Composition Generalization
Dec 11, 2025Compositional generalization -- the ability to understand and generate novel combinations of learned concepts -- enables models to extend their capabilities beyond limited experiences. While effective, the data structures and principles that enable this crucial capability remain poorly understood. We propose that compositional generalization fundamentally requires decomposing high-level concepts into basic, low-level concepts that can be recombined across similar contexts, similar to how humans draw analogies between concepts. For example, someone who has never seen a peacock eating rice can envision this scene by relating it to their previous observations of a chicken eating rice. In this work, we formalize these intuitive processes using principles of causal modularity and minimal changes. We introduce a hierarchical data-generating process that naturally encodes different levels of concepts and their interaction mechanisms. Theoretically, we demonstrate that this approach enables compositional generalization supporting complex relations between composed concepts, advancing beyond prior work that assumes simpler interactions like additive effects. Critically, we also prove that this latent hierarchical structure is provably recoverable (identifiable) from observable data like text-image pairs, a necessary step for learning such a generative process. To validate our theory, we apply insights from our theoretical framework and achieve significant improvements on benchmark datasets.
Beyond the Black Box: Identifiable Interpretation and Control in Generative Models via Causal Minimality
Dec 11, 2025Deep generative models, while revolutionizing fields like image and text generation, largely operate as opaque black boxes, hindering human understanding, control, and alignment. While methods like sparse autoencoders (SAEs) show remarkable empirical success, they often lack theoretical guarantees, risking subjective insights. Our primary objective is to establish a principled foundation for interpretable generative models. We demonstrate that the principle of causal minimality -- favoring the simplest causal explanation -- can endow the latent representations of diffusion vision and autoregressive language models with clear causal interpretation and robust, component-wise identifiable control. We introduce a novel theoretical framework for hierarchical selection models, where higher-level concepts emerge from the constrained composition of lower-level variables, better capturing the complex dependencies in data generation. Under theoretically derived minimality conditions (manifesting as sparsity or compression constraints), we show that learned representations can be equivalent to the true latent variables of the data-generating process. Empirically, applying these constraints to leading generative models allows us to extract their innate hierarchical concept graphs, offering fresh insights into their internal knowledge organization. Furthermore, these causally grounded concepts serve as levers for fine-grained model steering, paving the way for transparent, reliable systems.
Step-Aware Policy Optimization for Reasoning in Diffusion Large Language Models
Oct 02, 2025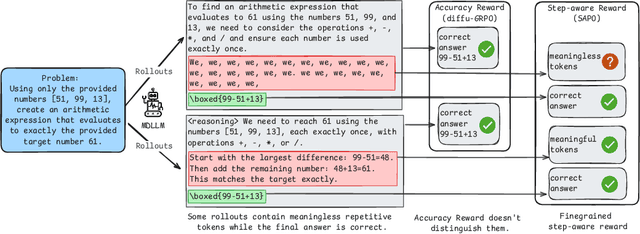
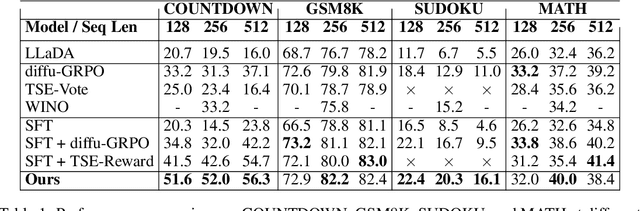
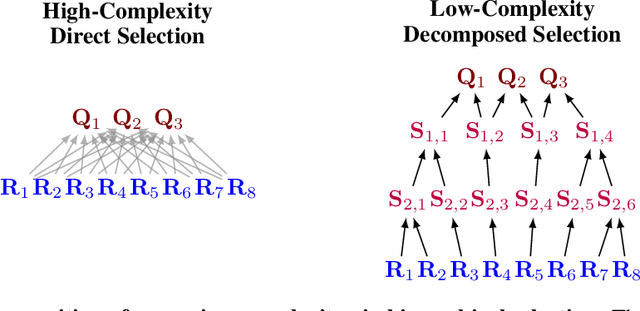
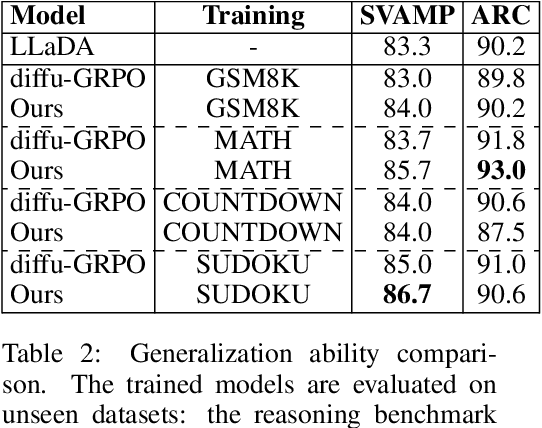
Diffusion language models (dLLMs) offer a promising, non-autoregressive paradigm for text generation, yet training them for complex reasoning remains a key challenge. Current reinforcement learning approaches often rely on sparse, outcome-based rewards, which can reinforce flawed reasoning paths that lead to coincidentally correct answers. We argue that this stems from a fundamental mismatch with the natural structure of reasoning. We first propose a theoretical framework that formalizes complex problem solving as a hierarchical selection process, where an intractable global constraint is decomposed into a series of simpler, localized logical steps. This framework provides a principled foundation for algorithm design, including theoretical insights into the identifiability of this latent reasoning structure. Motivated by this theory, we identify unstructured refinement -- a failure mode where a model's iterative steps do not contribute meaningfully to the solution -- as a core deficiency in existing methods. We then introduce Step-Aware Policy Optimization (SAPO), a novel RL algorithm that aligns the dLLM's denoising process with the latent reasoning hierarchy. By using a process-based reward function that encourages incremental progress, SAPO guides the model to learn structured, coherent reasoning paths. Our empirical results show that this principled approach significantly improves performance on challenging reasoning benchmarks and enhances the interpretability of the generation process.
SmartCLIP: Modular Vision-language Alignment with Identification Guarantees
Jul 29, 2025
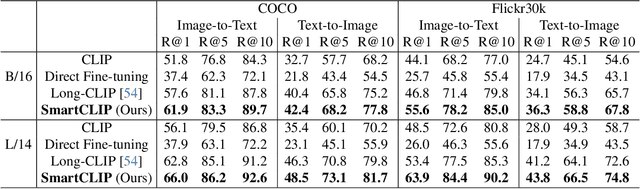
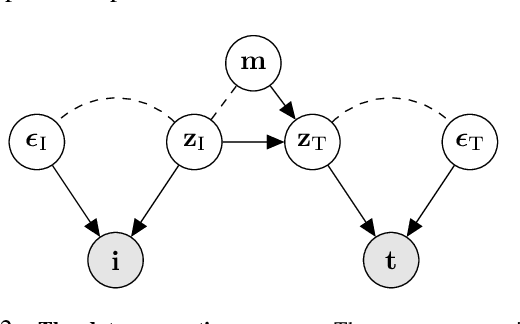
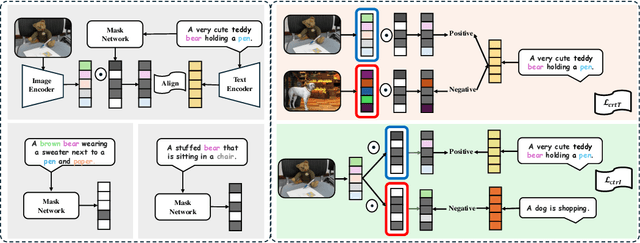
Contrastive Language-Image Pre-training (CLIP)~\citep{radford2021learning} has emerged as a pivotal model in computer vision and multimodal learning, achieving state-of-the-art performance at aligning visual and textual representations through contrastive learning. However, CLIP struggles with potential information misalignment in many image-text datasets and suffers from entangled representation. On the one hand, short captions for a single image in datasets like MSCOCO may describe disjoint regions in the image, leaving the model uncertain about which visual features to retain or disregard. On the other hand, directly aligning long captions with images can lead to the retention of entangled details, preventing the model from learning disentangled, atomic concepts -- ultimately limiting its generalization on certain downstream tasks involving short prompts. In this paper, we establish theoretical conditions that enable flexible alignment between textual and visual representations across varying levels of granularity. Specifically, our framework ensures that a model can not only \emph{preserve} cross-modal semantic information in its entirety but also \emph{disentangle} visual representations to capture fine-grained textual concepts. Building on this foundation, we introduce \ours, a novel approach that identifies and aligns the most relevant visual and textual representations in a modular manner. Superior performance across various tasks demonstrates its capability to handle information misalignment and supports our identification theory. The code is available at https://github.com/Mid-Push/SmartCLIP.
Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs
May 26, 2025Sparse Autoencoders (SAEs) are a prominent tool in mechanistic interpretability (MI) for decomposing neural network activations into interpretable features. However, the aspiration to identify a canonical set of features is challenged by the observed inconsistency of learned SAE features across different training runs, undermining the reliability and efficiency of MI research. This position paper argues that mechanistic interpretability should prioritize feature consistency in SAEs -- the reliable convergence to equivalent feature sets across independent runs. We propose using the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) as a practical metric to operationalize consistency and demonstrate that high levels are achievable (0.80 for TopK SAEs on LLM activations) with appropriate architectural choices. Our contributions include detailing the benefits of prioritizing consistency; providing theoretical grounding and synthetic validation using a model organism, which verifies PW-MCC as a reliable proxy for ground-truth recovery; and extending these findings to real-world LLM data, where high feature consistency strongly correlates with the semantic similarity of learned feature explanations. We call for a community-wide shift towards systematically measuring feature consistency to foster robust cumulative progress in MI.
Towards Understanding Extrapolation: a Causal Lens
Jan 15, 2025



Canonical work handling distribution shifts typically necessitates an entire target distribution that lands inside the training distribution. However, practical scenarios often involve only a handful of target samples, potentially lying outside the training support, which requires the capability of extrapolation. In this work, we aim to provide a theoretical understanding of when extrapolation is possible and offer principled methods to achieve it without requiring an on-support target distribution. To this end, we formulate the extrapolation problem with a latent-variable model that embodies the minimal change principle in causal mechanisms. Under this formulation, we cast the extrapolation problem into a latent-variable identification problem. We provide realistic conditions on shift properties and the estimation objectives that lead to identification even when only one off-support target sample is available, tackling the most challenging scenarios. Our theory reveals the intricate interplay between the underlying manifold's smoothness and the shift properties. We showcase how our theoretical results inform the design of practical adaptation algorithms. Through experiments on both synthetic and real-world data, we validate our theoretical findings and their practical implications.
Causal Representation Learning from Multimodal Biological Observations
Nov 10, 2024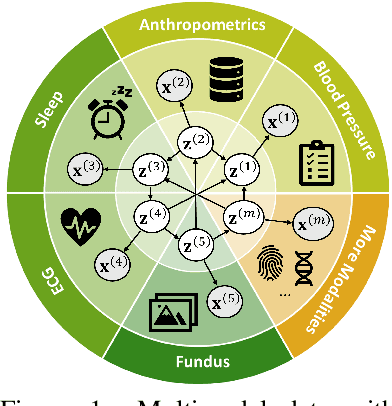

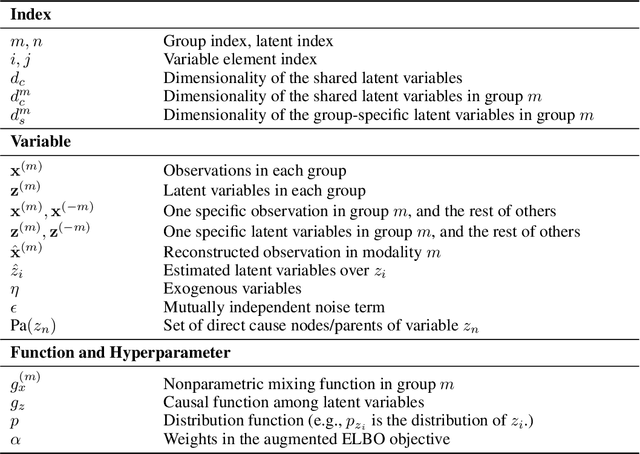
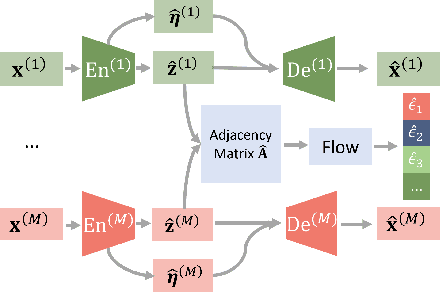
Prevalent in biological applications (e.g., human phenotype measurements), multimodal datasets can provide valuable insights into the underlying biological mechanisms. However, current machine learning models designed to analyze such datasets still lack interpretability and theoretical guarantees, which are essential to biological applications. Recent advances in causal representation learning have shown promise in uncovering the interpretable latent causal variables with formal theoretical certificates. Unfortunately, existing works for multimodal distributions either rely on restrictive parametric assumptions or provide rather coarse identification results, limiting their applicability to biological research which favors a detailed understanding of the mechanisms. In this work, we aim to develop flexible identification conditions for multimodal data and principled methods to facilitate the understanding of biological datasets. Theoretically, we consider a flexible nonparametric latent distribution (c.f., parametric assumptions in prior work) permitting causal relationships across potentially different modalities. We establish identifiability guarantees for each latent component, extending the subspace identification results from prior work. Our key theoretical ingredient is the structural sparsity of the causal connections among distinct modalities, which, as we will discuss, is natural for a large collection of biological systems. Empirically, we propose a practical framework to instantiate our theoretical insights. We demonstrate the effectiveness of our approach through extensive experiments on both numerical and synthetic datasets. Results on a real-world human phenotype dataset are consistent with established medical research, validating our theoretical and methodological framework.
Adjusting Pretrained Backbones for Performativity
Oct 06, 2024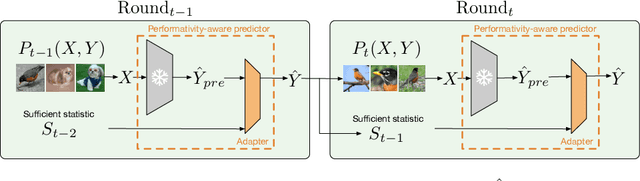



With the widespread deployment of deep learning models, they influence their environment in various ways. The induced distribution shifts can lead to unexpected performance degradation in deployed models. Existing methods to anticipate performativity typically incorporate information about the deployed model into the feature vector when predicting future outcomes. While enjoying appealing theoretical properties, modifying the input dimension of the prediction task is often not practical. To address this, we propose a novel technique to adjust pretrained backbones for performativity in a modular way, achieving better sample efficiency and enabling the reuse of existing deep learning assets. Focusing on performative label shift, the key idea is to train a shallow adapter module to perform a Bayes-optimal label shift correction to the backbone's logits given a sufficient statistic of the model to be deployed. As such, our framework decouples the construction of input-specific feature embeddings from the mechanism governing performativity. Motivated by dynamic benchmarking as a use-case, we evaluate our approach under adversarial sampling, for vision and language tasks. We show how it leads to smaller loss along the retraining trajectory and enables us to effectively select among candidate models to anticipate performance degradations. More broadly, our work provides a first baseline for addressing performativity in deep learning.
Learning Discrete Concepts in Latent Hierarchical Models
Jun 01, 2024



Learning concepts from natural high-dimensional data (e.g., images) holds potential in building human-aligned and interpretable machine learning models. Despite its encouraging prospect, formalization and theoretical insights into this crucial task are still lacking. In this work, we formalize concepts as discrete latent causal variables that are related via a hierarchical causal model that encodes different abstraction levels of concepts embedded in high-dimensional data (e.g., a dog breed and its eye shapes in natural images). We formulate conditions to facilitate the identification of the proposed causal model, which reveals when learning such concepts from unsupervised data is possible. Our conditions permit complex causal hierarchical structures beyond latent trees and multi-level directed acyclic graphs in prior work and can handle high-dimensional, continuous observed variables, which is well-suited for unstructured data modalities such as images. We substantiate our theoretical claims with synthetic data experiments. Further, we discuss our theory's implications for understanding the underlying mechanisms of latent diffusion models and provide corresponding empirical evidence for our theoretical insights.