 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Quantization Tuning for ONNX Models
Jul 16, 2025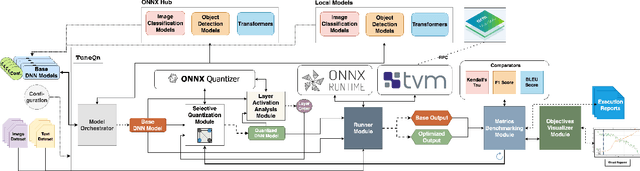


Quantization is a process that reduces the precision of deep neural network models to lower model size and computational demands, often at the cost of accuracy. However, fully quantized models may exhibit sub-optimal performance below acceptable levels and face deployment challenges on low-end hardware accelerators due to practical constraints. To address these issues, quantization can be selectively applied to only a subset of layers, but selecting which layers to exclude is non-trivial. To this direction, we propose TuneQn, a suite enabling selective quantization, deployment and execution of ONNX models across various CPU and GPU devices, combined with profiling and multi-objective optimization. TuneQn generates selectively quantized ONNX models, deploys them on different hardware, measures performance on metrics like accuracy and size, performs Pareto Front minimization to identify the best model candidate and visualizes the results. To demonstrate the effectiveness of TuneQn, we evaluated TuneQn on four ONNX models with two quantization settings across CPU and GPU devices. As a result, we demonstrated that our utility effectively performs selective quantization and tuning, selecting ONNX model candidates with up to a $54.14$% reduction in accuracy loss compared to the fully quantized model, and up to a $72.9$% model size reduction compared to the original model.
OODTE: A Differential Testing Engine for the ONNX Optimizer
May 03, 2025With $700$ stars on GitHub and part of the official ONNX repository, the ONNX Optimizer consists of the standard method to apply graph-based optimizations on ONNX models. However, its ability to preserve model accuracy across optimizations, has not been rigorously explored. We propose OODTE, a utility to automatically and thoroughly assess the correctness of the ONNX Optimizer. OODTE follows a simple, yet effective differential testing and evaluation approach that can be easily adopted to other compiler optimizers. In particular, OODTE utilizes a number of ONNX models, then optimizes them and executes both the original and the optimized variants across a user-defined set of inputs, while automatically logging any issues with the optimization process. Finally, for successfully optimized models, OODTE compares the results, and, if any accuracy deviations are observed, it iteratively repeats the process for each pass of the ONNX Optimizer, to localize the root cause of the differences observed. Using OODTE, we sourced well-known $130$ models from the official ONNX Model Hub, used for a wide variety of tasks (classification, object detection, semantic segmentation, text summarization, question and answering, sentiment analysis) from the official ONNX model hub. We detected 15 issues, 14 of which were previously unknown, associated with optimizer crashes and accuracy deviations. We also observed $9.2$% of all model instances presenting issues leading into the crash of the optimizer, or the generation of an invalid model while using the primary optimizer strategies. In addition, $30$% of the classification models presented accuracy differences across the original and the optimized model variants, while $16.6$% of semantic segmentation and object detection models are also affected, at least to a limited extent.
Fix-Con: Automatic Fault Localization and Repair of Deep Learning Model Conversions
Dec 22, 2023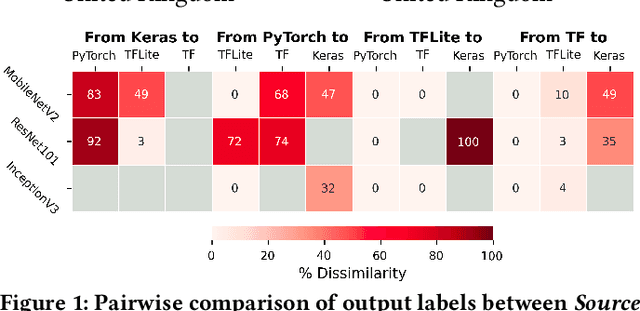
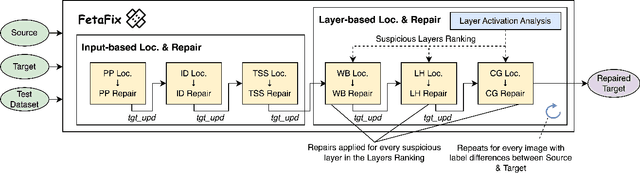
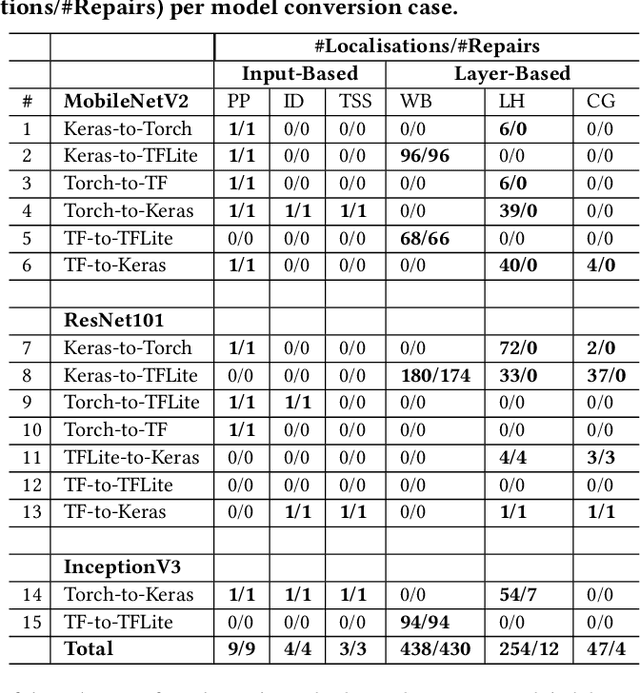
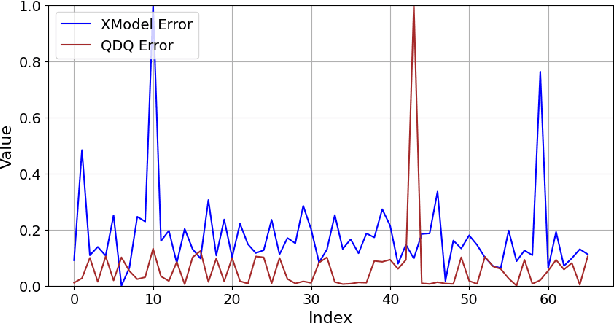
Converting deep learning models between frameworks is a common step to maximize model compatibility across devices and leverage optimization features that may be exclusively provided in one deep learning framework. However, this conversion process may be riddled with bugs, making the converted models either undeployable or problematic, considerably degrading their prediction correctness. We propose an automated approach for fault localization and repair, Fix-Con, during model conversion between deep learning frameworks. Fix-Con is capable of detecting and fixing faults introduced in model input, parameters, hyperparameters, and the model graph during conversion. Fix-Con uses a set of fault types mined from surveying conversion issues raised to localize potential conversion faults in the converted target model, and then repairs them appropriately, e.g. replacing the parameters of the target model with those from the source model. This is done iteratively for every image in the dataset with output label differences between the source model and the converted target model until all differences are resolved. We evaluate the effectiveness of Fix-Con in fixing model conversion bugs of three widely used image recognition models converted across four different deep learning frameworks. Overall, Fix-Con was able to either completely repair, or significantly improve the performance of 14 out of the 15 erroneous conversion cases.
MutateNN: Mutation Testing of Image Recognition Models Deployed on Hardware Accelerators
Jun 21, 2023With the research advancement of Artificial Intelligence in the last years, there are new opportunities to mitigate real-world problems and advance technologically. Image recognition models in particular, are assigned with perception tasks to mitigate complex real-world challenges and lead to new solutions. Furthermore, the computational complexity and demand for resources of such models has also increased. To mitigate this, model optimization and hardware acceleration has come into play, but effectively integrating such concepts is a challenging and error-prone process. In order to allow developers and researchers to explore the robustness of deep learning image recognition models deployed on different hardware acceleration devices, we propose MutateNN, a tool that provides mutation testing and analysis capabilities for that purpose. To showcase its capabilities, we utilized 21 mutations for 7 widely-known pre-trained deep neural network models. We deployed our mutants on 4 different devices of varying computational capabilities and observed discrepancies in mutants related to conditional operations, as well as some unstable behaviour with those related to arithmetic types.
Fault Localization for Framework Conversions of Image Recognition Models
Jun 10, 2023



When deploying Deep Neural Networks (DNNs), developers often convert models from one deep learning framework to another (e.g., TensorFlow to PyTorch). However, this process is error-prone and can impact target model accuracy. To identify the extent of such impact, we perform and briefly present a differential analysis against three DNNs used for image recognition (MobileNetV2, ResNet101, and InceptionV3), converted across four well-known deep learning frameworks (PyTorch, Keras, TensorFlow (TF), and TFLite), which revealed numerous model crashes and output label discrepancies of up to 100%. To mitigate such errors, we present a novel approach towards fault localization and repair of buggy deep learning framework conversions, focusing on pre-trained image recognition models. Our technique consists of four primary stages of analysis: 1) conversion tools, 2) model parameters, 3) model hyperparameters, and 4) graph representation. In addition, we propose a number of strategies towards fault repair of the faults detected. We implement our technique on top of Apache TVM deep learning compiler, and we test it by conducting a preliminary fault localization analysis for the conversion of InceptionV3, from TF to TFLite. Our approach detected that the tf2onnx tool used in the conversion process introduced precision errors to model weights for convolutional layers in particular, which negatively affected the model accuracy. We then repaired the target model by replacing the affected weights with those from source model.
A Differential Testing Framework to Evaluate Image Recognition Model Robustness
Jun 05, 2023



Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and TPUs for fast, timely processing. Failure in real-time image recognition tasks can occur due to sub-optimal mapping on hardware accelerators during model deployment, which may lead to timing uncertainty and erroneous behavior. Mapping on hardware accelerators is done through multiple software components like deep learning frameworks, compilers, device libraries, that we refer to as the computational environment. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment, as the impact of parameters like deep learning frameworks, compiler optimizations, and hardware devices on model performance and correctness is not well understood. In this paper we present a differential testing framework, which allows deep learning model variant generation, execution, differential analysis and testing for a number of computational environment parameters. Using our framework, we conduct an empirical study of robustness analysis of three popular image recognition models using the ImageNet dataset, assessing the impact of changing deep learning frameworks, compiler optimizations, and hardware devices. We report the impact in terms of misclassifications and inference time differences across different settings. In total, we observed up to 72% output label differences across deep learning frameworks, and up to 82% unexpected performance degradation in terms of inference time, when applying compiler optimizations. Using the analysis tools in our framework, we also perform fault analysis to understand the reasons for the observed differences.
Exploring Effects of Computational Parameter Changes to Image Recognition Systems
Nov 02, 2022Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and FPGAs for fast, timely processing. Failure in real-time image recognition tasks can occur due to incorrect mapping on hardware accelerators, which may lead to timing uncertainty and incorrect behavior. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment as parameters like deep learning frameworks, compiler optimizations for code generation, and hardware devices are not regulated with varying impact on model performance and correctness. In this paper we conduct robustness analysis of four popular image recognition models (MobileNetV2, ResNet101V2, DenseNet121 and InceptionV3) with the ImageNet dataset, assessing the impact of the following parameters in the model's computational environment: (1) deep learning frameworks; (2) compiler optimizations; and (3) hardware devices. We report sensitivity of model performance in terms of output label and inference time for changes in each of these environment parameters. We find that output label predictions for all four models are sensitive to choice of deep learning framework (by up to 57%) and insensitive to other parameters. On the other hand, model inference time was affected by all environment parameters with changes in hardware device having the most effect. The extent of effect was not uniform across models.