 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
A Deep Neural Network for SSVEP-based Brain-Computer Interfaces
Dec 03, 2020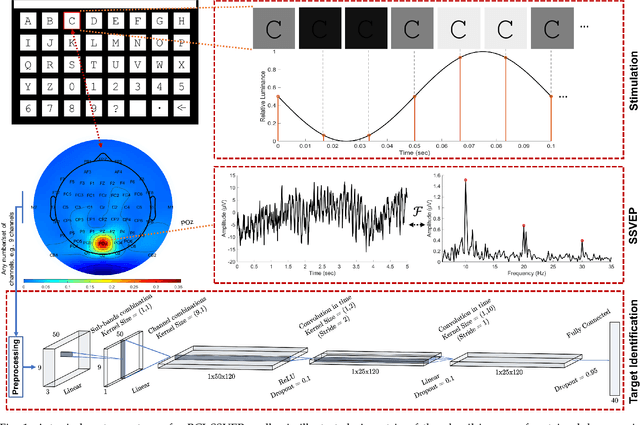
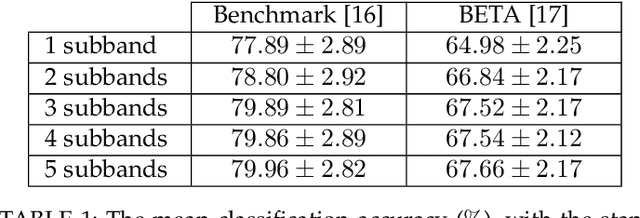

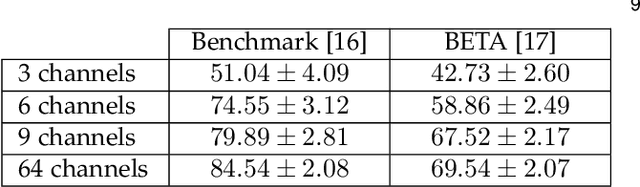
Target identification in brain-computer interface (BCI) spellers refers to the electroencephalogram (EEG) classification for predicting the target character that the subject intends to spell. When the visual stimulus of each character is tagged with a distinct frequency, the EEG records steady-state visually evoked potentials (SSVEP) whose spectrum is dominated by the harmonics of the target frequency. In this setting, we address the target identification and propose a novel deep neural network (DNN) architecture. The proposed DNN processes the multi-channel SSVEP with convolutions across the sub-bands of harmonics, channels, time, and classifies at the fully connected layer. We test with two publicly available large scale (the benchmark and BETA) datasets consisting of in total 105 subjects with 40 characters. Our first stage training learns a global model by exploiting the statistical commonalities among all subjects, and the second stage fine tunes to each subject separately by exploiting the individualities. Our DNN strongly outperforms the state-of-the-art on both datasets, by achieving impressive information transfer rates 265.23 bits/min and 196.59 bits/min, respectively, with only 0.4 seconds of stimulation. To our best knowledge, our rates are the highest ever reported performance results on these datasets. The code is available for reproducibility at https://github.com/osmanberke/Deep-SSVEP-BCI.