 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECDA: Efficient Hardware/Software Co-Design of FPGA-based DNN Accelerators for Edge Inference
Paper and Code
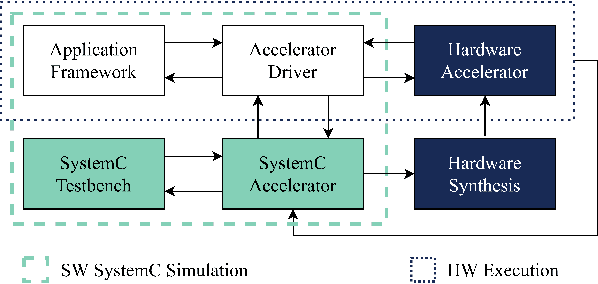
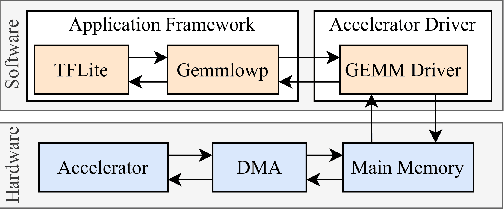
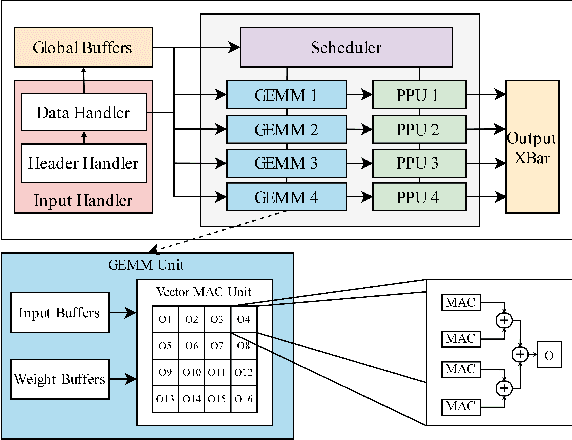
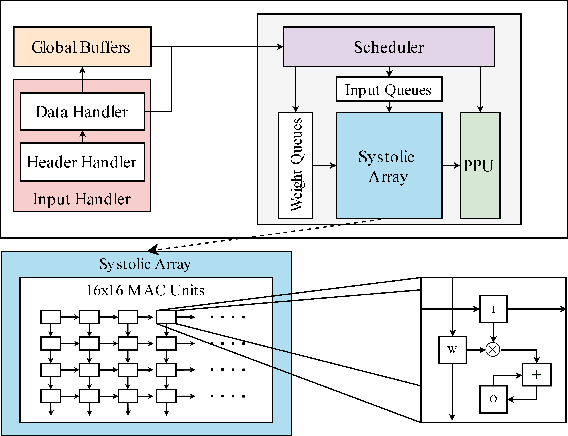
Edge computing devices inherently face tight resource constraints, which is especially apparent when deploying Deep Neural Networks (DNN) with high memory and compute demands. FPGAs are commonly available in edge devices. Since these reconfigurable circuits can achieve higher throughput and lower power consumption than general purpose processors, they are especially well-suited for DNN acceleration. However, existing solutions for designing FPGA-based DNN accelerators for edge devices come with high development overheads, given the cost of repeated FPGA synthesis passes, reimplementation in a Hardware Description Language (HDL) of the simulated design, and accelerator system integration. In this paper we propose SECDA, a new hardware/software co-design methodology to reduce design time of optimized DNN inference accelerators on edge devices with FPGAs. SECDA combines cost-effective SystemC simulation with hardware execution, streamlining design space exploration and the development process via reduced design evaluation time. As a case study, we use SECDA to efficiently develop two different DNN accelerator designs on a PYNQ-Z1 board, a platform that includes an edge FPGA. We quickly and iteratively explore the system's hardware/software stack, while identifying and mitigating performance bottlenecks. We evaluate the two accelerator designs with four common DNN models, achieving an average performance speedup across models of up to 3.5$\times$ with a 2.9$\times$ reduction in energy consumption over CPU-only inference. Our code is available at https://github.com/gicLAB/SECDA