 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Free Domain Adaptation of a DNN for SSVEP-based Brain-Computer Interfaces
May 27, 2023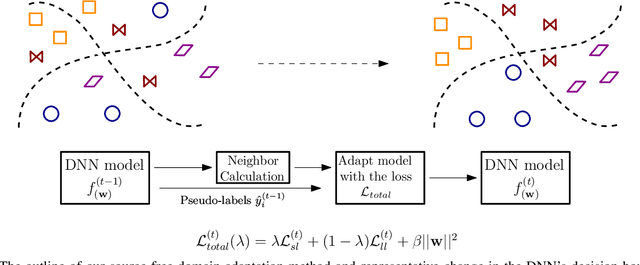
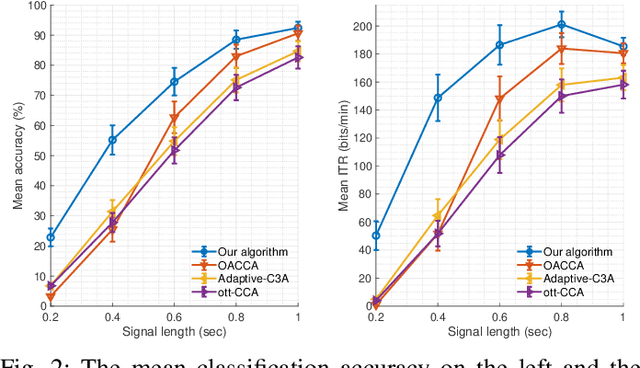
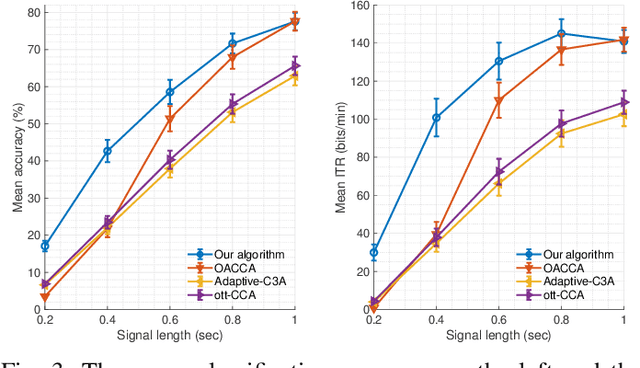
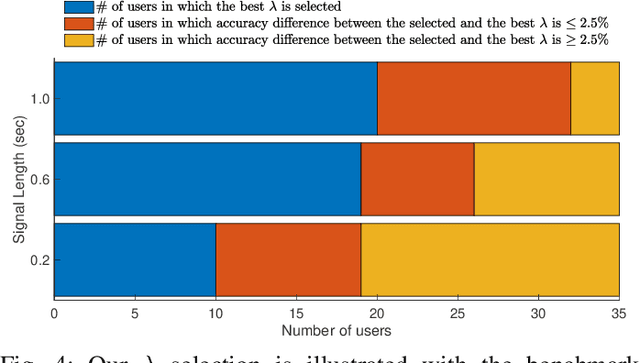
This paper presents a source free domain adaptation method for steady-state visually evoked potential (SSVEP) based brain-computer interface (BCI) spellers. SSVEP-based BCI spellers help individuals experiencing speech difficulties, enabling them to communicate at a fast rate. However, achieving a high information transfer rate (ITR) in the current methods requires an extensive calibration period before using the system, leading to discomfort for new users. We address this issue by proposing a method that adapts the deep neural network (DNN) pre-trained on data from source domains (participants of previous experiments conducted for labeled data collection), using only the unlabeled data of the new user (target domain). This adaptation is achieved by minimizing our proposed custom loss function composed of self-adaptation and local-regularity loss terms. The self-adaptation term uses the pseudo-label strategy, while the novel local-regularity term exploits the data structure and forces the DNN to assign the same labels to adjacent instances. Our method achieves striking 201.15 bits/min and 145.02 bits/min ITRs on the benchmark and BETA datasets, respectively, and outperforms the state-of-the-art alternative techniques. Our approach alleviates user discomfort and shows excellent identification performance, so it would potentially contribute to the broader application of SSVEP-based BCI systems in everyday life.
Transfer Learning of an Ensemble of DNNs for SSVEP BCI Spellers without User-Specific Training
Sep 03, 2022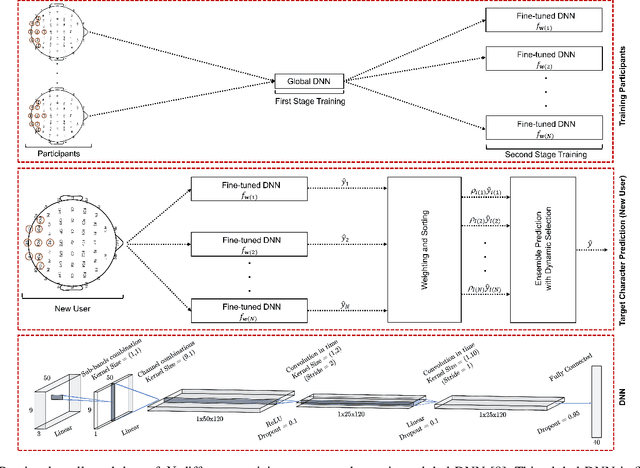
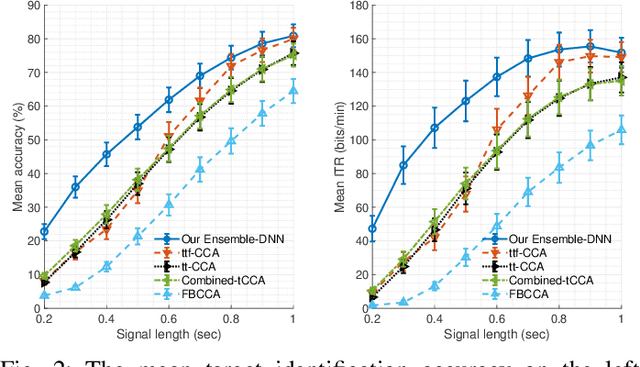
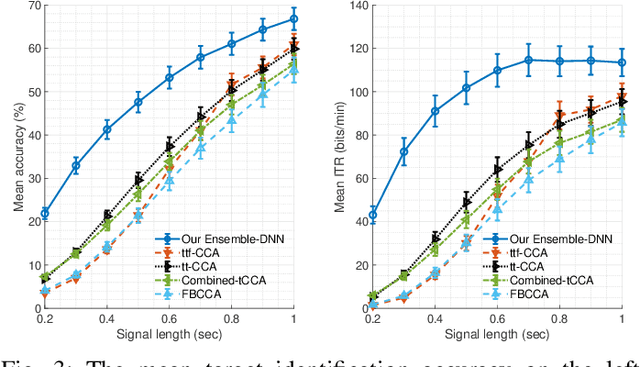

Objective: Steady-state visually evoked potentials (SSVEPs), measured with EEG (electroencephalogram), yield decent information transfer rates (ITR) in brain-computer interface (BCI) spellers. However, the current high performing SSVEP BCI spellers in the literature require an initial lengthy and tiring user-specific training for each new user for system adaptation, including data collection with EEG experiments, algorithm training and calibration (all are before the actual use of the system). This impedes the widespread use of BCIs. To ensure practicality, we propose a highly novel target identification method based on an ensemble of deep neural networks (DNNs), which does not require any sort of user-specific training. Method: We exploit already-existing literature datasets from participants of previously conducted EEG experiments to train a global target identifier DNN first, which is then fine-tuned to each participant. We transfer this ensemble of fine-tuned DNNs to the new user instance, determine the k most representative DNNs according to the participants' statistical similarities to the new user, and predict the target character through a weighted combination of the ensemble predictions. Results: On two large-scale benchmark and BETA datasets, our method achieves impressive 155.51 bits/min and 114.64 bits/min ITRs. Code is available for reproducibility: https://github.com/osmanberke/Ensemble-of-DNNs Conclusion: The proposed method significantly outperforms all the state-of-the-art alternatives for all stimulation durations in [0.2-1.0] seconds on both datasets. Significance: Our Ensemble-DNN method has the potential to promote the practical widespread deployment of BCI spellers in daily lives as we provide the highest performance while enabling the immediate system use without any user-specific training.
A Deep Neural Network for SSVEP-based Brain-Computer Interfaces
Dec 03, 2020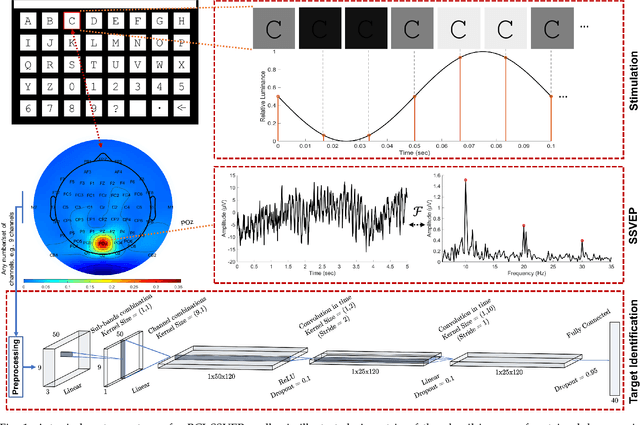
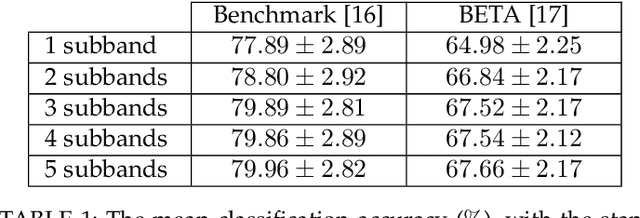

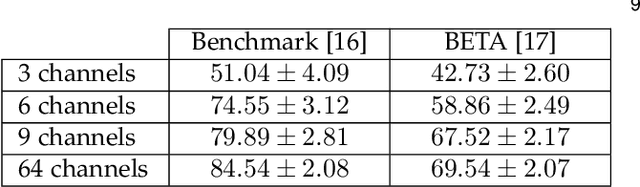
Target identification in brain-computer interface (BCI) spellers refers to the electroencephalogram (EEG) classification for predicting the target character that the subject intends to spell. When the visual stimulus of each character is tagged with a distinct frequency, the EEG records steady-state visually evoked potentials (SSVEP) whose spectrum is dominated by the harmonics of the target frequency. In this setting, we address the target identification and propose a novel deep neural network (DNN) architecture. The proposed DNN processes the multi-channel SSVEP with convolutions across the sub-bands of harmonics, channels, time, and classifies at the fully connected layer. We test with two publicly available large scale (the benchmark and BETA) datasets consisting of in total 105 subjects with 40 characters. Our first stage training learns a global model by exploiting the statistical commonalities among all subjects, and the second stage fine tunes to each subject separately by exploiting the individualities. Our DNN strongly outperforms the state-of-the-art on both datasets, by achieving impressive information transfer rates 265.23 bits/min and 196.59 bits/min, respectively, with only 0.4 seconds of stimulation. To our best knowledge, our rates are the highest ever reported performance results on these datasets. The code is available for reproducibility at https://github.com/osmanberke/Deep-SSVEP-BCI.