 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjusting Pretrained Backbones for Performativity
Paper and Code
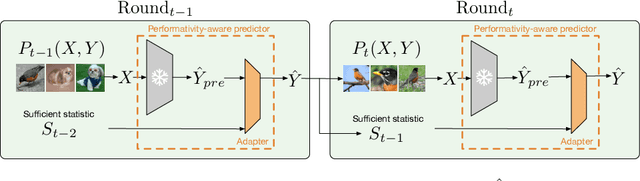



With the widespread deployment of deep learning models, they influence their environment in various ways. The induced distribution shifts can lead to unexpected performance degradation in deployed models. Existing methods to anticipate performativity typically incorporate information about the deployed model into the feature vector when predicting future outcomes. While enjoying appealing theoretical properties, modifying the input dimension of the prediction task is often not practical. To address this, we propose a novel technique to adjust pretrained backbones for performativity in a modular way, achieving better sample efficiency and enabling the reuse of existing deep learning assets. Focusing on performative label shift, the key idea is to train a shallow adapter module to perform a Bayes-optimal label shift correction to the backbone's logits given a sufficient statistic of the model to be deployed. As such, our framework decouples the construction of input-specific feature embeddings from the mechanism governing performativity. Motivated by dynamic benchmarking as a use-case, we evaluate our approach under adversarial sampling, for vision and language tasks. We show how it leads to smaller loss along the retraining trajectory and enables us to effectively select among candidate models to anticipate performance degradations. More broadly, our work provides a first baseline for addressing performativity in deep learning.