 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Physical Adversarial Example Threats to Machine Learning in Election Systems
Feb 28, 2026Developments in the machine learning voting domain have shown both promising results and risks. Trained models perform well on ballot classification tasks (> 99% accuracy) but are at risk from adversarial example attacks that cause misclassifications. In this paper, we analyze an attacker who seeks to deploy adversarial examples against machine learning ballot classifiers to compromise a U.S. election. We first derive a probabilistic framework for determining the number of adversarial example ballots that must be printed to flip an election, in terms of the probability of each candidate winning and the total number of ballots cast. Second, it is an open question as to which type of adversarial example is most effective when physically printed in the voting domain. We analyze six different types of adversarial example attacks: l_infinity-APGD, l2-APGD, l1-APGD, l0 PGD, l0 + l_infinity PGD, and l0 + sigma-map PGD. Our experiments include physical realizations of 144,000 adversarial examples through printing and scanning with four different machine learning models. We empirically demonstrate an analysis gap between the physical and digital domains, wherein attacks most effective in the digital domain (l2 and l_infinity) differ from those most effective in the physical domain (l1 and l2, depending on the model). By unifying a probabilistic election framework with digital and physical adversarial example evaluations, we move beyond prior close race analyses to explicitly quantify when and how adversarial ballot manipulation could alter outcomes.
On the Evidentiary Limits of Membership Inference for Copyright Auditing
Jan 19, 2026As large language models (LLMs) are trained on increasingly opaque corpora, membership inference attacks (MIAs) have been proposed to audit whether copyrighted texts were used during training, despite growing concerns about their reliability under realistic conditions. We ask whether MIAs can serve as admissible evidence in adversarial copyright disputes where an accused model developer may obfuscate training data while preserving semantic content, and formalize this setting through a judge-prosecutor-accused communication protocol. To test robustness under this protocol, we introduce SAGE (Structure-Aware SAE-Guided Extraction), a paraphrasing framework guided by Sparse Autoencoders (SAEs) that rewrites training data to alter lexical structure while preserving semantic content and downstream utility. Our experiments show that state-of-the-art MIAs degrade when models are fine-tuned on SAGE-generated paraphrases, indicating that their signals are not robust to semantics-preserving transformations. While some leakage remains in certain fine-tuning regimes, these results suggest that MIAs are brittle in adversarial settings and insufficient, on their own, as a standalone mechanism for copyright auditing of LLMs.
Busting the Paper Ballot: Voting Meets Adversarial Machine Learning
Jun 17, 2025
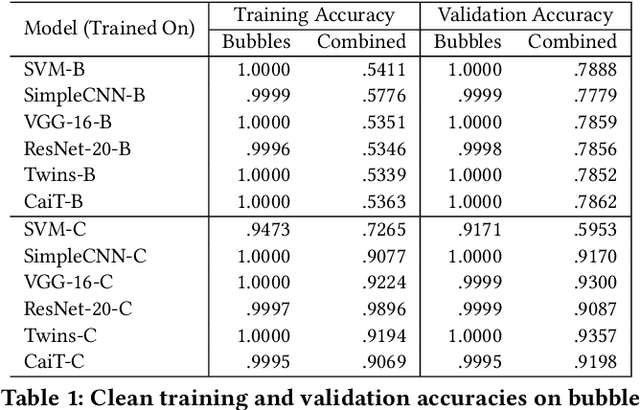

We show the security risk associated with using machine learning classifiers in United States election tabulators. The central classification task in election tabulation is deciding whether a mark does or does not appear on a bubble associated to an alternative in a contest on the ballot. Barretto et al. (E-Vote-ID 2021) reported that convolutional neural networks are a viable option in this field, as they outperform simple feature-based classifiers. Our contributions to election security can be divided into four parts. To demonstrate and analyze the hypothetical vulnerability of machine learning models on election tabulators, we first introduce four new ballot datasets. Second, we train and test a variety of different models on our new datasets. These models include support vector machines, convolutional neural networks (a basic CNN, VGG and ResNet), and vision transformers (Twins and CaiT). Third, using our new datasets and trained models, we demonstrate that traditional white box attacks are ineffective in the voting domain due to gradient masking. Our analyses further reveal that gradient masking is a product of numerical instability. We use a modified difference of logits ratio loss to overcome this issue (Croce and Hein, ICML 2020). Fourth, in the physical world, we conduct attacks with the adversarial examples generated using our new methods. In traditional adversarial machine learning, a high (50% or greater) attack success rate is ideal. However, for certain elections, even a 5% attack success rate can flip the outcome of a race. We show such an impact is possible in the physical domain. We thoroughly discuss attack realism, and the challenges and practicality associated with printing and scanning ballot adversarial examples.
Beyond Anonymization: Object Scrubbing for Privacy-Preserving 2D and 3D Vision Tasks
Apr 23, 2025We introduce ROAR (Robust Object Removal and Re-annotation), a scalable framework for privacy-preserving dataset obfuscation that eliminates sensitive objects instead of modifying them. Our method integrates instance segmentation with generative inpainting to remove identifiable entities while preserving scene integrity. Extensive evaluations on 2D COCO-based object detection show that ROAR achieves 87.5% of the baseline detection average precision (AP), whereas image dropping achieves only 74.2% of the baseline AP, highlighting the advantage of scrubbing in preserving dataset utility. The degradation is even more severe for small objects due to occlusion and loss of fine-grained details. Furthermore, in NeRF-based 3D reconstruction, our method incurs a PSNR loss of at most 1.66 dB while maintaining SSIM and improving LPIPS, demonstrating superior perceptual quality. Our findings establish object removal as an effective privacy framework, achieving strong privacy guarantees with minimal performance trade-offs. The results highlight key challenges in generative inpainting, occlusion-robust segmentation, and task-specific scrubbing, setting the foundation for future advancements in privacy-preserving vision systems.
Enhanced Computationally Efficient Long LoRA Inspired Perceiver Architectures for Auto-Regressive Language Modeling
Dec 08, 2024The Transformer architecture has revolutionized the Natural Language Processing field and is the backbone of Large Language Models (LLMs). The Transformer uses the attention mechanism that computes the pair-wise similarity between its input tokens to produce latent vectors that are able to understand the semantic meaning of the input text. One of the challenges in the Transformer architecture is the quadratic complexity of the attention mechanism that prohibits the efficient processing of long sequence lengths. While many recent research works have attempted to provide a reduction from $O(n^2)$ time complexity of attention to semi-linear complexity, it remains an unsolved problem in the sense of maintaining a high performance when such complexity is reduced. One of the important works in this respect is the Perceiver class of architectures that have demonstrated excellent performance while reducing the computation complexity. In this paper, we use the PerceiverAR that was proposed for Auto-Regressive modeling as a baseline, and provide three different architectural enhancements to it with varying computation overhead tradeoffs. Inspired by the recently proposed efficient attention computation approach of Long-LoRA, we then present an equally efficient Perceiver-based architecture (termed as Long LoRA Pereceiver - LLP) that can be used as the base architecture in LLMs instead of just a fine-tuning add-on. Our results on different benchmarks indicate impressive improvements compared to recent Transformer based models.
Theoretical Corrections and the Leveraging of Reinforcement Learning to Enhance Triangle Attack
Nov 18, 2024



Adversarial examples represent a serious issue for the application of machine learning models in many sensitive domains. For generating adversarial examples, decision based black-box attacks are one of the most practical techniques as they only require query access to the model. One of the most recently proposed state-of-the-art decision based black-box attacks is Triangle Attack (TA). In this paper, we offer a high-level description of TA and explain potential theoretical limitations. We then propose a new decision based black-box attack, Triangle Attack with Reinforcement Learning (TARL). Our new attack addresses the limits of TA by leveraging reinforcement learning. This creates an attack that can achieve similar, if not better, attack accuracy than TA with half as many queries on state-of-the-art classifiers and defenses across ImageNet and CIFAR-10.
Certifying Adapters: Enabling and Enhancing the Certification of Classifier Adversarial Robustness
May 25, 2024
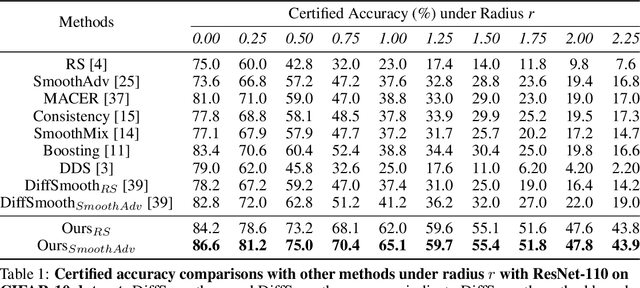
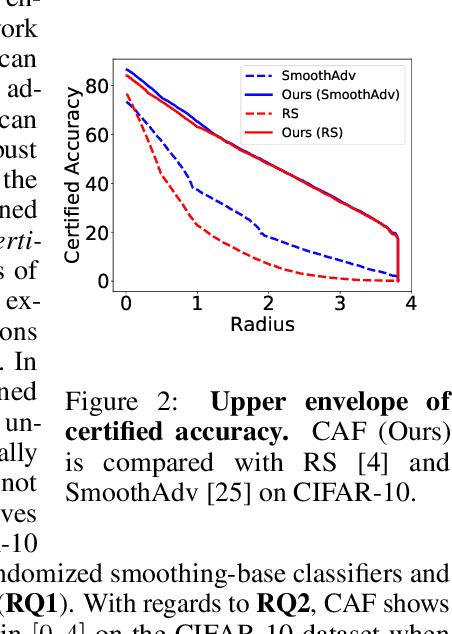

Randomized smoothing has become a leading method for achieving certified robustness in deep classifiers against l_{p}-norm adversarial perturbations. Current approaches for achieving certified robustness, such as data augmentation with Gaussian noise and adversarial training, require expensive training procedures that tune large models for different Gaussian noise levels and thus cannot leverage high-performance pre-trained neural networks. In this work, we introduce a novel certifying adapters framework (CAF) that enables and enhances the certification of classifier adversarial robustness. Our approach makes few assumptions about the underlying training algorithm or feature extractor and is thus broadly applicable to different feature extractor architectures (e.g., convolutional neural networks or vision transformers) and smoothing algorithms. We show that CAF (a) enables certification in uncertified models pre-trained on clean datasets and (b) substantially improves the performance of certified classifiers via randomized smoothing and SmoothAdv at multiple radii in CIFAR-10 and ImageNet. We demonstrate that CAF achieves improved certified accuracies when compared to methods based on random or denoised smoothing, and that CAF is insensitive to certifying adapter hyperparameters. Finally, we show that an ensemble of adapters enables a single pre-trained feature extractor to defend against a range of noise perturbation scales.
Distilling Adversarial Robustness Using Heterogeneous Teachers
Feb 23, 2024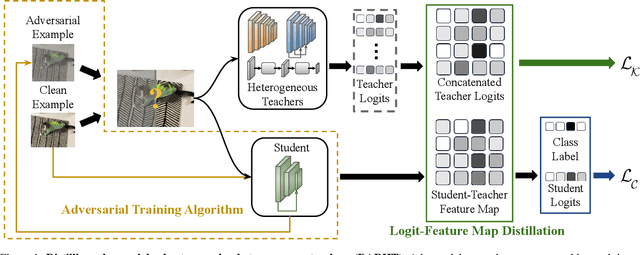
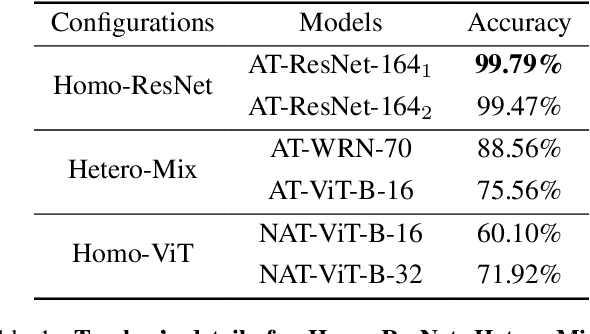
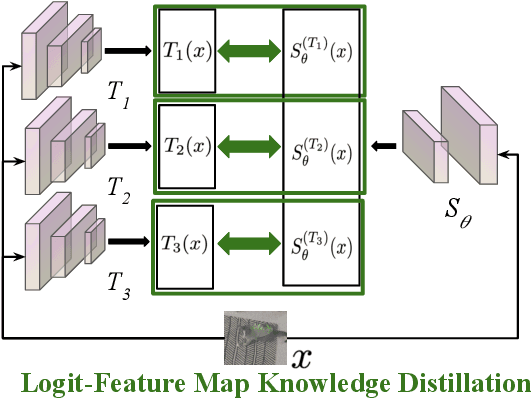
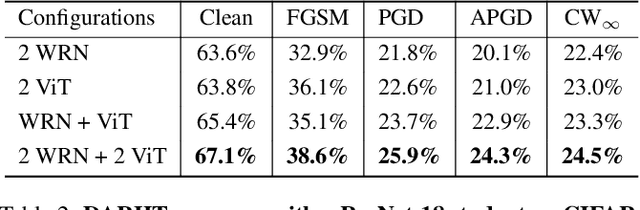
Achieving resiliency against adversarial attacks is necessary prior to deploying neural network classifiers in domains where misclassification incurs substantial costs, e.g., self-driving cars or medical imaging. Recent work has demonstrated that robustness can be transferred from an adversarially trained teacher to a student model using knowledge distillation. However, current methods perform distillation using a single adversarial and vanilla teacher and consider homogeneous architectures (i.e., residual networks) that are susceptible to misclassify examples from similar adversarial subspaces. In this work, we develop a defense framework against adversarial attacks by distilling adversarial robustness using heterogeneous teachers (DARHT). In DARHT, the student model explicitly represents teacher logits in a student-teacher feature map and leverages multiple teachers that exhibit low adversarial example transferability (i.e., exhibit high performance on dissimilar adversarial examples). Experiments on classification tasks in both white-box and black-box scenarios demonstrate that DARHT achieves state-of-the-art clean and robust accuracies when compared to competing adversarial training and distillation methods in the CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. Comparisons with homogeneous and heterogeneous teacher sets suggest that leveraging teachers with low adversarial example transferability increases student model robustness.
AutoReP: Automatic ReLU Replacement for Fast Private Network Inference
Aug 20, 2023



The growth of the Machine-Learning-As-A-Service (MLaaS) market has highlighted clients' data privacy and security issues. Private inference (PI) techniques using cryptographic primitives offer a solution but often have high computation and communication costs, particularly with non-linear operators like ReLU. Many attempts to reduce ReLU operations exist, but they may need heuristic threshold selection or cause substantial accuracy loss. This work introduces AutoReP, a gradient-based approach to lessen non-linear operators and alleviate these issues. It automates the selection of ReLU and polynomial functions to speed up PI applications and introduces distribution-aware polynomial approximation (DaPa) to maintain model expressivity while accurately approximating ReLUs. Our experimental results demonstrate significant accuracy improvements of 6.12% (94.31%, 12.9K ReLU budget, CIFAR-10), 8.39% (74.92%, 12.9K ReLU budget, CIFAR-100), and 9.45% (63.69%, 55K ReLU budget, Tiny-ImageNet) over current state-of-the-art methods, e.g., SNL. Morever, AutoReP is applied to EfficientNet-B2 on ImageNet dataset, and achieved 75.55% accuracy with 176.1 times ReLU budget reduction.
Dynamic Gradient Balancing for Enhanced Adversarial Attacks on Multi-Task Models
May 20, 2023Multi-task learning (MTL) creates a single machine learning model called multi-task model to simultaneously perform multiple tasks. Although the security of single task classifiers has been extensively studied, there are several critical security research questions for multi-task models including 1) How secure are multi-task models to single task adversarial machine learning attacks, 2) Can adversarial attacks be designed to attack multiple tasks simultaneously, and 3) Does task sharing and adversarial training increase multi-task model robustness to adversarial attacks? In this paper, we answer these questions through careful analysis and rigorous experimentation. First, we develop na\"ive adaptation of single-task white-box attacks and analyze their inherent drawbacks. We then propose a novel attack framework, Dynamic Gradient Balancing Attack (DGBA). Our framework poses the problem of attacking a multi-task model as an optimization problem based on averaged relative loss change, which can be solved by approximating the problem as an integer linear programming problem. Extensive evaluation on two popular MTL benchmarks, NYUv2 and Tiny-Taxonomy, demonstrates the effectiveness of DGBA compared to na\"ive multi-task attack baselines on both clean and adversarially trained multi-task models. The results also reveal a fundamental trade-off between improving task accuracy by sharing parameters across tasks and undermining model robustness due to increased attack transferability from parameter sharing.