 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccel-GCN: High-Performance GPU Accelerator Design for Graph Convolution Networks
Aug 22, 2023



Graph Convolutional Networks (GCNs) are pivotal in extracting latent information from graph data across various domains, yet their acceleration on mainstream GPUs is challenged by workload imbalance and memory access irregularity. To address these challenges, we present Accel-GCN, a GPU accelerator architecture for GCNs. The design of Accel-GCN encompasses: (i) a lightweight degree sorting stage to group nodes with similar degree; (ii) a block-level partition strategy that dynamically adjusts warp workload sizes, enhancing shared memory locality and workload balance, and reducing metadata overhead compared to designs like GNNAdvisor; (iii) a combined warp strategy that improves memory coalescing and computational parallelism in the column dimension of dense matrices. Utilizing these principles, we formulated a kernel for sparse matrix multiplication (SpMM) in GCNs that employs block-level partitioning and combined warp strategy. This approach augments performance and multi-level memory efficiency and optimizes memory bandwidth by exploiting memory coalescing and alignment. Evaluation of Accel-GCN across 18 benchmark graphs reveals that it outperforms cuSPARSE, GNNAdvisor, and graph-BLAST by factors of 1.17 times, 1.86 times, and 2.94 times respectively. The results underscore Accel-GCN as an effective solution for enhancing GCN computational efficiency.
Neuromorphic Online Learning for Spatiotemporal Patterns with a Forward-only Timeline
Jul 21, 2023Spiking neural networks (SNNs) are bio-plausible computing models with high energy efficiency. The temporal dynamics of neurons and synapses enable them to detect temporal patterns and generate sequences. While Backpropagation Through Time (BPTT) is traditionally used to train SNNs, it is not suitable for online learning of embedded applications due to its high computation and memory cost as well as extended latency. Previous works have proposed online learning algorithms, but they often utilize highly simplified spiking neuron models without synaptic dynamics and reset feedback, resulting in subpar performance. In this work, we present Spatiotemporal Online Learning for Synaptic Adaptation (SOLSA), specifically designed for online learning of SNNs composed of Leaky Integrate and Fire (LIF) neurons with exponentially decayed synapses and soft reset. The algorithm not only learns the synaptic weight but also adapts the temporal filters associated to the synapses. Compared to the BPTT algorithm, SOLSA has much lower memory requirement and achieves a more balanced temporal workload distribution. Moreover, SOLSA incorporates enhancement techniques such as scheduled weight update, early stop training and adaptive synapse filter, which speed up the convergence and enhance the learning performance. When compared to other non-BPTT based SNN learning, SOLSA demonstrates an average learning accuracy improvement of 14.2%. Furthermore, compared to BPTT, SOLSA achieves a 5% higher average learning accuracy with a 72% reduction in memory cost.
Neurogenesis Dynamics-inspired Spiking Neural Network Training Acceleration
Apr 24, 2023



Biologically inspired Spiking Neural Networks (SNNs) have attracted significant attention for their ability to provide extremely energy-efficient machine intelligence through event-driven operation and sparse activities. As artificial intelligence (AI) becomes ever more democratized, there is an increasing need to execute SNN models on edge devices. Existing works adopt weight pruning to reduce SNN model size and accelerate inference. However, these methods mainly focus on how to obtain a sparse model for efficient inference, rather than training efficiency. To overcome these drawbacks, in this paper, we propose a Neurogenesis Dynamics-inspired Spiking Neural Network training acceleration framework, NDSNN. Our framework is computational efficient and trains a model from scratch with dynamic sparsity without sacrificing model fidelity. Specifically, we design a new drop-and-grow strategy with decreasing number of non-zero weights, to maintain extreme high sparsity and high accuracy. We evaluate NDSNN using VGG-16 and ResNet-19 on CIFAR-10, CIFAR-100 and TinyImageNet. Experimental results show that NDSNN achieves up to 20.52\% improvement in accuracy on Tiny-ImageNet using ResNet-19 (with a sparsity of 99\%) as compared to other SOTA methods (e.g., Lottery Ticket Hypothesis (LTH), SET-SNN, RigL-SNN). In addition, the training cost of NDSNN is only 40.89\% of the LTH training cost on ResNet-19 and 31.35\% of the LTH training cost on VGG-16 on CIFAR-10.
Securing the Spike: On the Transferabilty and Security of Spiking Neural Networks to Adversarial Examples
Sep 07, 2022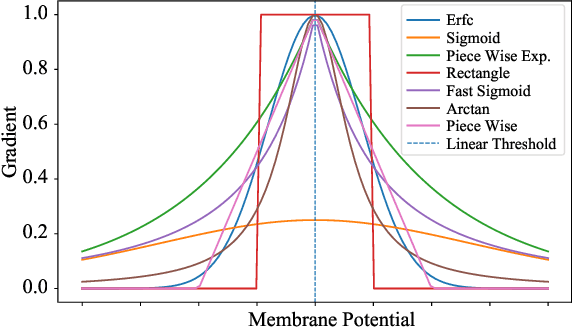
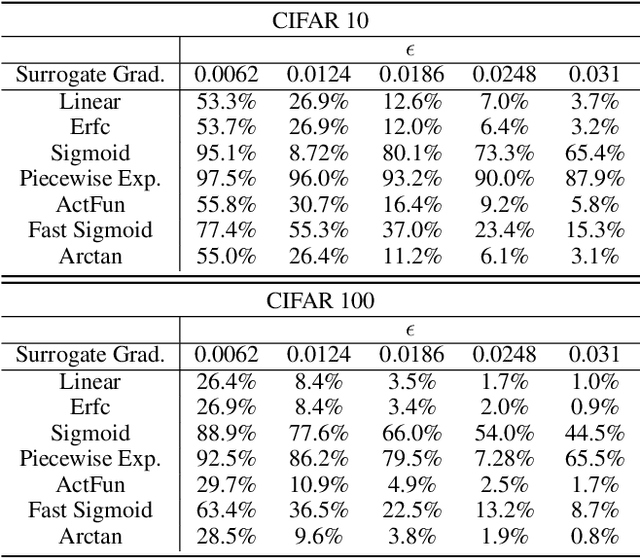
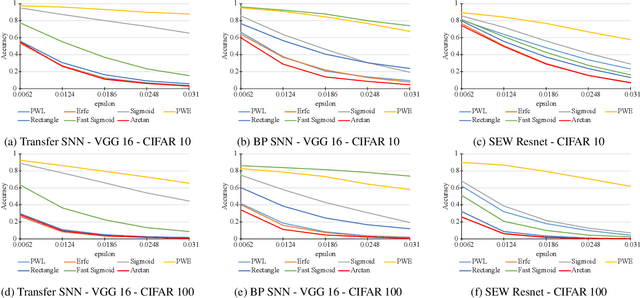
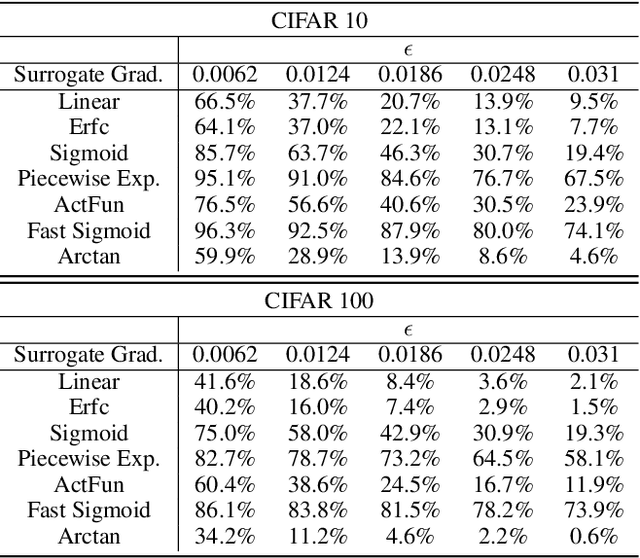
Spiking neural networks (SNNs) have attracted much attention for their high energy efficiency and for recent advances in their classification performance. However, unlike traditional deep learning approaches, the analysis and study of the robustness of SNNs to adversarial examples remains relatively underdeveloped. In this work we advance the field of adversarial machine learning through experimentation and analyses of three important SNN security attributes. First, we show that successful white-box adversarial attacks on SNNs are highly dependent on the underlying surrogate gradient technique. Second, we analyze the transferability of adversarial examples generated by SNNs and other state-of-the-art architectures like Vision Transformers and Big Transfer CNNs. We demonstrate that SNNs are not often deceived by adversarial examples generated by Vision Transformers and certain types of CNNs. Lastly, we develop a novel white-box attack that generates adversarial examples capable of fooling both SNN models and non-SNN models simultaneously. Our experiments and analyses are broad and rigorous covering two datasets (CIFAR-10 and CIFAR-100), five different white-box attacks and twelve different classifier models.
In-Hardware Learning of Multilayer Spiking Neural Networks on a Neuromorphic Processor
May 08, 2021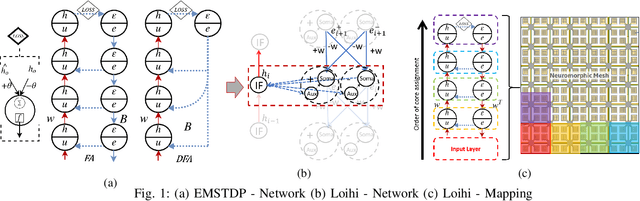
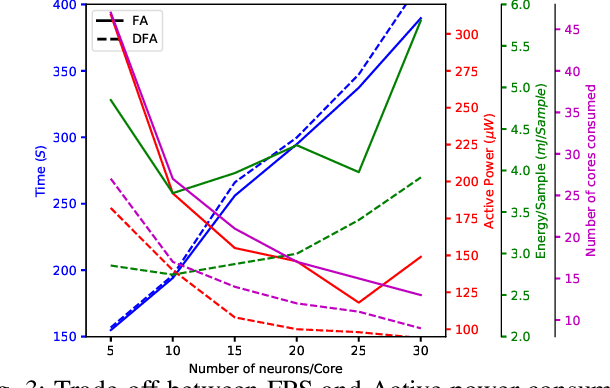
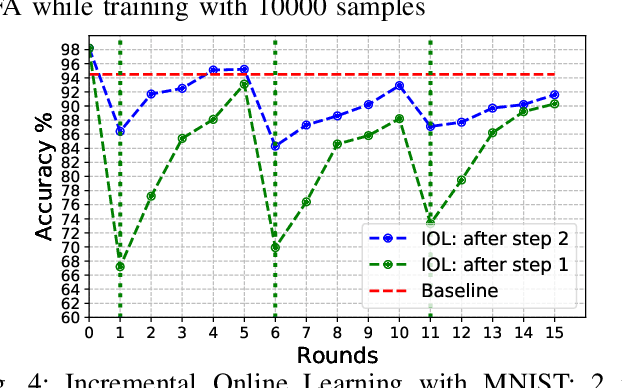
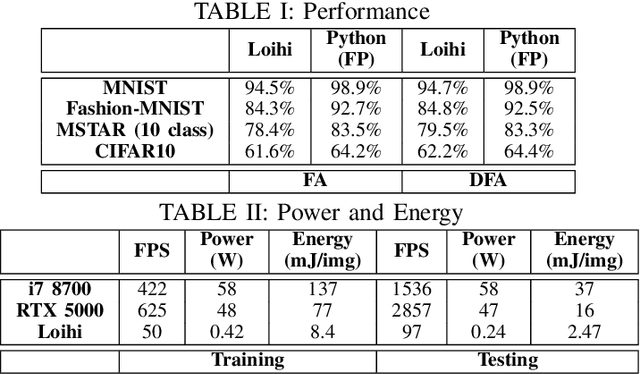
Although widely used in machine learning, backpropagation cannot directly be applied to SNN training and is not feasible on a neuromorphic processor that emulates biological neuron and synapses. This work presents a spike-based backpropagation algorithm with biological plausible local update rules and adapts it to fit the constraint in a neuromorphic hardware. The algorithm is implemented on Intel Loihi chip enabling low power in-hardware supervised online learning of multilayered SNNs for mobile applications. We test this implementation on MNIST, Fashion-MNIST, CIFAR-10 and MSTAR datasets with promising performance and energy-efficiency, and demonstrate a possibility of incremental online learning with the implementation.
Neuromorphic Algorithm-hardware Codesign for Temporal Pattern Learning
May 07, 2021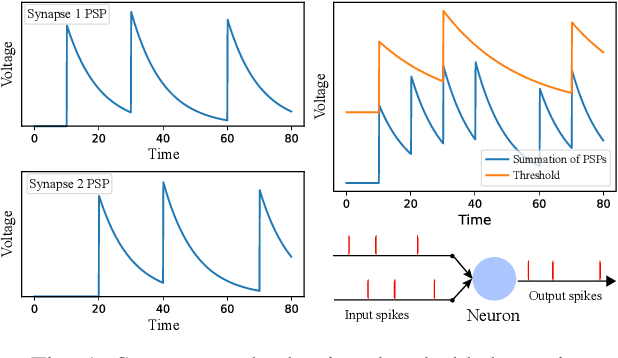
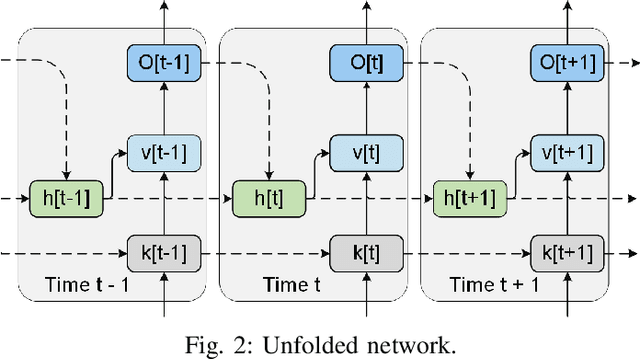
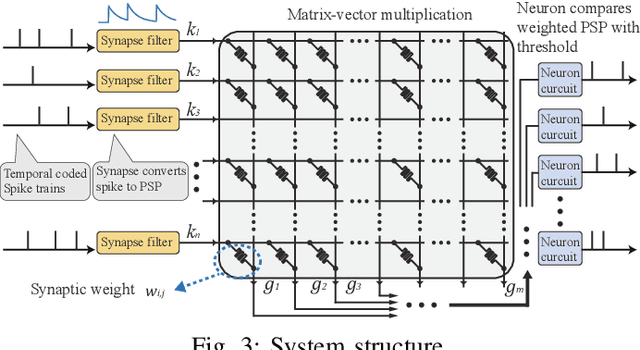
Neuromorphic computing and spiking neural networks (SNN) mimic the behavior of biological systems and have drawn interest for their potential to perform cognitive tasks with high energy efficiency. However, some factors such as temporal dynamics and spike timings prove critical for information processing but are often ignored by existing works, limiting the performance and applications of neuromorphic computing. On one hand, due to the lack of effective SNN training algorithms, it is difficult to utilize the temporal neural dynamics. Many existing algorithms still treat neuron activation statistically. On the other hand, utilizing temporal neural dynamics also poses challenges to hardware design. Synapses exhibit temporal dynamics, serving as memory units that hold historical information, but are often simplified as a connection with weight. Most current models integrate synaptic activations in some storage medium to represent membrane potential and institute a hard reset of membrane potential after the neuron emits a spike. This is done for its simplicity in hardware, requiring only a "clear" signal to wipe the storage medium, but destroys temporal information stored in the neuron. In this work, we derive an efficient training algorithm for Leaky Integrate and Fire neurons, which is capable of training a SNN to learn complex spatial temporal patterns. We achieved competitive accuracy on two complex datasets. We also demonstrate the advantage of our model by a novel temporal pattern association task. Codesigned with this algorithm, we have developed a CMOS circuit implementation for a memristor-based network of neuron and synapses which retains critical neural dynamics with reduced complexity. This circuit implementation of the neuron model is simulated to demonstrate its ability to react to temporal spiking patterns with an adaptive threshold.
FTRANS: Energy-Efficient Acceleration of Transformers using FPGA
Jul 16, 2020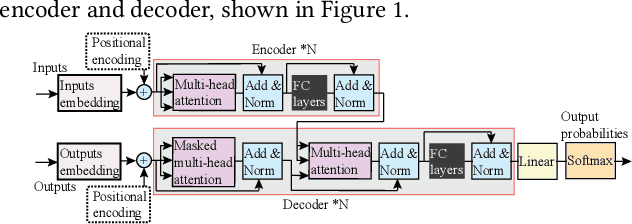

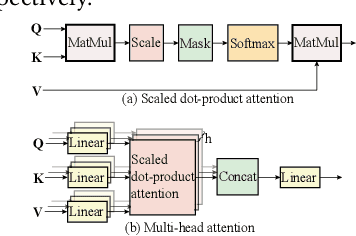
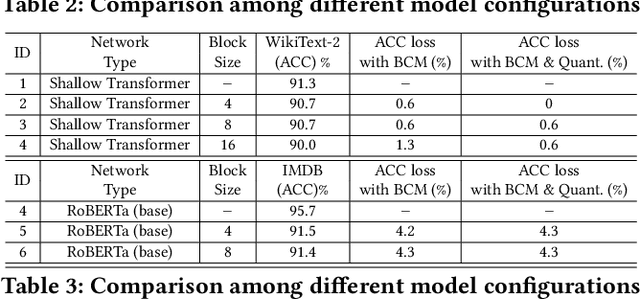
In natural language processing (NLP), the "Transformer" architecture was proposed as the first transduction model replying entirely on self-attention mechanisms without using sequence-aligned recurrent neural networks (RNNs) or convolution, and it achieved significant improvements for sequence to sequence tasks. The introduced intensive computation and storage of these pre-trained language representations has impeded their popularity into computation and memory-constrained devices. The field-programmable gate array (FPGA) is widely used to accelerate deep learning algorithms for its high parallelism and low latency. However, the trained models are still too large to accommodate to an FPGA fabric. In this paper, we propose an efficient acceleration framework, Ftrans, for transformer-based large scale language representations. Our framework includes enhanced block-circulant matrix (BCM)-based weight representation to enable model compression on large-scale language representations at the algorithm level with few accuracy degradation, and an acceleration design at the architecture level. Experimental results show that our proposed framework significantly reduces the model size of NLP models by up to 16 times. Our FPGA design achieves 27.07x and 81x improvement in performance and energy efficiency compared to CPU, and up to 8.80x improvement in energy efficiency compared to GPU.
Multivariate Time Series Classification Using Spiking Neural Networks
Jul 07, 2020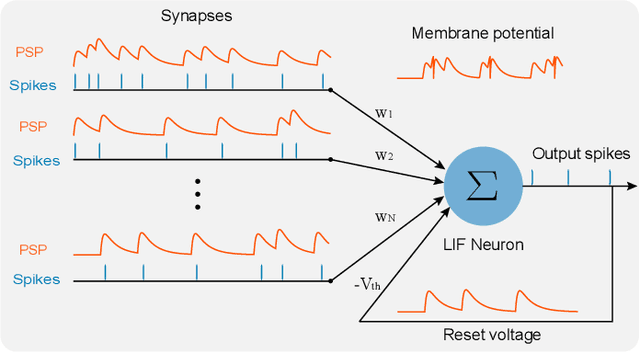
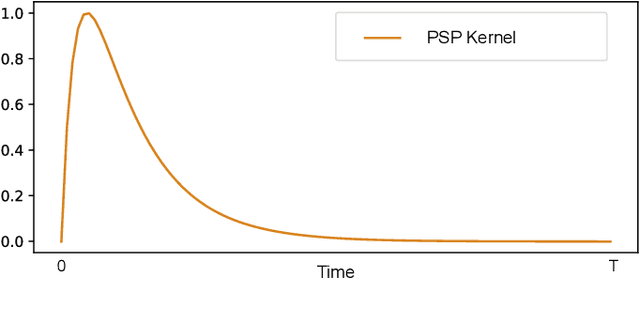
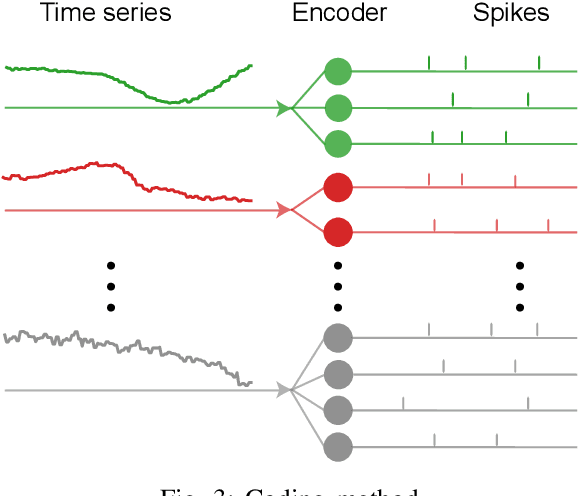
There is an increasing demand to process streams of temporal data in energy-limited scenarios such as embedded devices, driven by the advancement and expansion of Internet of Things (IoT) and Cyber-Physical Systems (CPS). Spiking neural network has drawn attention as it enables low power consumption by encoding and processing information as sparse spike events, which can be exploited for event-driven computation. Recent works also show SNNs' capability to process spatial temporal information. Such advantages can be exploited by power-limited devices to process real-time sensor data. However, most existing SNN training algorithms focus on vision tasks and temporal credit assignment is not addressed. Furthermore, widely adopted rate encoding ignores temporal information, hence it's not suitable for representing time series. In this work, we present an encoding scheme to convert time series into sparse spatial temporal spike patterns. A training algorithm to classify spatial temporal patterns is also proposed. Proposed approach is evaluated on multiple time series datasets in the UCR repository and achieved performance comparable to deep neural networks.
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Jun 06, 2020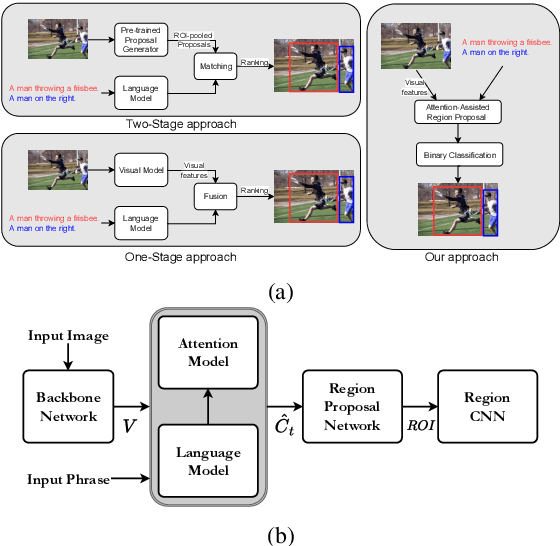
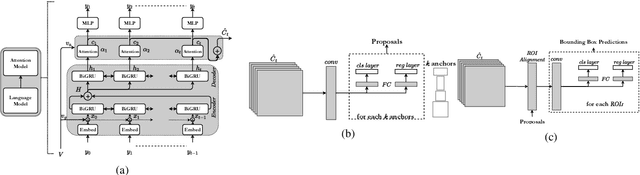


Grounding free-form textual queries necessitates an understanding of these textual phrases and its relation to the visual cues to reliably reason about the described locations. Spatial attention networks are known to learn this relationship and focus its gaze on salient objects in the image. Thus, we propose to utilize spatial attention networks for image-level visual-textual fusion preserving local (word) and global (phrase) information to refine region proposals with an in-network Region Proposal Network (RPN) and detect single or multiple regions for a phrase query. We focus only on the phrase query - ground truth pair (referring expression) for a model independent of the constraints of the datasets i.e. additional attributes, context etc. For such referring expression dataset ReferIt game, our Multi-region Attention-assisted Grounding network (MAGNet) achieves over 12\% improvement over the state-of-the-art. Without the context from image captions and attribute information in Flickr30k Entities, we still achieve competitive results compared to the state-of-the-art.
GISNet: Graph-Based Information Sharing Network For Vehicle Trajectory Prediction
Mar 22, 2020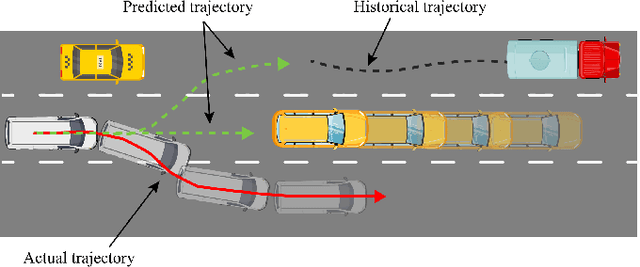
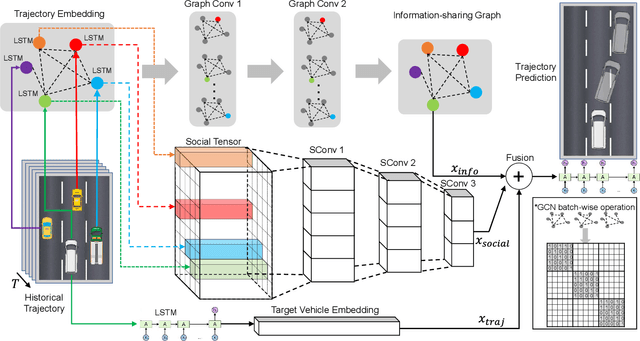
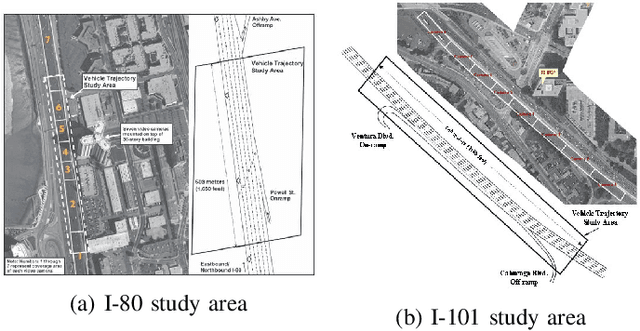
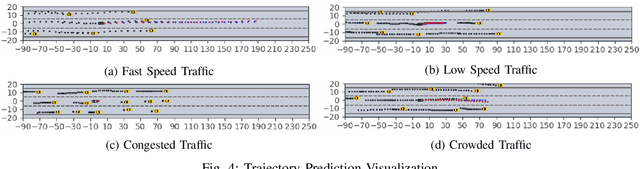
The trajectory prediction is a critical and challenging problem in the design of an autonomous driving system. Many AI-oriented companies, such as Google Waymo, Uber and DiDi, are investigating more accurate vehicle trajectory prediction algorithms. However, the prediction performance is governed by lots of entangled factors, such as the stochastic behaviors of surrounding vehicles, historical information of self-trajectory, and relative positions of neighbors, etc. In this paper, we propose a novel graph-based information sharing network (GISNet) that allows the information sharing between the target vehicle and its surrounding vehicles. Meanwhile, the model encodes the historical trajectory information of all the vehicles in the scene. Experiments are carried out on the public NGSIM US-101 and I-80 Dataset and the prediction performance is measured by the Root Mean Square Error (RMSE). The quantitative and qualitative experimental results show that our model significantly improves the trajectory prediction accuracy, by up to 50.00%, compared to existing models.