 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoTAcc: A Pipeline for End-to-End Acceleration of Power-of-Two Quantized DNNs
May 07, 2026Power-of-two (PoT) quantization significantly reduces the size of deep neural networks (DNNs) and replaces multiplications with bit-shift operations for inference. Prior work has shown that PoT-quantized DNNs can preserve accuracy for tasks such as image classification; however, their performance on resource-constrained edge devices remains insufficiently understood. While general-purpose edge CPUs and GPUs do not provide optimized backends for bit-shift operations, custom hardware accelerators can better exploit PoT quantization by implementing dedicated shift-based processing elements. However, deploying PoT-quantized models on such accelerators is challenging due to limited support in existing inference frameworks. In addition, the impact of different PoT quantization strategies on hardware design, performance, and energy efficiency during full inference has not been systematically explored. To address these challenges, we propose PoTAcc, an open-source end-to-end pipeline for accelerating and evaluating PoT-quantized DNNs on resource-constrained edge devices. PoTAcc enables seamless preparation and deployment of PoT-quantized models via TensorFlow Lite (TFLite) across heterogeneous platforms, including CPU-only systems and hybrid CPU-FPGA systems with custom accelerators. We design shift-based processing element (shift-PE) accelerators for three PoT quantization methods and implement them on two FPGA platforms. We evaluate accuracy, performance, energy efficiency, and resource utilization across a range of models, including CNNs and Transformer-based architectures. Results show that our CPU-accelerator design achieves up to 3.6x speedup and 78% energy reduction compared to CPU-only execution for PoT-quantized DNNs on PYNQ-Z2 and Kria boards. The code will be publicly released at https://github.com/gicLAB/PoTAcc
NeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator
Apr 26, 2024



Graph Neural Networks (GNNs) are emerging as a formidable tool for processing non-euclidean data across various domains, ranging from social network analysis to bioinformatics. Despite their effectiveness, their adoption has not been pervasive because of scalability challenges associated with large-scale graph datasets, particularly when leveraging message passing. To tackle these challenges, we introduce NeuraChip, a novel GNN spatial accelerator based on Gustavson's algorithm. NeuraChip decouples the multiplication and addition computations in sparse matrix multiplication. This separation allows for independent exploitation of their unique data dependencies, facilitating efficient resource allocation. We introduce a rolling eviction strategy to mitigate data idling in on-chip memory as well as address the prevalent issue of memory bloat in sparse graph computations. Furthermore, the compute resource load balancing is achieved through a dynamic reseeding hash-based mapping, ensuring uniform utilization of computing resources agnostic of sparsity patterns. Finally, we present NeuraSim, an open-source, cycle-accurate, multi-threaded, modular simulator for comprehensive performance analysis. Overall, NeuraChip presents a significant improvement, yielding an average speedup of 22.1x over Intel's MKL, 17.1x over NVIDIA's cuSPARSE, 16.7x over AMD's hipSPARSE, and 1.5x over prior state-of-the-art SpGEMM accelerator and 1.3x over GNN accelerator. The source code for our open-sourced simulator and performance visualizer is publicly accessible on GitHub https://neurachip.us
SECDA: Efficient Hardware/Software Co-Design of FPGA-based DNN Accelerators for Edge Inference
Oct 01, 2021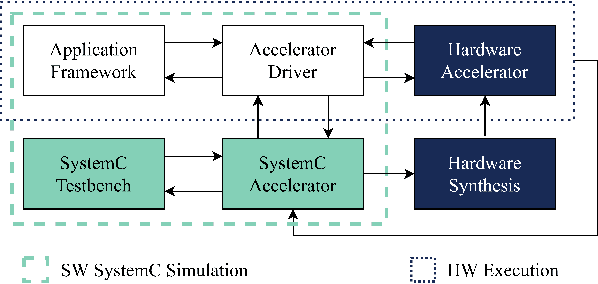
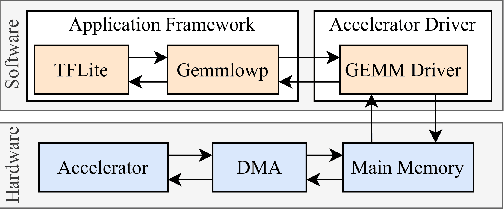
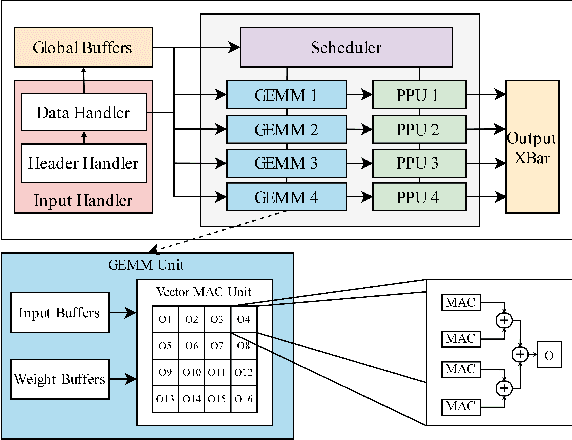
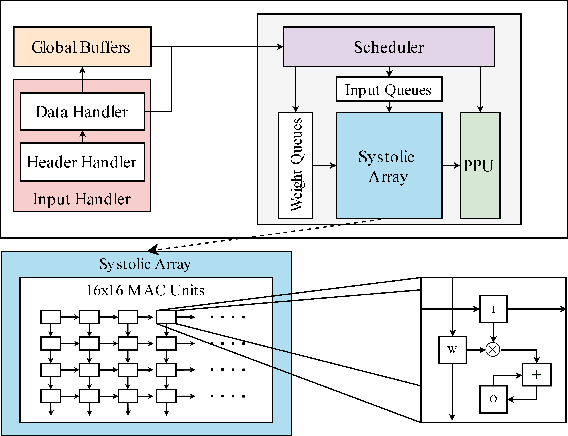
Edge computing devices inherently face tight resource constraints, which is especially apparent when deploying Deep Neural Networks (DNN) with high memory and compute demands. FPGAs are commonly available in edge devices. Since these reconfigurable circuits can achieve higher throughput and lower power consumption than general purpose processors, they are especially well-suited for DNN acceleration. However, existing solutions for designing FPGA-based DNN accelerators for edge devices come with high development overheads, given the cost of repeated FPGA synthesis passes, reimplementation in a Hardware Description Language (HDL) of the simulated design, and accelerator system integration. In this paper we propose SECDA, a new hardware/software co-design methodology to reduce design time of optimized DNN inference accelerators on edge devices with FPGAs. SECDA combines cost-effective SystemC simulation with hardware execution, streamlining design space exploration and the development process via reduced design evaluation time. As a case study, we use SECDA to efficiently develop two different DNN accelerator designs on a PYNQ-Z1 board, a platform that includes an edge FPGA. We quickly and iteratively explore the system's hardware/software stack, while identifying and mitigating performance bottlenecks. We evaluate the two accelerator designs with four common DNN models, achieving an average performance speedup across models of up to 3.5$\times$ with a 2.9$\times$ reduction in energy consumption over CPU-only inference. Our code is available at https://github.com/gicLAB/SECDA