 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Domain Generalization in Magnetic Resonance-Based Assessment of Alzheimer's Disease
Jan 04, 2026Despite progress in deep learning for Alzheimer's disease (AD) diagnostics, models trained on structural magnetic resonance imaging (sMRI) often do not perform well when applied to new cohorts due to domain shifts from varying scanners, protocols and patient demographics. AD, the primary driver of dementia, manifests through progressive cognitive and neuroanatomical changes like atrophy and ventricular expansion, making robust, generalizable classification essential for real-world use. While convolutional neural networks and transformers have advanced feature extraction via attention and fusion techniques, single-domain generalization (SDG) remains underexplored yet critical, given the fragmented nature of AD datasets. To bridge this gap, we introduce Extended MixStyle (EM), a framework for blending higher-order feature moments (skewness and kurtosis) to mimic diverse distributional variations. Trained on sMRI data from the National Alzheimer's Coordinating Center (NACC; n=4,647) to differentiate persons with normal cognition (NC) from those with mild cognitive impairment (MCI) or AD and tested on three unseen cohorts (total n=3,126), EM yields enhanced cross-domain performance, improving macro-F1 on average by 2.4 percentage points over state-of-the-art SDG benchmarks, underscoring its promise for invariant, reliable AD detection in heterogeneous real-world settings. The source code will be made available upon acceptance at https://github.com/zobia111/Extended-Mixstyle.
Single Domain Generalization for Alzheimer's Detection from 3D MRIs with Pseudo-Morphological Augmentations and Contrastive Learning
May 28, 2025Although Alzheimer's disease detection via MRIs has advanced significantly thanks to contemporary deep learning models, challenges such as class imbalance, protocol variations, and limited dataset diversity often hinder their generalization capacity. To address this issue, this article focuses on the single domain generalization setting, where given the data of one domain, a model is designed and developed with maximal performance w.r.t. an unseen domain of distinct distribution. Since brain morphology is known to play a crucial role in Alzheimer's diagnosis, we propose the use of learnable pseudo-morphological modules aimed at producing shape-aware, anatomically meaningful class-specific augmentations in combination with a supervised contrastive learning module to extract robust class-specific representations. Experiments conducted across three datasets show improved performance and generalization capacity, especially under class imbalance and imaging protocol variations. The source code will be made available upon acceptance at https://github.com/zobia111/SDG-Alzheimer.
Distance Transform Guided Mixup for Alzheimer's Detection
May 28, 2025Alzheimer's detection efforts aim to develop accurate models for early disease diagnosis. Significant advances have been achieved with convolutional neural networks and vision transformer based approaches. However, medical datasets suffer heavily from class imbalance, variations in imaging protocols, and limited dataset diversity, which hinder model generalization. To overcome these challenges, this study focuses on single-domain generalization by extending the well-known mixup method. The key idea is to compute the distance transform of MRI scans, separate them spatially into multiple layers and then combine layers stemming from distinct samples to produce augmented images. The proposed approach generates diverse data while preserving the brain's structure. Experimental results show generalization performance improvement across both ADNI and AIBL datasets.
Adapting the Biological SSVEP Response to Artificial Neural Networks
Nov 15, 2024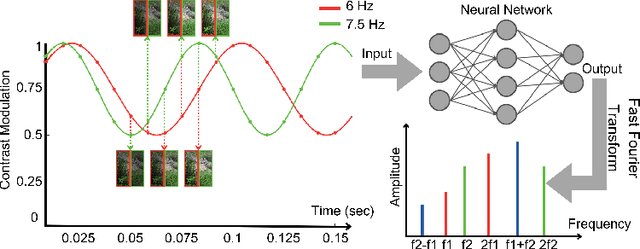
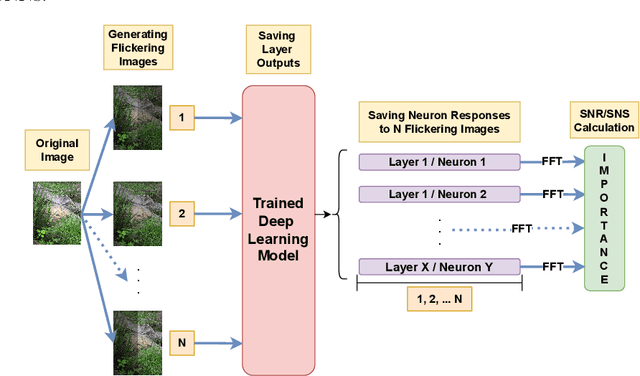
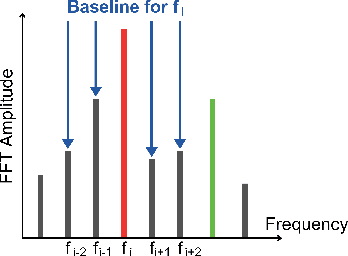
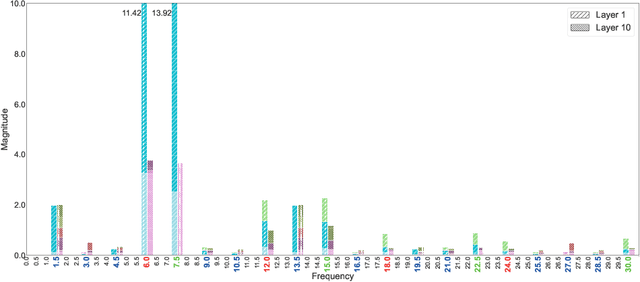
Neuron importance assessment is crucial for understanding the inner workings of artificial neural networks (ANNs) and improving their interpretability and efficiency. This paper introduces a novel approach to neuron significance assessment inspired by frequency tagging, a technique from neuroscience. By applying sinusoidal contrast modulation to image inputs and analyzing resulting neuron activations, this method enables fine-grained analysis of a network's decision-making processes. Experiments conducted with a convolutional neural network for image classification reveal notable harmonics and intermodulations in neuron-specific responses under part-based frequency tagging. These findings suggest that ANNs exhibit behavior akin to biological brains in tuning to flickering frequencies, thereby opening avenues for neuron/filter importance assessment through frequency tagging. The proposed method holds promise for applications in network pruning, and model interpretability, contributing to the advancement of explainable artificial intelligence and addressing the lack of transparency in neural networks. Future research directions include developing novel loss functions to encourage biologically plausible behavior in ANNs.
Online Learning for Autonomous Management of Intent-based 6G Networks
Jul 25, 2024
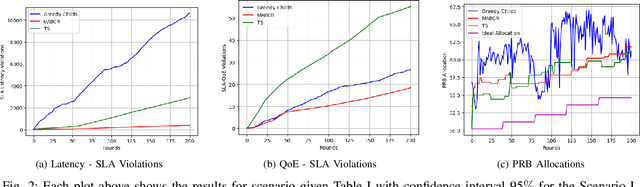
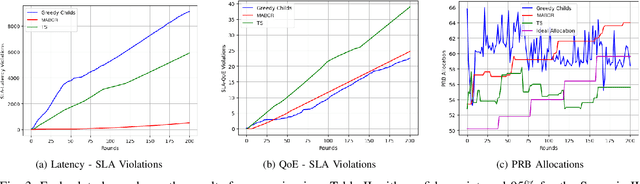
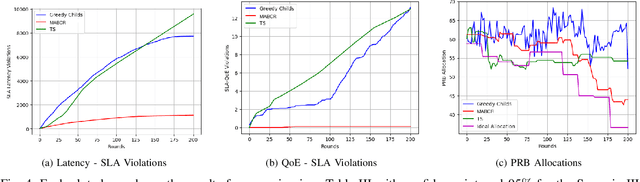
The growing complexity of networks and the variety of future scenarios with diverse and often stringent performance requirements call for a higher level of automation. Intent-based management emerges as a solution to attain high level of automation, enabling human operators to solely communicate with the network through high-level intents. The intents consist of the targets in the form of expectations (i.e., latency expectation) from a service and based on the expectations the required network configurations should be done accordingly. It is almost inevitable that when a network action is taken to fulfill one intent, it can cause negative impacts on the performance of another intent, which results in a conflict. In this paper, we aim to address the conflict issue and autonomous management of intent-based networking, and propose an online learning method based on the hierarchical multi-armed bandits approach for an effective management. Thanks to this hierarchical structure, it performs an efficient exploration and exploitation of network configurations with respect to the dynamic network conditions. We show that our algorithm is an effective approach regarding resource allocation and satisfaction of intent expectations.
ADRMX: Additive Disentanglement of Domain Features with Remix Loss
Aug 12, 2023



The common assumption that train and test sets follow similar distributions is often violated in deployment settings. Given multiple source domains, domain generalization aims to create robust models capable of generalizing to new unseen domains. To this end, most of existing studies focus on extracting domain invariant features across the available source domains in order to mitigate the effects of inter-domain distributional changes. However, this approach may limit the model's generalization capacity by relying solely on finding common features among the source domains. It overlooks the potential presence of domain-specific characteristics that could be prevalent in a subset of domains, potentially containing valuable information. In this work, a novel architecture named Additive Disentanglement of Domain Features with Remix Loss (ADRMX) is presented, which addresses this limitation by incorporating domain variant features together with the domain invariant ones using an original additive disentanglement strategy. Moreover, a new data augmentation technique is introduced to further support the generalization capacity of ADRMX, where samples from different domains are mixed within the latent space. Through extensive experiments conducted on DomainBed under fair conditions, ADRMX is shown to achieve state-of-the-art performance. Code will be made available at GitHub after the revision process.
Source Free Domain Adaptation of a DNN for SSVEP-based Brain-Computer Interfaces
May 27, 2023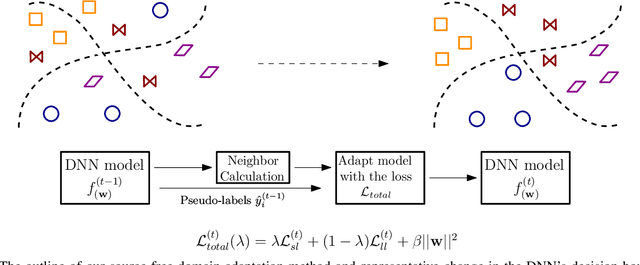
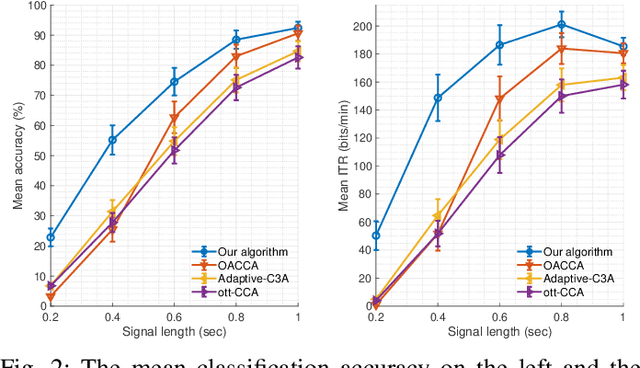
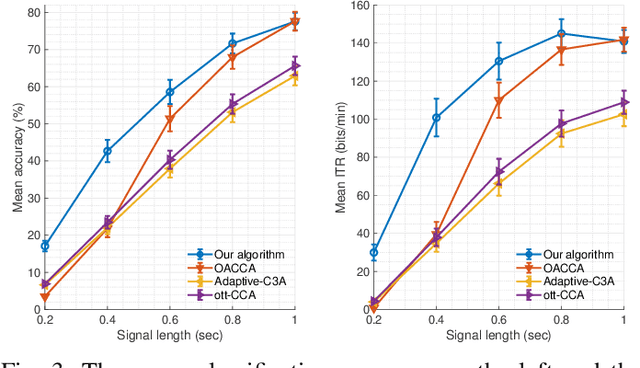
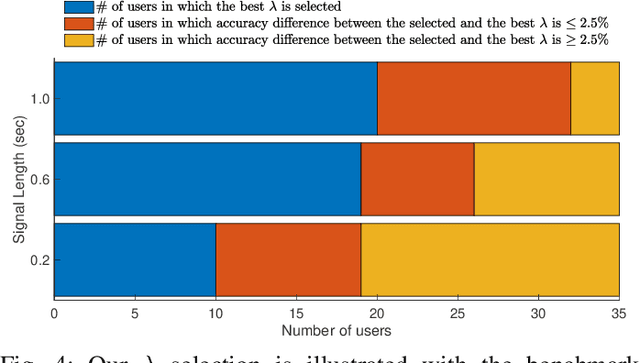
This paper presents a source free domain adaptation method for steady-state visually evoked potential (SSVEP) based brain-computer interface (BCI) spellers. SSVEP-based BCI spellers help individuals experiencing speech difficulties, enabling them to communicate at a fast rate. However, achieving a high information transfer rate (ITR) in the current methods requires an extensive calibration period before using the system, leading to discomfort for new users. We address this issue by proposing a method that adapts the deep neural network (DNN) pre-trained on data from source domains (participants of previous experiments conducted for labeled data collection), using only the unlabeled data of the new user (target domain). This adaptation is achieved by minimizing our proposed custom loss function composed of self-adaptation and local-regularity loss terms. The self-adaptation term uses the pseudo-label strategy, while the novel local-regularity term exploits the data structure and forces the DNN to assign the same labels to adjacent instances. Our method achieves striking 201.15 bits/min and 145.02 bits/min ITRs on the benchmark and BETA datasets, respectively, and outperforms the state-of-the-art alternative techniques. Our approach alleviates user discomfort and shows excellent identification performance, so it would potentially contribute to the broader application of SSVEP-based BCI systems in everyday life.
DECOMPL: Decompositional Learning with Attention Pooling for Group Activity Recognition from a Single Volleyball Image
Mar 11, 2023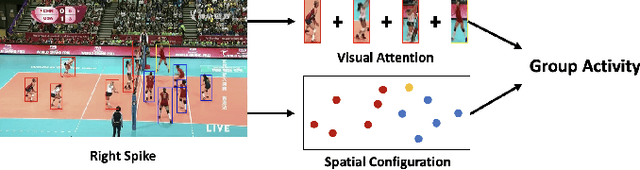
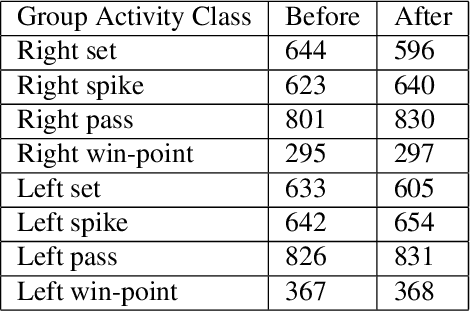
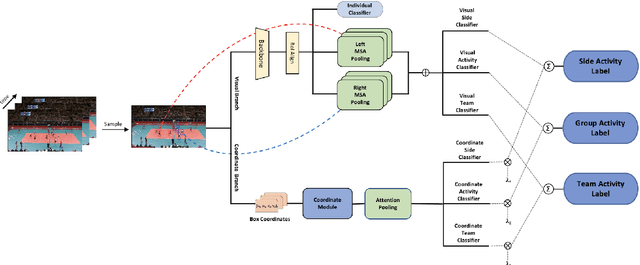
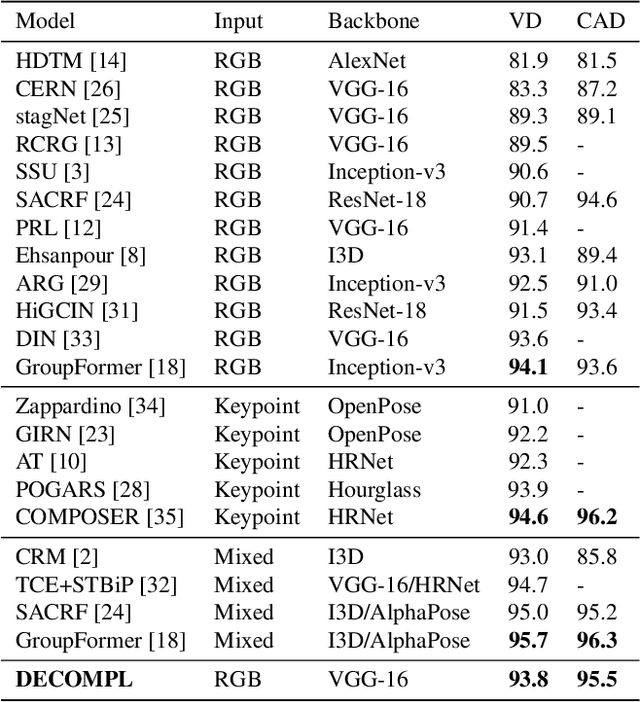
Group Activity Recognition (GAR) aims to detect the activity performed by multiple actors in a scene. Prior works model the spatio-temporal features based on the RGB, optical flow or keypoint data types. However, using both the temporality and these data types altogether increase the computational complexity significantly. Our hypothesis is that by only using the RGB data without temporality, the performance can be maintained with a negligible loss in accuracy. To that end, we propose a novel GAR technique for volleyball videos, DECOMPL, which consists of two complementary branches. In the visual branch, it extracts the features using attention pooling in a selective way. In the coordinate branch, it considers the current configuration of the actors and extracts the spatial information from the box coordinates. Moreover, we analyzed the Volleyball dataset that the recent literature is mostly based on, and realized that its labeling scheme degrades the group concept in the activities to the level of individual actors. We manually reannotated the dataset in a systematic manner for emphasizing the group concept. Experimental results on the Volleyball as well as Collective Activity (from another domain, i.e., not volleyball) datasets demonstrated the effectiveness of the proposed model DECOMPL, which delivered the best/second best GAR performance with the reannotations/original annotations among the comparable state-of-the-art techniques. Our code, results and new annotations will be made available through GitHub after the revision process.
Transfer Learning of an Ensemble of DNNs for SSVEP BCI Spellers without User-Specific Training
Sep 03, 2022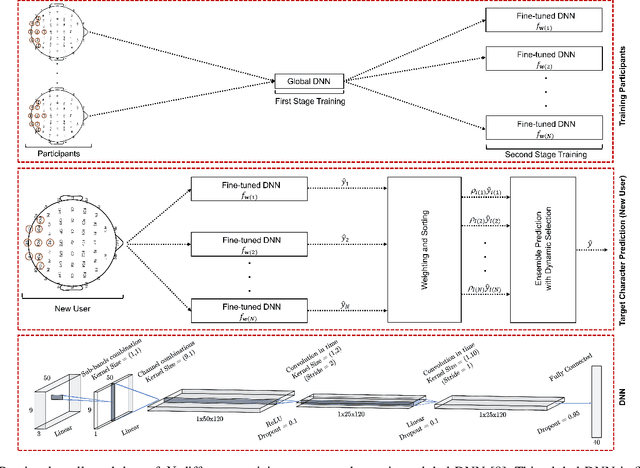
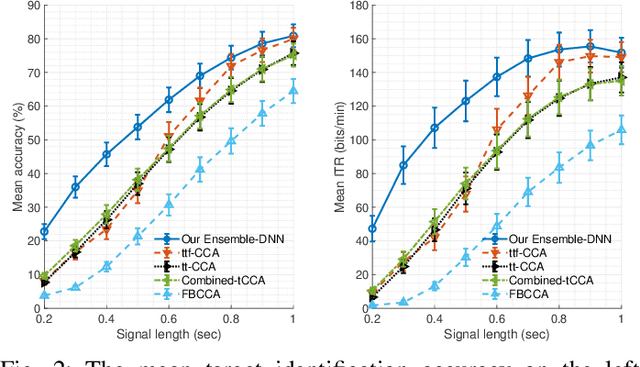
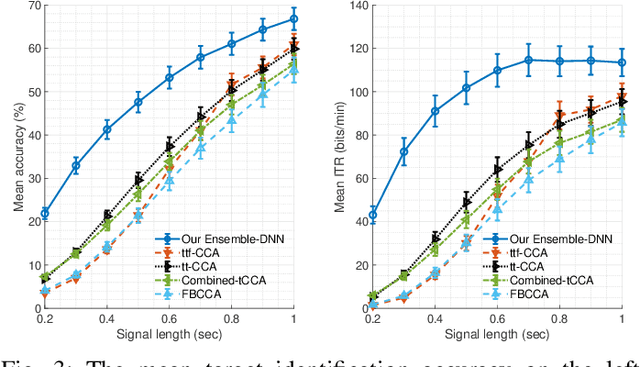

Objective: Steady-state visually evoked potentials (SSVEPs), measured with EEG (electroencephalogram), yield decent information transfer rates (ITR) in brain-computer interface (BCI) spellers. However, the current high performing SSVEP BCI spellers in the literature require an initial lengthy and tiring user-specific training for each new user for system adaptation, including data collection with EEG experiments, algorithm training and calibration (all are before the actual use of the system). This impedes the widespread use of BCIs. To ensure practicality, we propose a highly novel target identification method based on an ensemble of deep neural networks (DNNs), which does not require any sort of user-specific training. Method: We exploit already-existing literature datasets from participants of previously conducted EEG experiments to train a global target identifier DNN first, which is then fine-tuned to each participant. We transfer this ensemble of fine-tuned DNNs to the new user instance, determine the k most representative DNNs according to the participants' statistical similarities to the new user, and predict the target character through a weighted combination of the ensemble predictions. Results: On two large-scale benchmark and BETA datasets, our method achieves impressive 155.51 bits/min and 114.64 bits/min ITRs. Code is available for reproducibility: https://github.com/osmanberke/Ensemble-of-DNNs Conclusion: The proposed method significantly outperforms all the state-of-the-art alternatives for all stimulation durations in [0.2-1.0] seconds on both datasets. Significance: Our Ensemble-DNN method has the potential to promote the practical widespread deployment of BCI spellers in daily lives as we provide the highest performance while enabling the immediate system use without any user-specific training.
A Deep Neural Network for SSVEP-based Brain-Computer Interfaces
Dec 03, 2020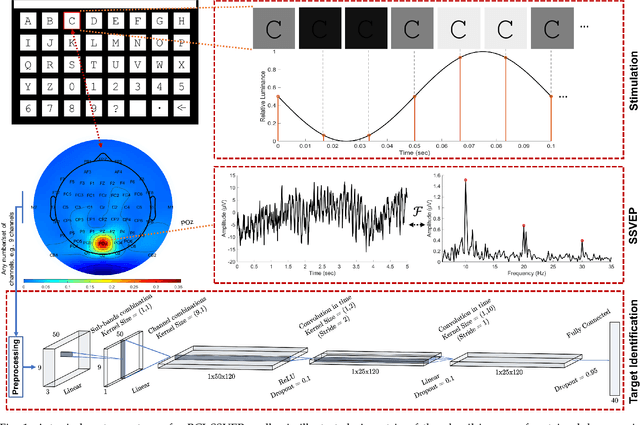
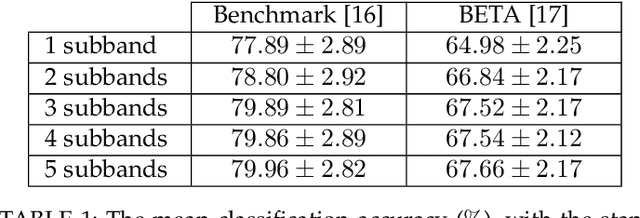

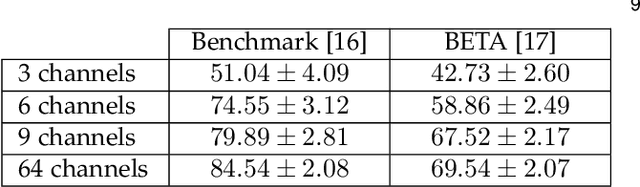
Target identification in brain-computer interface (BCI) spellers refers to the electroencephalogram (EEG) classification for predicting the target character that the subject intends to spell. When the visual stimulus of each character is tagged with a distinct frequency, the EEG records steady-state visually evoked potentials (SSVEP) whose spectrum is dominated by the harmonics of the target frequency. In this setting, we address the target identification and propose a novel deep neural network (DNN) architecture. The proposed DNN processes the multi-channel SSVEP with convolutions across the sub-bands of harmonics, channels, time, and classifies at the fully connected layer. We test with two publicly available large scale (the benchmark and BETA) datasets consisting of in total 105 subjects with 40 characters. Our first stage training learns a global model by exploiting the statistical commonalities among all subjects, and the second stage fine tunes to each subject separately by exploiting the individualities. Our DNN strongly outperforms the state-of-the-art on both datasets, by achieving impressive information transfer rates 265.23 bits/min and 196.59 bits/min, respectively, with only 0.4 seconds of stimulation. To our best knowledge, our rates are the highest ever reported performance results on these datasets. The code is available for reproducibility at https://github.com/osmanberke/Deep-SSVEP-BCI.