 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Evidentiary Limits of Membership Inference for Copyright Auditing
Jan 19, 2026As large language models (LLMs) are trained on increasingly opaque corpora, membership inference attacks (MIAs) have been proposed to audit whether copyrighted texts were used during training, despite growing concerns about their reliability under realistic conditions. We ask whether MIAs can serve as admissible evidence in adversarial copyright disputes where an accused model developer may obfuscate training data while preserving semantic content, and formalize this setting through a judge-prosecutor-accused communication protocol. To test robustness under this protocol, we introduce SAGE (Structure-Aware SAE-Guided Extraction), a paraphrasing framework guided by Sparse Autoencoders (SAEs) that rewrites training data to alter lexical structure while preserving semantic content and downstream utility. Our experiments show that state-of-the-art MIAs degrade when models are fine-tuned on SAGE-generated paraphrases, indicating that their signals are not robust to semantics-preserving transformations. While some leakage remains in certain fine-tuning regimes, these results suggest that MIAs are brittle in adversarial settings and insufficient, on their own, as a standalone mechanism for copyright auditing of LLMs.
Adapting the Biological SSVEP Response to Artificial Neural Networks
Nov 15, 2024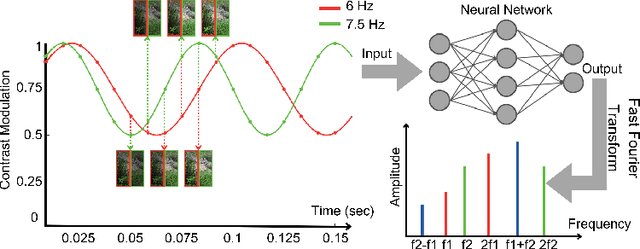
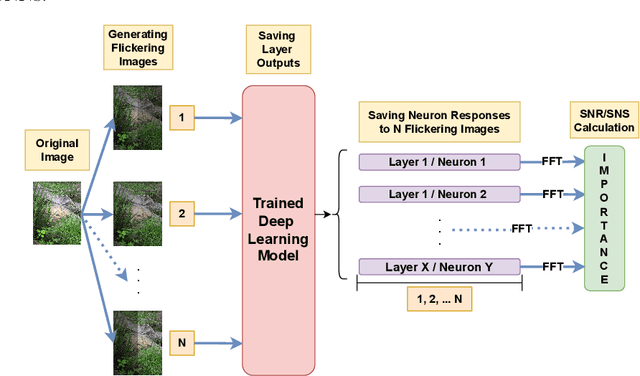
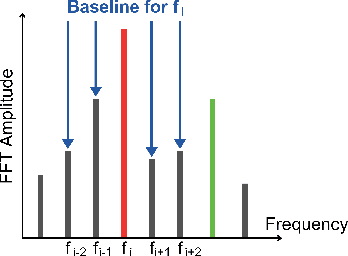
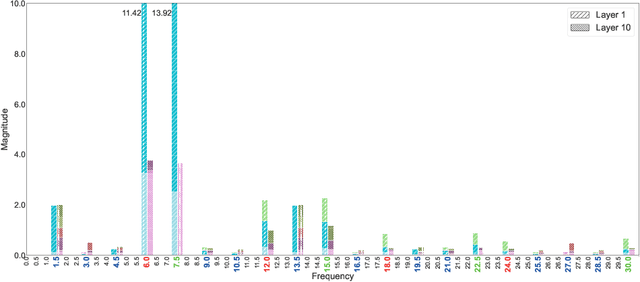
Neuron importance assessment is crucial for understanding the inner workings of artificial neural networks (ANNs) and improving their interpretability and efficiency. This paper introduces a novel approach to neuron significance assessment inspired by frequency tagging, a technique from neuroscience. By applying sinusoidal contrast modulation to image inputs and analyzing resulting neuron activations, this method enables fine-grained analysis of a network's decision-making processes. Experiments conducted with a convolutional neural network for image classification reveal notable harmonics and intermodulations in neuron-specific responses under part-based frequency tagging. These findings suggest that ANNs exhibit behavior akin to biological brains in tuning to flickering frequencies, thereby opening avenues for neuron/filter importance assessment through frequency tagging. The proposed method holds promise for applications in network pruning, and model interpretability, contributing to the advancement of explainable artificial intelligence and addressing the lack of transparency in neural networks. Future research directions include developing novel loss functions to encourage biologically plausible behavior in ANNs.