 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Sample Quality in Conditional Generation under Compositional Shift
Jun 09, 2026Conditional generators provide a natural tool for controllable generation, including settings where the desired condition is a new composition of observed attributes or experimental factors. In many applications, especially in scientific domains, such models are attractive to explore conditions for which real samples are rare, expensive, or not yet observed. However, this creates a circularity for evaluation: standard conditional quality metrics require a reference target distribution, but in the extrapolative regime that distribution is unavailable by definition. We address this problem with a post-hoc, per-sample trust score for assessing conditional samples using only the training distribution. The score combines two estimable quantities: global realism, measuring compatibility with the real data manifold, and attribute-wise faithfulness, measuring whether a sample is closer to the requested attributes than to plausible alternatives. We show that the score can recover meaningful comparisons across extrapolated generations, under a mild coverage condition on the observed attributes. These comparisons enable effective filtering, ranking, and abstention of generations and can be used directly on off-the-shelf pretrained models. In biological imaging, selected samples preserve real morphological structure better and improve downstream predictive performance, while similar gains are observed on controlled vision benchmarks. Finally, we show how the score can be applied during generation, enabling abstention before full decoding. Code is available at https://github.com/berkerdemirel/faithful-cond-gen.
Look Around and Find Out: OOD Detection with Relative Angles
Oct 06, 2024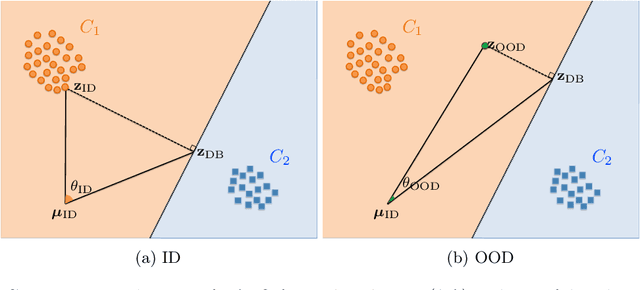
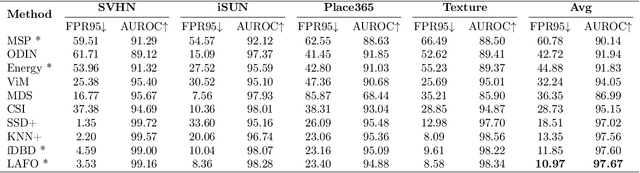
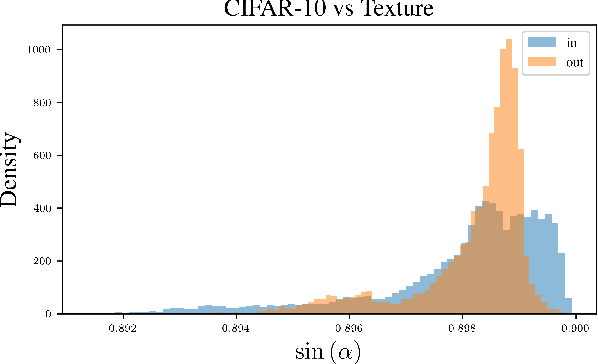
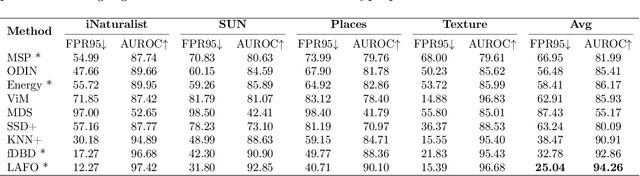
Deep learning systems deployed in real-world applications often encounter data that is different from their in-distribution (ID). A reliable system should ideally abstain from making decisions in this out-of-distribution (OOD) setting. Existing state-of-the-art methods primarily focus on feature distances, such as k-th nearest neighbors and distances to decision boundaries, either overlooking or ineffectively using in-distribution statistics. In this work, we propose a novel angle-based metric for OOD detection that is computed relative to the in-distribution structure. We demonstrate that the angles between feature representations and decision boundaries, viewed from the mean of in-distribution features, serve as an effective discriminative factor between ID and OOD data. Our method achieves state-of-the-art performance on CIFAR-10 and ImageNet benchmarks, reducing FPR95 by 0.88% and 7.74% respectively. Our score function is compatible with existing feature space regularization techniques, enhancing performance. Additionally, its scale-invariance property enables creating an ensemble of models for OOD detection via simple score summation.
Adjusting Pretrained Backbones for Performativity
Oct 06, 2024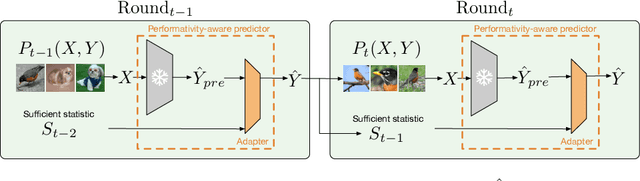



With the widespread deployment of deep learning models, they influence their environment in various ways. The induced distribution shifts can lead to unexpected performance degradation in deployed models. Existing methods to anticipate performativity typically incorporate information about the deployed model into the feature vector when predicting future outcomes. While enjoying appealing theoretical properties, modifying the input dimension of the prediction task is often not practical. To address this, we propose a novel technique to adjust pretrained backbones for performativity in a modular way, achieving better sample efficiency and enabling the reuse of existing deep learning assets. Focusing on performative label shift, the key idea is to train a shallow adapter module to perform a Bayes-optimal label shift correction to the backbone's logits given a sufficient statistic of the model to be deployed. As such, our framework decouples the construction of input-specific feature embeddings from the mechanism governing performativity. Motivated by dynamic benchmarking as a use-case, we evaluate our approach under adversarial sampling, for vision and language tasks. We show how it leads to smaller loss along the retraining trajectory and enables us to effectively select among candidate models to anticipate performance degradations. More broadly, our work provides a first baseline for addressing performativity in deep learning.
ADRMX: Additive Disentanglement of Domain Features with Remix Loss
Aug 12, 2023



The common assumption that train and test sets follow similar distributions is often violated in deployment settings. Given multiple source domains, domain generalization aims to create robust models capable of generalizing to new unseen domains. To this end, most of existing studies focus on extracting domain invariant features across the available source domains in order to mitigate the effects of inter-domain distributional changes. However, this approach may limit the model's generalization capacity by relying solely on finding common features among the source domains. It overlooks the potential presence of domain-specific characteristics that could be prevalent in a subset of domains, potentially containing valuable information. In this work, a novel architecture named Additive Disentanglement of Domain Features with Remix Loss (ADRMX) is presented, which addresses this limitation by incorporating domain variant features together with the domain invariant ones using an original additive disentanglement strategy. Moreover, a new data augmentation technique is introduced to further support the generalization capacity of ADRMX, where samples from different domains are mixed within the latent space. Through extensive experiments conducted on DomainBed under fair conditions, ADRMX is shown to achieve state-of-the-art performance. Code will be made available at GitHub after the revision process.
DECOMPL: Decompositional Learning with Attention Pooling for Group Activity Recognition from a Single Volleyball Image
Mar 11, 2023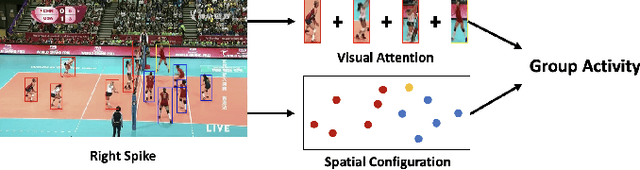
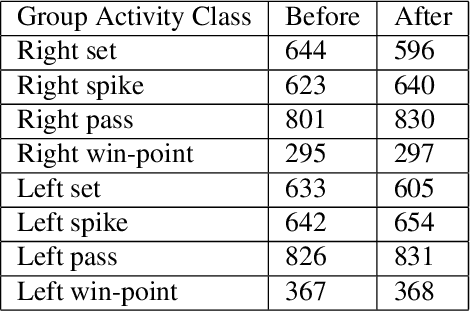
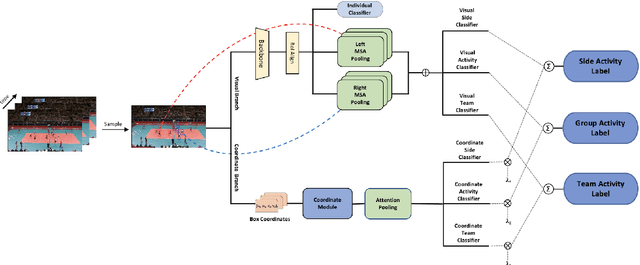
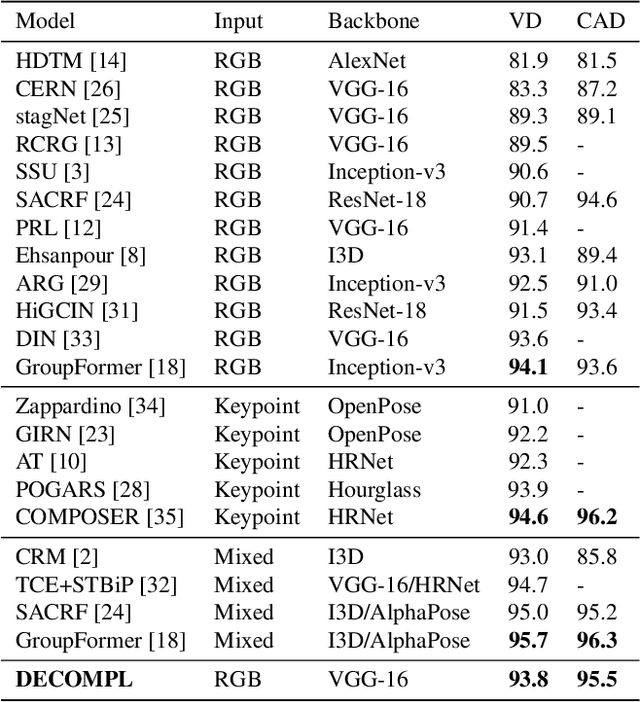
Group Activity Recognition (GAR) aims to detect the activity performed by multiple actors in a scene. Prior works model the spatio-temporal features based on the RGB, optical flow or keypoint data types. However, using both the temporality and these data types altogether increase the computational complexity significantly. Our hypothesis is that by only using the RGB data without temporality, the performance can be maintained with a negligible loss in accuracy. To that end, we propose a novel GAR technique for volleyball videos, DECOMPL, which consists of two complementary branches. In the visual branch, it extracts the features using attention pooling in a selective way. In the coordinate branch, it considers the current configuration of the actors and extracts the spatial information from the box coordinates. Moreover, we analyzed the Volleyball dataset that the recent literature is mostly based on, and realized that its labeling scheme degrades the group concept in the activities to the level of individual actors. We manually reannotated the dataset in a systematic manner for emphasizing the group concept. Experimental results on the Volleyball as well as Collective Activity (from another domain, i.e., not volleyball) datasets demonstrated the effectiveness of the proposed model DECOMPL, which delivered the best/second best GAR performance with the reannotations/original annotations among the comparable state-of-the-art techniques. Our code, results and new annotations will be made available through GitHub after the revision process.