 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPMOS: Ordered Parallel Multi-Objective Shortest-Path
Nov 25, 2024



The Multi-Objective Shortest-Path (MOS) problem finds a set of Pareto-optimal solutions from a start node to a destination node in a multi-attribute graph. To solve the NP-hard MOS problem, the literature explores heuristic multi-objective A*-style algorithmic approaches. A generalized MOS algorithm maintains a "frontier" of partial paths at each node and performs ordered processing to ensure that Pareto-optimal paths are generated to reach the goal node. The algorithm becomes computationally intractable as the number of objectives increases due to a rapid increase in the non-dominated paths, and the concomitantly large increase in Pareto-optimal solutions. While prior works have focused on algorithmic methods to reduce the complexity, we tackle this challenge by exploiting parallelism using an algorithm-architecture approach. The key insight is that MOS algorithms rely on the ordered execution of partial paths to maintain high work efficiency. The OPMOS framework, proposed herein, unlocks ordered parallelism and efficiently exploits the concurrent execution of multiple paths in MOS. Experimental evaluation using the NVIDIA GH200 Superchip shows the performance scaling potential of OPMOS on work efficiency and parallelism using a real-world application to ship routing.
MaxK-GNN: Towards Theoretical Speed Limits for Accelerating Graph Neural Networks Training
Dec 18, 2023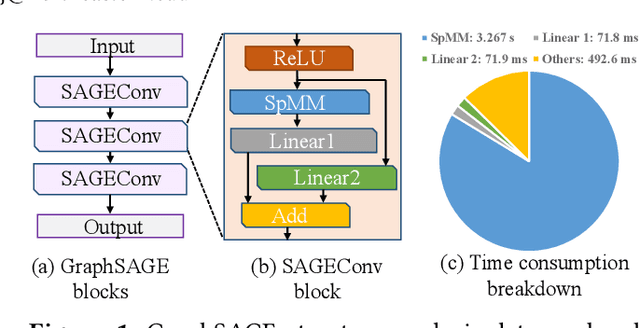

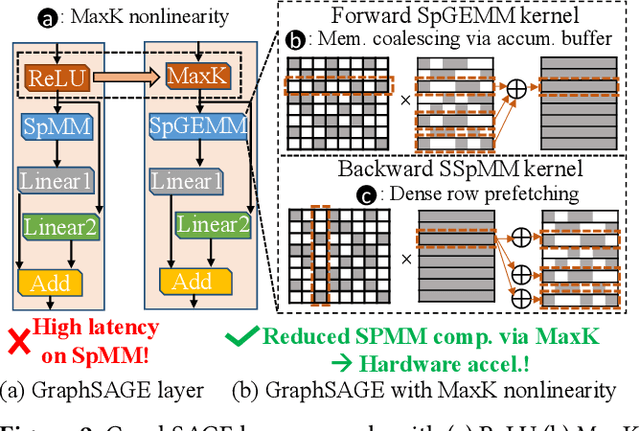
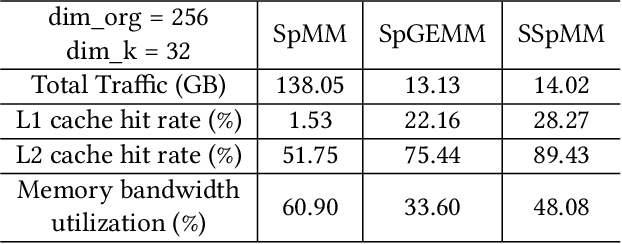
In the acceleration of deep neural network training, the GPU has become the mainstream platform. GPUs face substantial challenges on GNNs, such as workload imbalance and memory access irregularities, leading to underutilized hardware. Existing solutions such as PyG, DGL with cuSPARSE, and GNNAdvisor frameworks partially address these challenges but memory traffic is still significant. We argue that drastic performance improvements can only be achieved by the vertical optimization of algorithm and system innovations, rather than treating the speedup optimization as an "after-thought" (i.e., (i) given a GNN algorithm, designing an accelerator, or (ii) given hardware, mainly optimizing the GNN algorithm). In this paper, we present MaxK-GNN, an advanced high-performance GPU training system integrating algorithm and system innovation. (i) We introduce the MaxK nonlinearity and provide a theoretical analysis of MaxK nonlinearity as a universal approximator, and present the Compressed Balanced Sparse Row (CBSR) format, designed to store the data and index of the feature matrix after nonlinearity; (ii) We design a coalescing enhanced forward computation with row-wise product-based SpGEMM Kernel using CBSR for input feature matrix fetching and strategic placement of a sparse output accumulation buffer in shared memory; (iii) We develop an optimized backward computation with outer product-based and SSpMM Kernel. We conduct extensive evaluations of MaxK-GNN and report the end-to-end system run-time. Experiments show that MaxK-GNN system could approach the theoretical speedup limit according to Amdahl's law. We achieve comparable accuracy to SOTA GNNs, but at a significantly increased speed: 3.22/4.24 times speedup (vs. theoretical limits, 5.52/7.27 times) on Reddit compared to DGL and GNNAdvisor implementations.
Accel-GCN: High-Performance GPU Accelerator Design for Graph Convolution Networks
Aug 22, 2023



Graph Convolutional Networks (GCNs) are pivotal in extracting latent information from graph data across various domains, yet their acceleration on mainstream GPUs is challenged by workload imbalance and memory access irregularity. To address these challenges, we present Accel-GCN, a GPU accelerator architecture for GCNs. The design of Accel-GCN encompasses: (i) a lightweight degree sorting stage to group nodes with similar degree; (ii) a block-level partition strategy that dynamically adjusts warp workload sizes, enhancing shared memory locality and workload balance, and reducing metadata overhead compared to designs like GNNAdvisor; (iii) a combined warp strategy that improves memory coalescing and computational parallelism in the column dimension of dense matrices. Utilizing these principles, we formulated a kernel for sparse matrix multiplication (SpMM) in GCNs that employs block-level partitioning and combined warp strategy. This approach augments performance and multi-level memory efficiency and optimizes memory bandwidth by exploiting memory coalescing and alignment. Evaluation of Accel-GCN across 18 benchmark graphs reveals that it outperforms cuSPARSE, GNNAdvisor, and graph-BLAST by factors of 1.17 times, 1.86 times, and 2.94 times respectively. The results underscore Accel-GCN as an effective solution for enhancing GCN computational efficiency.
Towards Real-Time Temporal Graph Learning
Oct 12, 2022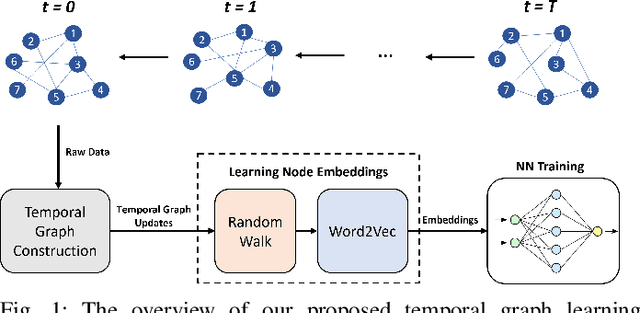
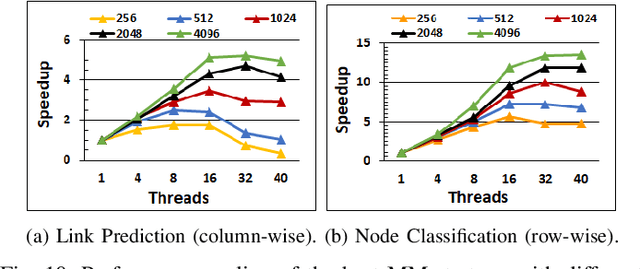
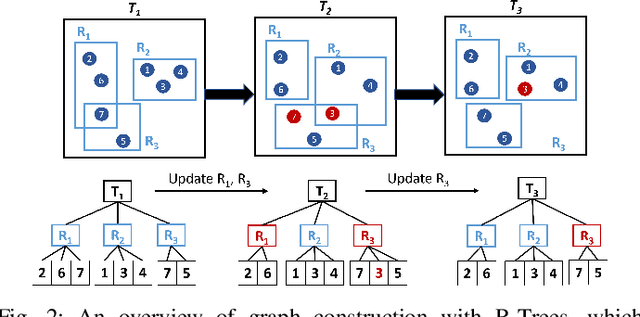
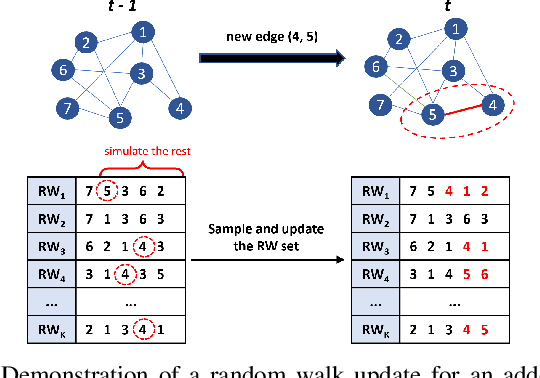
In recent years, graph representation learning has gained significant popularity, which aims to generate node embeddings that capture features of graphs. One of the methods to achieve this is employing a technique called random walks that captures node sequences in a graph and then learns embeddings for each node using a natural language processing technique called Word2Vec. These embeddings are then used for deep learning on graph data for classification tasks, such as link prediction or node classification. Prior work operates on pre-collected temporal graph data and is not designed to handle updates on a graph in real-time. Real world graphs change dynamically and their entire temporal updates are not available upfront. In this paper, we propose an end-to-end graph learning pipeline that performs temporal graph construction, creates low-dimensional node embeddings, and trains multi-layer neural network models in an online setting. The training of the neural network models is identified as the main performance bottleneck as it performs repeated matrix operations on many sequentially connected low-dimensional kernels. We propose to unlock fine-grain parallelism in these low-dimensional kernels to boost performance of model training.
Towards Sparsification of Graph Neural Networks
Sep 11, 2022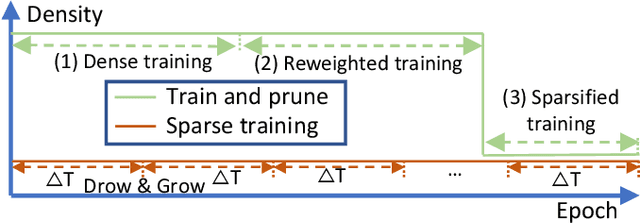
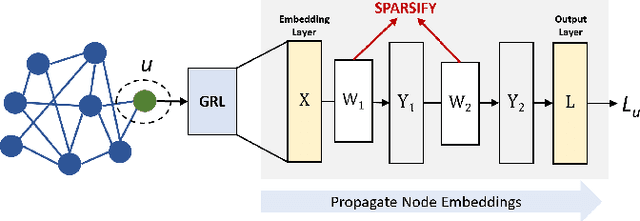
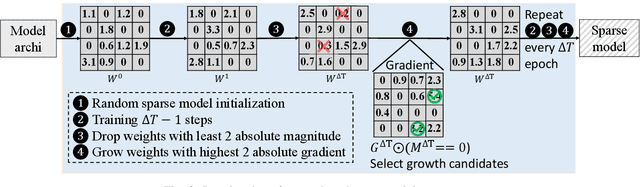

As real-world graphs expand in size, larger GNN models with billions of parameters are deployed. High parameter count in such models makes training and inference on graphs expensive and challenging. To reduce the computational and memory costs of GNNs, optimization methods such as pruning the redundant nodes and edges in input graphs have been commonly adopted. However, model compression, which directly targets the sparsification of model layers, has been mostly limited to traditional Deep Neural Networks (DNNs) used for tasks such as image classification and object detection. In this paper, we utilize two state-of-the-art model compression methods (1) train and prune and (2) sparse training for the sparsification of weight layers in GNNs. We evaluate and compare the efficiency of both methods in terms of accuracy, training sparsity, and training FLOPs on real-world graphs. Our experimental results show that on the ia-email, wiki-talk, and stackoverflow datasets for link prediction, sparse training with much lower training FLOPs achieves a comparable accuracy with the train and prune method. On the brain dataset for node classification, sparse training uses a lower number FLOPs (less than 1/7 FLOPs of train and prune method) and preserves a much better accuracy performance under extreme model sparsity.