 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU Acceleration of Sparse Fully Homomorphic Encrypted DNNs
Apr 13, 2026Fully homomorphic encryption (FHE) has recently attracted significant attention as both a cryptographic primitive and a systems challenge. Given the latest advances in accelerated computing, FHE presents a promising opportunity for progress, with applications ranging from machine learning to information security. We target the most computationally intensive operation in deep neural networks from a hardware perspective, matrix multiplication (matmul), and adapt it for execution on AMD GPUs. We propose a new optimized method that improves the runtime and complexity of ciphertext matmul by using FIDESlib, a recent open-source FHE library designed specifically for GPUs. By exploiting sparsity in both operands, our sparse matmul implementation outperforms its CPU counterpart by up to $3.0\times$ and reduces the time complexity from cubic to semi-linear, demonstrating an improvement over existing FHE matmul implementations.
Characterizing the Behavior of Training Mamba-based State Space Models on GPUs
Aug 25, 2025Mamba-based State Space Models (SSM) have emerged as a promising alternative to the ubiquitous transformers. Despite the expressive power of transformers, the quadratic complexity of computing attention is a major impediment to scaling performance as we increase the sequence length. SSMs provide an alternative path that addresses this problem, reducing the computational complexity requirements of self-attention with novel model architectures for different domains and fields such as video, text generation and graphs. Thus, it is important to characterize the behavior of these emerging workloads on GPUs and understand their requirements during GPU microarchitectural design. In this work we evaluate Mamba-based SSMs and characterize their behavior during training on GPUs. We construct a workload suite that offers representative models that span different model architectures. We then use this suite to analyze the architectural implications of running Mamba-based SSMs on GPUs. Our work sheds new light on potential optimizations to continue scaling the performance for such models.
Digital Avatars: Framework Development and Their Evaluation
Aug 07, 2024


We present a novel prompting strategy for artificial intelligence driven digital avatars. To better quantify how our prompting strategy affects anthropomorphic features like humor, authenticity, and favorability we present Crowd Vote - an adaptation of Crowd Score that allows for judges to elect a large language model (LLM) candidate over competitors answering the same or similar prompts. To visualize the responses of our LLM, and the effectiveness of our prompting strategy we propose an end-to-end framework for creating high-fidelity artificial intelligence (AI) driven digital avatars. This pipeline effectively captures an individual's essence for interaction and our streaming algorithm delivers a high-quality digital avatar with real-time audio-video streaming from server to mobile device. Both our visualization tool, and our Crowd Vote metrics demonstrate our AI driven digital avatars have state-of-the-art humor, authenticity, and favorability outperforming all competitors and baselines. In the case of our Donald Trump and Joe Biden avatars, their authenticity and favorability are rated higher than even their real-world equivalents.
* This work was presented during the IJCAI 2024 conference proceedings for demonstrations
NeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator
Apr 26, 2024



Graph Neural Networks (GNNs) are emerging as a formidable tool for processing non-euclidean data across various domains, ranging from social network analysis to bioinformatics. Despite their effectiveness, their adoption has not been pervasive because of scalability challenges associated with large-scale graph datasets, particularly when leveraging message passing. To tackle these challenges, we introduce NeuraChip, a novel GNN spatial accelerator based on Gustavson's algorithm. NeuraChip decouples the multiplication and addition computations in sparse matrix multiplication. This separation allows for independent exploitation of their unique data dependencies, facilitating efficient resource allocation. We introduce a rolling eviction strategy to mitigate data idling in on-chip memory as well as address the prevalent issue of memory bloat in sparse graph computations. Furthermore, the compute resource load balancing is achieved through a dynamic reseeding hash-based mapping, ensuring uniform utilization of computing resources agnostic of sparsity patterns. Finally, we present NeuraSim, an open-source, cycle-accurate, multi-threaded, modular simulator for comprehensive performance analysis. Overall, NeuraChip presents a significant improvement, yielding an average speedup of 22.1x over Intel's MKL, 17.1x over NVIDIA's cuSPARSE, 16.7x over AMD's hipSPARSE, and 1.5x over prior state-of-the-art SpGEMM accelerator and 1.3x over GNN accelerator. The source code for our open-sourced simulator and performance visualizer is publicly accessible on GitHub https://neurachip.us
MaxK-GNN: Towards Theoretical Speed Limits for Accelerating Graph Neural Networks Training
Dec 18, 2023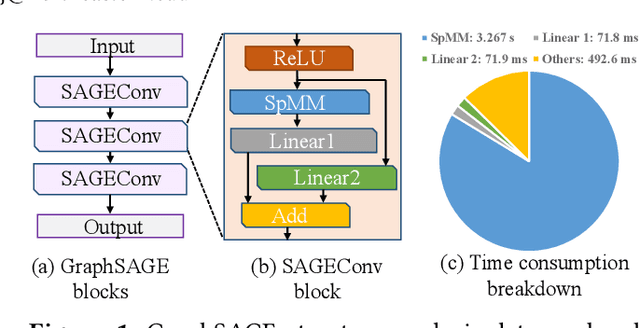

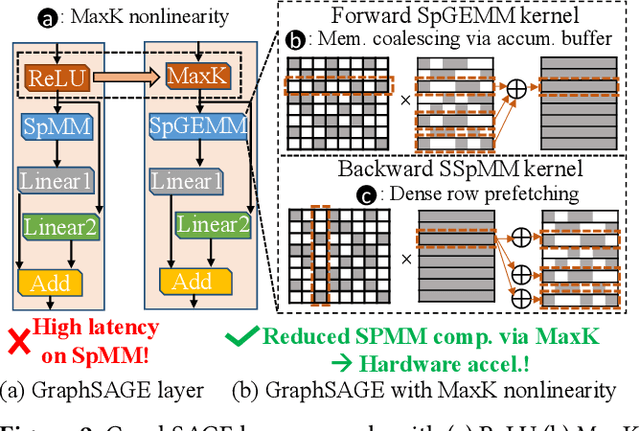
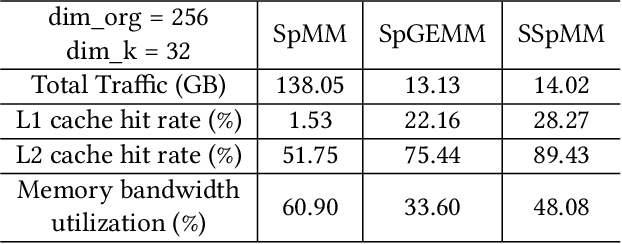
In the acceleration of deep neural network training, the GPU has become the mainstream platform. GPUs face substantial challenges on GNNs, such as workload imbalance and memory access irregularities, leading to underutilized hardware. Existing solutions such as PyG, DGL with cuSPARSE, and GNNAdvisor frameworks partially address these challenges but memory traffic is still significant. We argue that drastic performance improvements can only be achieved by the vertical optimization of algorithm and system innovations, rather than treating the speedup optimization as an "after-thought" (i.e., (i) given a GNN algorithm, designing an accelerator, or (ii) given hardware, mainly optimizing the GNN algorithm). In this paper, we present MaxK-GNN, an advanced high-performance GPU training system integrating algorithm and system innovation. (i) We introduce the MaxK nonlinearity and provide a theoretical analysis of MaxK nonlinearity as a universal approximator, and present the Compressed Balanced Sparse Row (CBSR) format, designed to store the data and index of the feature matrix after nonlinearity; (ii) We design a coalescing enhanced forward computation with row-wise product-based SpGEMM Kernel using CBSR for input feature matrix fetching and strategic placement of a sparse output accumulation buffer in shared memory; (iii) We develop an optimized backward computation with outer product-based and SSpMM Kernel. We conduct extensive evaluations of MaxK-GNN and report the end-to-end system run-time. Experiments show that MaxK-GNN system could approach the theoretical speedup limit according to Amdahl's law. We achieve comparable accuracy to SOTA GNNs, but at a significantly increased speed: 3.22/4.24 times speedup (vs. theoretical limits, 5.52/7.27 times) on Reddit compared to DGL and GNNAdvisor implementations.
SECDA: Efficient Hardware/Software Co-Design of FPGA-based DNN Accelerators for Edge Inference
Oct 01, 2021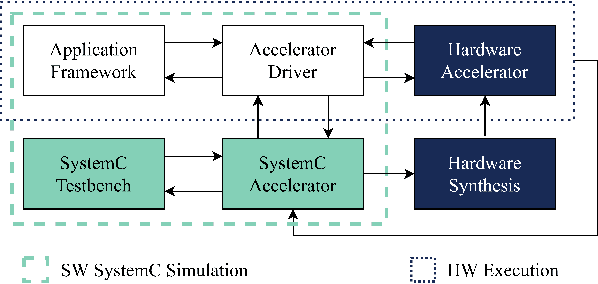
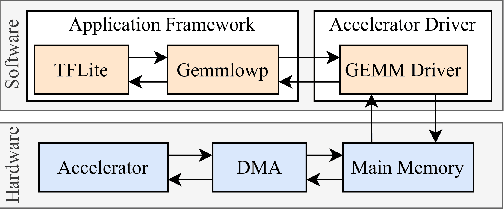
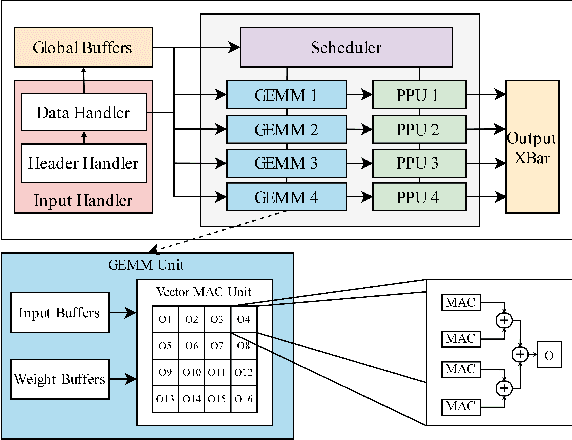
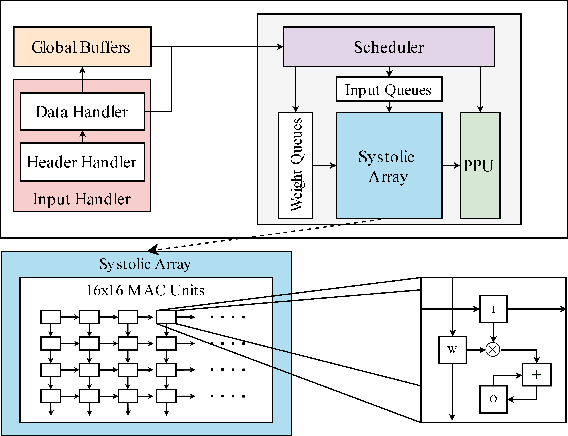
Edge computing devices inherently face tight resource constraints, which is especially apparent when deploying Deep Neural Networks (DNN) with high memory and compute demands. FPGAs are commonly available in edge devices. Since these reconfigurable circuits can achieve higher throughput and lower power consumption than general purpose processors, they are especially well-suited for DNN acceleration. However, existing solutions for designing FPGA-based DNN accelerators for edge devices come with high development overheads, given the cost of repeated FPGA synthesis passes, reimplementation in a Hardware Description Language (HDL) of the simulated design, and accelerator system integration. In this paper we propose SECDA, a new hardware/software co-design methodology to reduce design time of optimized DNN inference accelerators on edge devices with FPGAs. SECDA combines cost-effective SystemC simulation with hardware execution, streamlining design space exploration and the development process via reduced design evaluation time. As a case study, we use SECDA to efficiently develop two different DNN accelerator designs on a PYNQ-Z1 board, a platform that includes an edge FPGA. We quickly and iteratively explore the system's hardware/software stack, while identifying and mitigating performance bottlenecks. We evaluate the two accelerator designs with four common DNN models, achieving an average performance speedup across models of up to 3.5$\times$ with a 2.9$\times$ reduction in energy consumption over CPU-only inference. Our code is available at https://github.com/gicLAB/SECDA
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021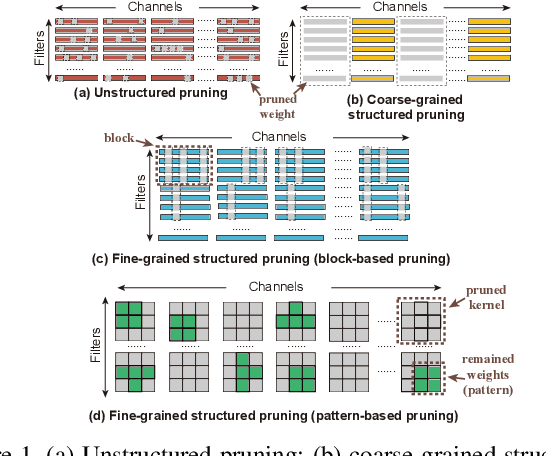
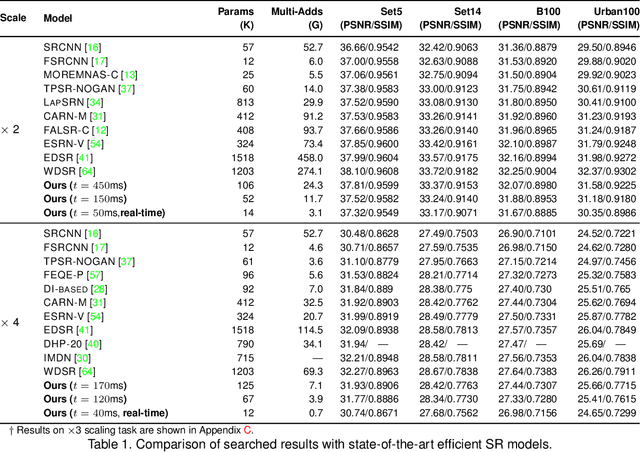
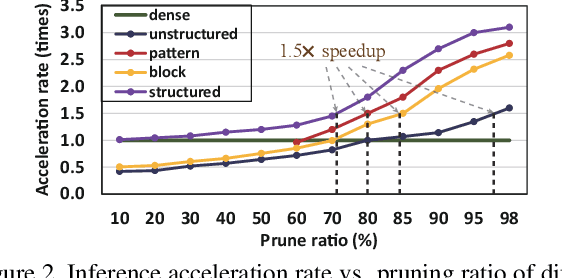
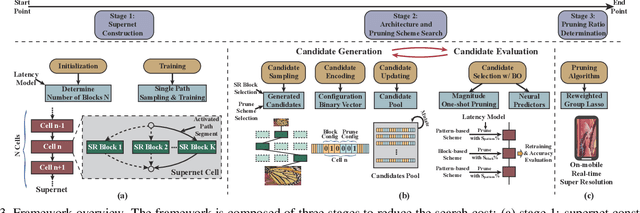
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
A Smart Background Scheduler for Storage Systems
Jun 02, 2020
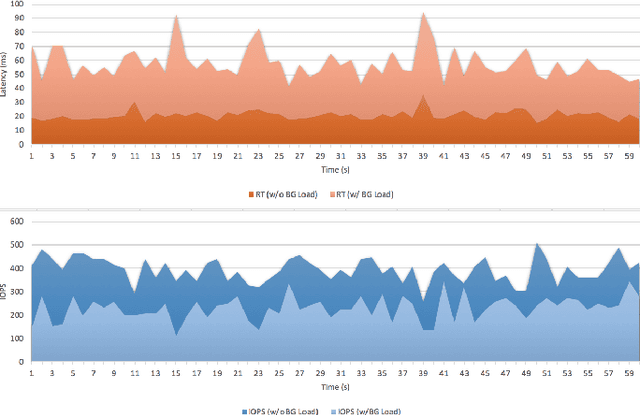
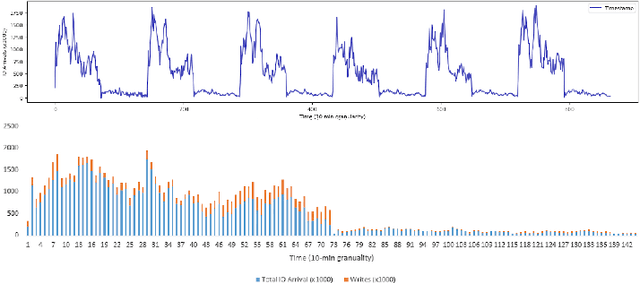
In today's enterprise storage systems, supported data services such as snapshot delete or drive rebuild can cause tremendous performance interference if executed inline along with heavy foreground IO, often leading to missing SLOs (Service Level Objectives). Typical storage system applications such as web or VDI (Virtual Desktop Infrastructure) follow a repetitive high/low workload pattern that can be learned and forecasted. We propose a priority-based background scheduler that learns this repetitive pattern and allows storage systems to maintain peak performance and in turn meet service level objectives (SLOs) while supporting a number of data services. When foreground IO demand intensifies, system resources are dedicated to service foreground IO requests and any background processing that can be deferred are recorded to be processed in future idle cycles as long as forecast shows that storage pool has remaining capacity. The smart background scheduler adopts a resource partitioning model that allows both foreground and background IO to execute together as long as foreground IOs are not impacted where the scheduler harness any free cycle to clear background debt. Using traces from VDI application, we show how our technique surpasses a method that statically limit the deferred background debt and improve SLO violations from 54.6% when using a fixed background debt watermark to merely a 6.2% if dynamically set by our smart background scheduler.
Iterative Spectral Method for Alternative Clustering
Sep 08, 2019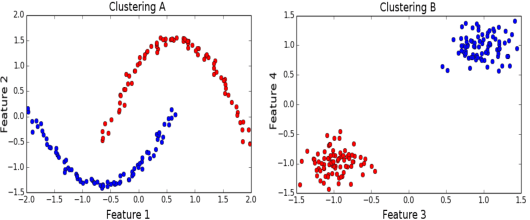
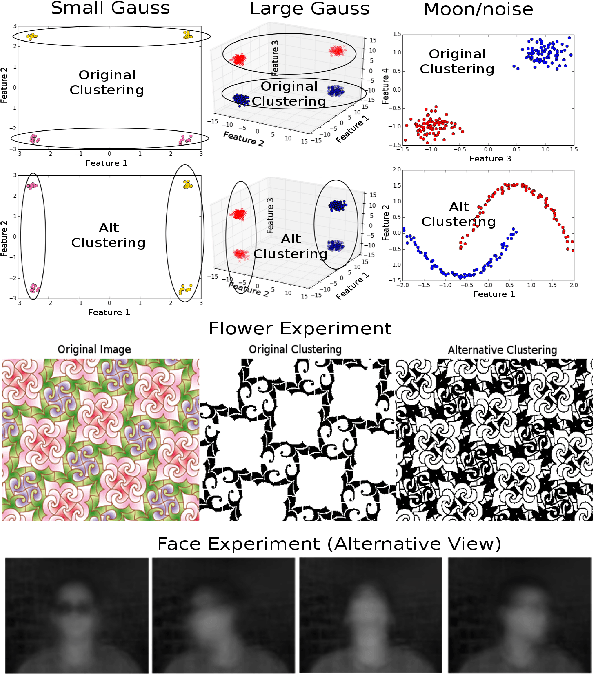
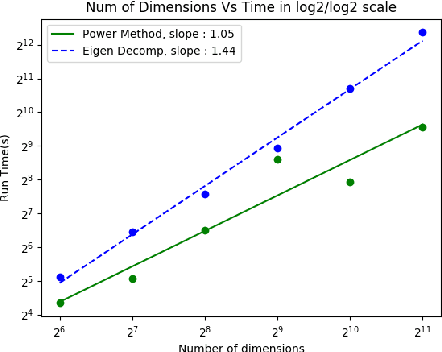
Given a dataset and an existing clustering as input, alternative clustering aims to find an alternative partition. One of the state-of-the-art approaches is Kernel Dimension Alternative Clustering (KDAC). We propose a novel Iterative Spectral Method (ISM) that greatly improves the scalability of KDAC. Our algorithm is intuitive, relies on easily implementable spectral decompositions, and comes with theoretical guarantees. Its computation time improves upon existing implementations of KDAC by as much as 5 orders of magnitude.
Defensive Dropout for Hardening Deep Neural Networks under Adversarial Attacks
Sep 13, 2018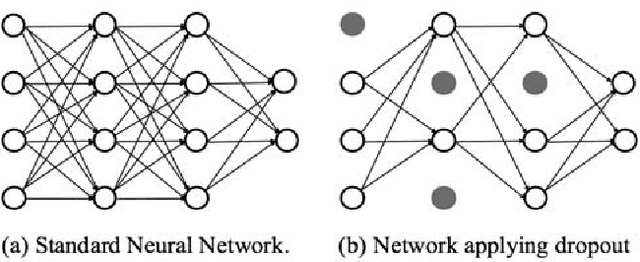
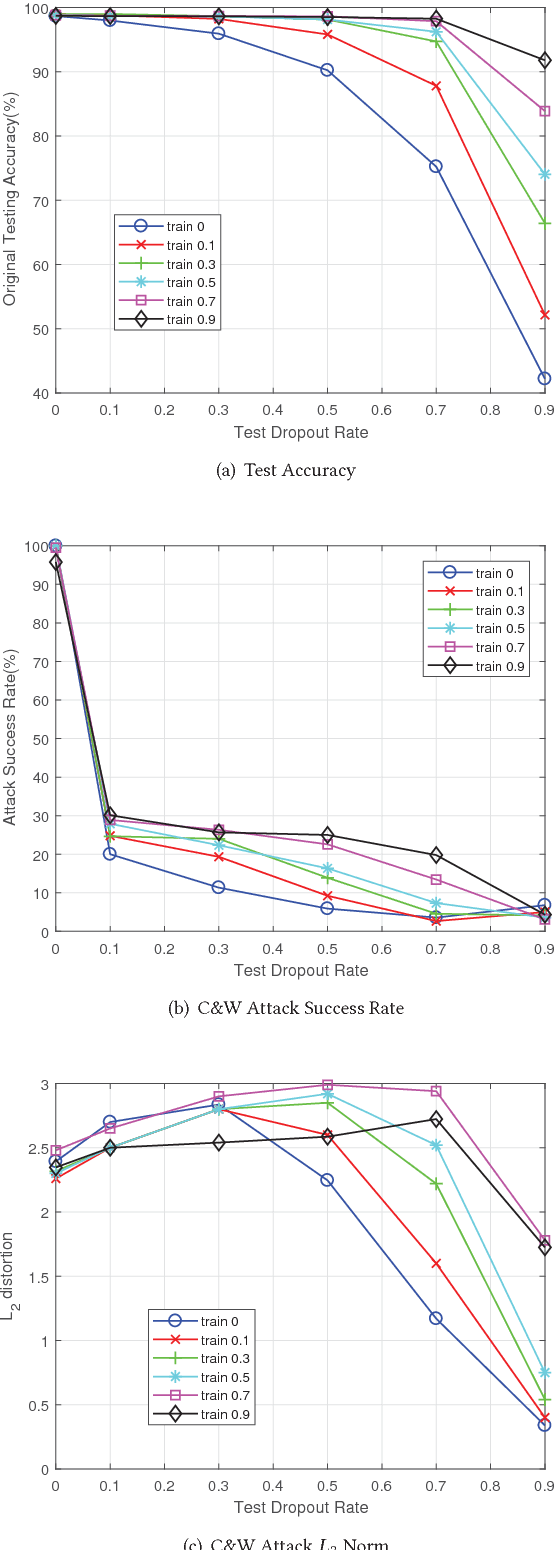
Deep neural networks (DNNs) are known vulnerable to adversarial attacks. That is, adversarial examples, obtained by adding delicately crafted distortions onto original legal inputs, can mislead a DNN to classify them as any target labels. This work provides a solution to hardening DNNs under adversarial attacks through defensive dropout. Besides using dropout during training for the best test accuracy, we propose to use dropout also at test time to achieve strong defense effects. We consider the problem of building robust DNNs as an attacker-defender two-player game, where the attacker and the defender know each others' strategies and try to optimize their own strategies towards an equilibrium. Based on the observations of the effect of test dropout rate on test accuracy and attack success rate, we propose a defensive dropout algorithm to determine an optimal test dropout rate given the neural network model and the attacker's strategy for generating adversarial examples.We also investigate the mechanism behind the outstanding defense effects achieved by the proposed defensive dropout. Comparing with stochastic activation pruning (SAP), another defense method through introducing randomness into the DNN model, we find that our defensive dropout achieves much larger variances of the gradients, which is the key for the improved defense effects (much lower attack success rate). For example, our defensive dropout can reduce the attack success rate from 100% to 13.89% under the currently strongest attack i.e., C&W attack on MNIST dataset.