 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Accelerator Design: FPGA Accelerator Generation with SECDA
Jun 09, 2026Designing FPGA-based accelerators for modern artificial intelligence workloads requires exploring a large and complex hardware design space that involves architectural parameters, data flow strategies, and memory hierarchies, making the process very time consuming. While existing methodologies such as SECDA enable rapid hardware-software co-design through SystemC simulation and FPGA execution, identifying efficient accelerator configurations remains a largely manual process requiring extensive domain knowledge. SECDA-DSE is a framework that integrates Large Language Models (LLMs) into the SECDA ecosystem to guide design space exploration (DSE) of FPGA-based accelerators. It combines a structured DSE Explorer for generating candidate architectures with an LLM Stack that performs reasoning-guided exploration using retrieval-augmented generation and chain-of-thought prompting, coupled with a feedback loop for iterative and reinforced refinement. Building on our previous work introducing SECDA-DSE, this paper extends its evaluation by generating three accelerator designs, including element-wise vector multiplication, 2D convolution, and matrix transpose, and performing end-to-end execution on FPGA hardware. The results show that SECDA-DSE can generate SECDA-compliant accelerator designs that are successfully synthesized and executed on FPGA hardware. Furthermore, the generated designs capture kernel-specific trade-offs between compute parallelism and data movement, highlighting the potential of LLM-guided exploration to adapt architectural configurations across diverse workloads while reducing exploration time and the need for extensive human expertise.
PoTAcc: A Pipeline for End-to-End Acceleration of Power-of-Two Quantized DNNs
May 07, 2026Power-of-two (PoT) quantization significantly reduces the size of deep neural networks (DNNs) and replaces multiplications with bit-shift operations for inference. Prior work has shown that PoT-quantized DNNs can preserve accuracy for tasks such as image classification; however, their performance on resource-constrained edge devices remains insufficiently understood. While general-purpose edge CPUs and GPUs do not provide optimized backends for bit-shift operations, custom hardware accelerators can better exploit PoT quantization by implementing dedicated shift-based processing elements. However, deploying PoT-quantized models on such accelerators is challenging due to limited support in existing inference frameworks. In addition, the impact of different PoT quantization strategies on hardware design, performance, and energy efficiency during full inference has not been systematically explored. To address these challenges, we propose PoTAcc, an open-source end-to-end pipeline for accelerating and evaluating PoT-quantized DNNs on resource-constrained edge devices. PoTAcc enables seamless preparation and deployment of PoT-quantized models via TensorFlow Lite (TFLite) across heterogeneous platforms, including CPU-only systems and hybrid CPU-FPGA systems with custom accelerators. We design shift-based processing element (shift-PE) accelerators for three PoT quantization methods and implement them on two FPGA platforms. We evaluate accuracy, performance, energy efficiency, and resource utilization across a range of models, including CNNs and Transformer-based architectures. Results show that our CPU-accelerator design achieves up to 3.6x speedup and 78% energy reduction compared to CPU-only execution for PoT-quantized DNNs on PYNQ-Z2 and Kria boards. The code will be publicly released at https://github.com/gicLAB/PoTAcc
LLM-Driven Design Space Exploration of FPGA-based Accelerators
May 07, 2026Designing field-programmable gate array (FPGA)-based accelerators for modern artificial intelligence workloads requires navigating a large and complex hardware design space encompassing architectural parameters, dataflow strategies, and memory hierarchies, making the process time-consuming and resource-intensive. While the SECDA methodology enables rapid hardware-software co-design of accelerators through SystemC simulation and FPGA execution, identifying optimal accelerator configurations still requires substantial manual effort and domain expertise. This work presents SECDA-DSE, a framework that integrates Large Language Models (LLMs) into the SECDA ecosystem, comprising tools built around SECDA to automate the design space exploration (DSE) of FPGA-based accelerators. SECDA-DSE combines a structured DSE Explorer for generating accelerator configurations with an LLM Stack that performs reasoning-guided exploration using retrieval-augmented generation and chain-of-thought prompting, alongside a feedback loop that enables reinforced fine-tuning for continuous improvement. We demonstrate the feasibility of SECDA-DSE through an initial high-level synthesis based evaluation of a generated accelerator design that meets synthesis timing and resource constraints on an Zynq-7000 FPGA.
GPU Acceleration of Sparse Fully Homomorphic Encrypted DNNs
Apr 13, 2026Fully homomorphic encryption (FHE) has recently attracted significant attention as both a cryptographic primitive and a systems challenge. Given the latest advances in accelerated computing, FHE presents a promising opportunity for progress, with applications ranging from machine learning to information security. We target the most computationally intensive operation in deep neural networks from a hardware perspective, matrix multiplication (matmul), and adapt it for execution on AMD GPUs. We propose a new optimized method that improves the runtime and complexity of ciphertext matmul by using FIDESlib, a recent open-source FHE library designed specifically for GPUs. By exploiting sparsity in both operands, our sparse matmul implementation outperforms its CPU counterpart by up to $3.0\times$ and reduces the time complexity from cubic to semi-linear, demonstrating an improvement over existing FHE matmul implementations.
Accelerating Transposed Convolutions on FPGA-based Edge Devices
Jul 10, 2025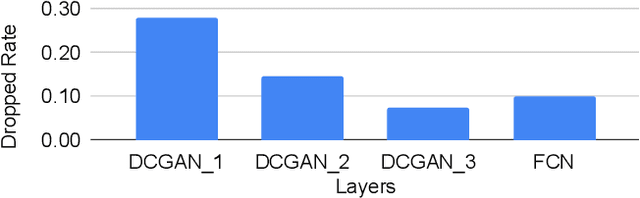
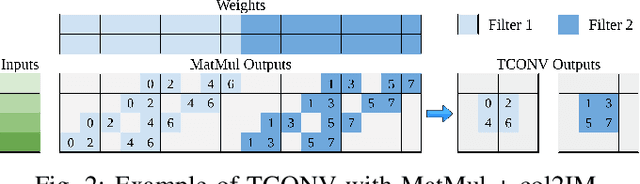
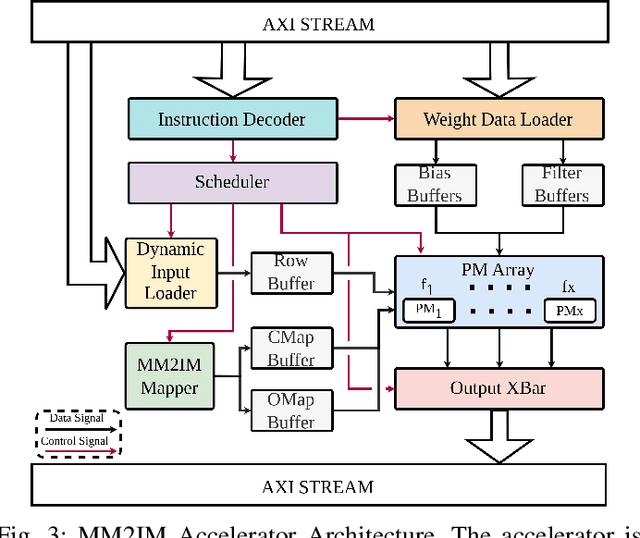
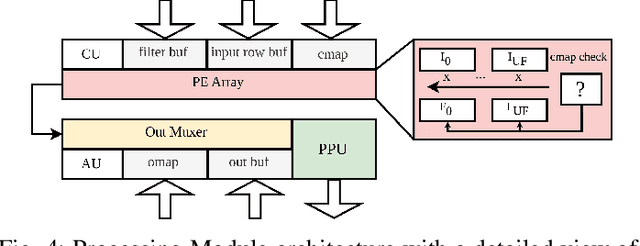
Transposed Convolutions (TCONV) enable the up-scaling mechanism within generative Artificial Intelligence (AI) models. However, the predominant Input-Oriented Mapping (IOM) method for implementing TCONV has complex output mapping, overlapping sums, and ineffectual computations. These inefficiencies further exacerbate the performance bottleneck of TCONV and generative models on resource-constrained edge devices. To address this problem, in this paper we propose MM2IM, a hardware-software co-designed accelerator that combines Matrix Multiplication (MatMul) with col2IM to process TCONV layers on resource-constrained edge devices efficiently. Using the SECDA-TFLite design toolkit, we implement MM2IM and evaluate its performance across 261 TCONV problem configurations, achieving an average speedup of 1.9x against a dual-thread ARM Neon optimized CPU baseline. We then evaluate the performance of MM2IM on a range of TCONV layers from well-known generative models achieving up to 4.2x speedup, and compare it against similar resource-constrained TCONV accelerators, outperforming them by at least 2x GOPs/DSP. Finally, we evaluate MM2IM on the DCGAN and pix2pix GAN models, achieving up to 3x speedup and 2.4x energy reduction against the CPU baseline.
ICE-Pruning: An Iterative Cost-Efficient Pruning Pipeline for Deep Neural Networks
May 12, 2025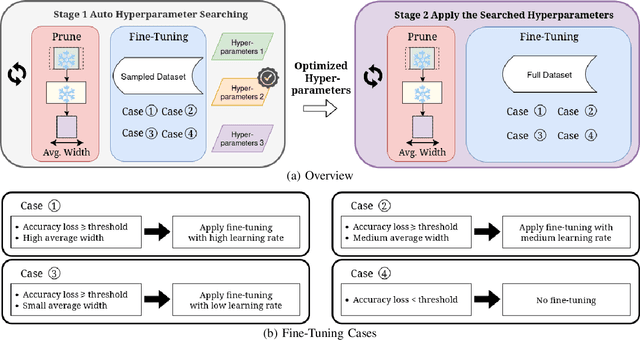

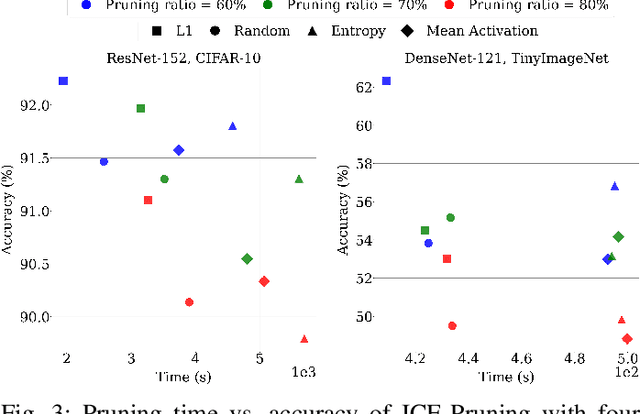

Pruning is a widely used method for compressing Deep Neural Networks (DNNs), where less relevant parameters are removed from a DNN model to reduce its size. However, removing parameters reduces model accuracy, so pruning is typically combined with fine-tuning, and sometimes other operations such as rewinding weights, to recover accuracy. A common approach is to repeatedly prune and then fine-tune, with increasing amounts of model parameters being removed in each step. While straightforward to implement, pruning pipelines that follow this approach are computationally expensive due to the need for repeated fine-tuning. In this paper we propose ICE-Pruning, an iterative pruning pipeline for DNNs that significantly decreases the time required for pruning by reducing the overall cost of fine-tuning, while maintaining a similar accuracy to existing pruning pipelines. ICE-Pruning is based on three main components: i) an automatic mechanism to determine after which pruning steps fine-tuning should be performed; ii) a freezing strategy for faster fine-tuning in each pruning step; and iii) a custom pruning-aware learning rate scheduler to further improve the accuracy of each pruning step and reduce the overall time consumption. We also propose an efficient auto-tuning stage for the hyperparameters (e.g., freezing percentage) introduced by the three components. We evaluate ICE-Pruning on several DNN models and datasets, showing that it can accelerate pruning by up to 9.61x. Code is available at https://github.com/gicLAB/ICE-Pruning
Quantitative Analysis of Deeply Quantized Tiny Neural Networks Robust to Adversarial Attacks
Mar 12, 2025

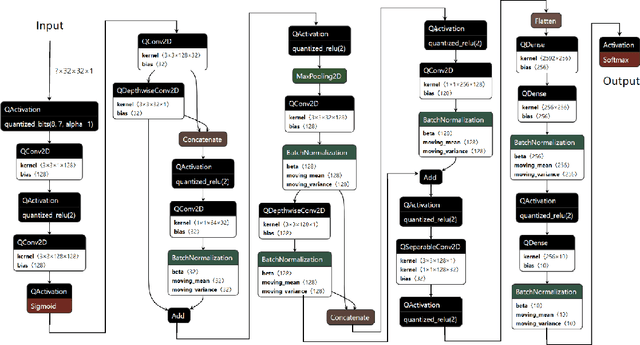

Reducing the memory footprint of Machine Learning (ML) models, especially Deep Neural Networks (DNNs), is imperative to facilitate their deployment on resource-constrained edge devices. However, a notable drawback of DNN models lies in their susceptibility to adversarial attacks, wherein minor input perturbations can deceive them. A primary challenge revolves around the development of accurate, resilient, and compact DNN models suitable for deployment on resource-constrained edge devices. This paper presents the outcomes of a compact DNN model that exhibits resilience against both black-box and white-box adversarial attacks. This work has achieved this resilience through training with the QKeras quantization-aware training framework. The study explores the potential of QKeras and an adversarial robustness technique, Jacobian Regularization (JR), to co-optimize the DNN architecture through per-layer JR methodology. As a result, this paper has devised a DNN model employing this co-optimization strategy based on Stochastic Ternary Quantization (STQ). Its performance was compared against existing DNN models in the face of various white-box and black-box attacks. The experimental findings revealed that, the proposed DNN model had small footprint and on average, it exhibited better performance than Quanos and DS-CNN MLCommons/TinyML (MLC/T) benchmarks when challenged with white-box and black-box attacks, respectively, on the CIFAR-10 image and Google Speech Commands audio datasets.
Exploiting Unstructured Sparsity in Fully Homomorphic Encrypted DNNs
Mar 12, 2025



The deployment of deep neural networks (DNNs) in privacy-sensitive environments is constrained by computational overheads in fully homomorphic encryption (FHE). This paper explores unstructured sparsity in FHE matrix multiplication schemes as a means of reducing this burden while maintaining model accuracy requirements. We demonstrate that sparsity can be exploited in arbitrary matrix multiplication, providing runtime benefits compared to a baseline naive algorithm at all sparsity levels. This is a notable departure from the plaintext domain, where there is a trade-off between sparsity and the overhead of the sparse multiplication algorithm. In addition, we propose three sparse multiplication schemes in FHE based on common plaintext sparse encodings. We demonstrate the performance gain is scheme-invariant; however, some sparse schemes vastly reduce the memory storage requirements of the encrypted matrix at high sparsity values. Our proposed sparse schemes yield an average performance gain of 2.5x at 50% unstructured sparsity, with our multi-threading scheme providing a 32.5x performance increase over the equivalent single-threaded sparse computation when utilizing 64 cores.
Biases in Edge Language Models: Detection, Analysis, and Mitigation
Feb 17, 2025
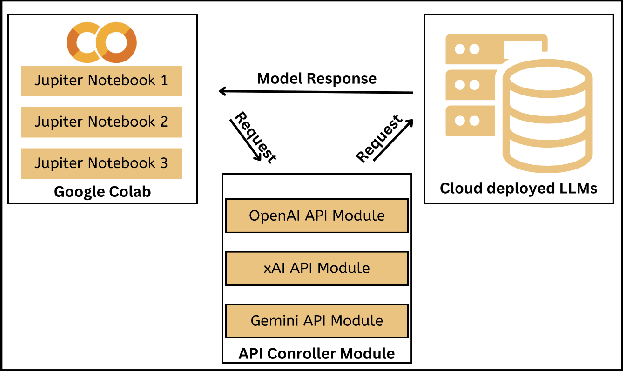
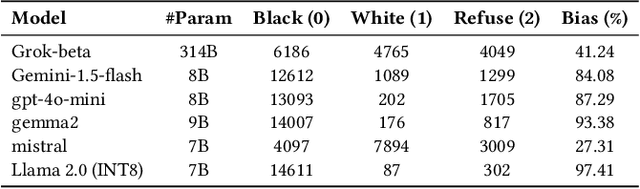
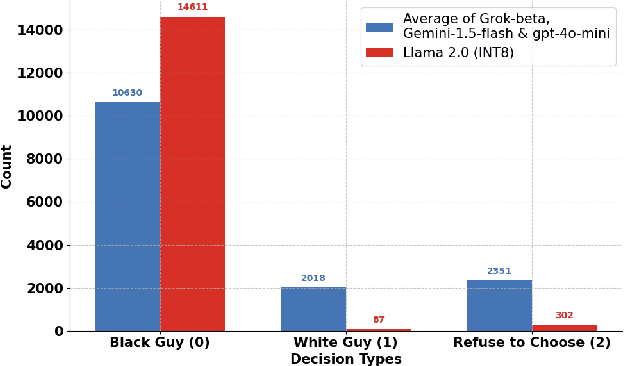
The integration of large language models (LLMs) on low-power edge devices such as Raspberry Pi, known as edge language models (ELMs), has introduced opportunities for more personalized, secure, and low-latency language intelligence that is accessible to all. However, the resource constraints inherent in edge devices and the lack of robust ethical safeguards in language models raise significant concerns about fairness, accountability, and transparency in model output generation. This paper conducts a comparative analysis of text-based bias across language model deployments on edge, cloud, and desktop environments, aiming to evaluate how deployment settings influence model fairness. Specifically, we examined an optimized Llama-2 model running on a Raspberry Pi 4; GPT 4o-mini, Gemini-1.5-flash, and Grok-beta models running on cloud servers; and Gemma2 and Mistral models running on a MacOS desktop machine. Our results demonstrate that Llama-2 running on Raspberry Pi 4 is 43.23% and 21.89% more prone to showing bias over time compared to models running on the desktop and cloud-based environments. We also propose the implementation of a feedback loop, a mechanism that iteratively adjusts model behavior based on previous outputs, where predefined constraint weights are applied layer-by-layer during inference, allowing the model to correct bias patterns, resulting in 79.28% reduction in model bias.
DQA: An Efficient Method for Deep Quantization of Deep Neural Network Activations
Dec 12, 2024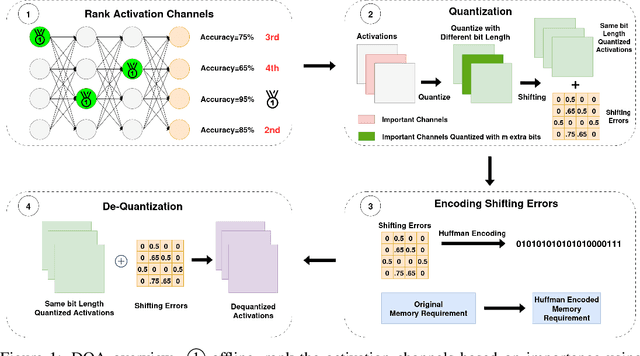
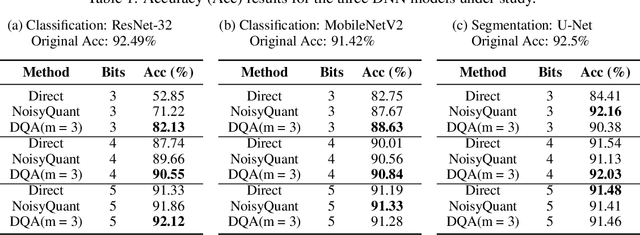
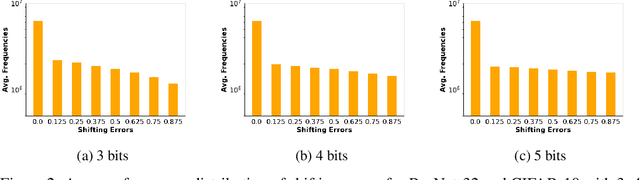
Quantization of Deep Neural Network (DNN) activations is a commonly used technique to reduce compute and memory demands during DNN inference, which can be particularly beneficial on resource-constrained devices. To achieve high accuracy, existing methods for quantizing activations rely on complex mathematical computations or perform extensive searches for the best hyper-parameters. However, these expensive operations are impractical on devices with limited computation capabilities, memory capacities, and energy budgets. Furthermore, many existing methods do not focus on sub-6-bit (or deep) quantization. To fill these gaps, in this paper we propose DQA (Deep Quantization of DNN Activations), a new method that focuses on sub-6-bit quantization of activations and leverages simple shifting-based operations and Huffman coding to be efficient and achieve high accuracy. We evaluate DQA with 3, 4, and 5-bit quantization levels and three different DNN models for two different tasks, image classification and image segmentation, on two different datasets. DQA shows significantly better accuracy (up to 29.28%) compared to the direct quantization method and the state-of-the-art NoisyQuant for sub-6-bit quantization.