 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating PoT Quantization on Edge Devices
Sep 30, 2024



Non-uniform quantization, such as power-of-two (PoT) quantization, matches data distributions better than uniform quantization, which reduces the quantization error of Deep Neural Networks (DNNs). PoT quantization also allows bit-shift operations to replace multiplications, but there are limited studies on the efficiency of shift-based accelerators for PoT quantization. Furthermore, existing pipelines for accelerating PoT-quantized DNNs on edge devices are not open-source. In this paper, we first design shift-based processing elements (shift-PE) for different PoT quantization methods and evaluate their efficiency using synthetic benchmarks. Then we design a shift-based accelerator using our most efficient shift-PE and propose PoTAcc, an open-source pipeline for end-to-end acceleration of PoT-quantized DNNs on resource-constrained edge devices. Using PoTAcc, we evaluate the performance of our shift-based accelerator across three DNNs. On average, it achieves a 1.23x speedup and 1.24x energy reduction compared to a multiplier-based accelerator, and a 2.46x speedup and 1.83x energy reduction compared to CPU-only execution. Our code is available at https://github.com/gicLAB/PoTAcc
Designing Efficient LLM Accelerators for Edge Devices
Aug 01, 2024
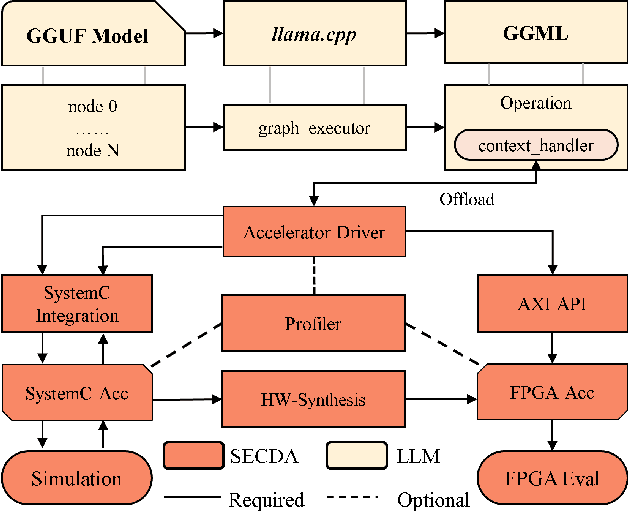
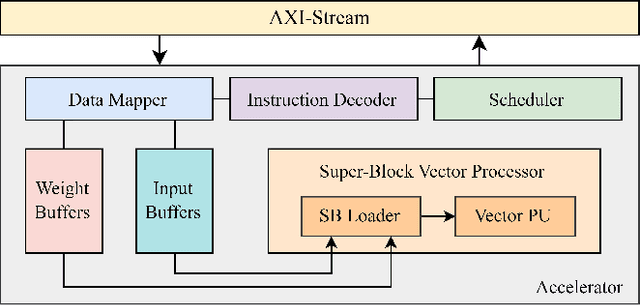
The increase in open-source availability of Large Language Models (LLMs) has enabled users to deploy them on more and more resource-constrained edge devices to reduce reliance on network connections and provide more privacy. However, the high computation and memory demands of LLMs make their execution on resource-constrained edge devices challenging and inefficient. To address this issue, designing new and efficient edge accelerators for LLM inference is crucial. FPGA-based accelerators are ideal for LLM acceleration due to their reconfigurability, as they enable model-specific optimizations and higher performance per watt. However, creating and integrating FPGA-based accelerators for LLMs (particularly on edge devices) has proven challenging, mainly due to the limited hardware design flows for LLMs in existing FPGA platforms. To tackle this issue, in this paper we first propose a new design platform, named SECDA-LLM, that utilizes the SECDA methodology to streamline the process of designing, integrating, and deploying efficient FPGA-based LLM accelerators for the llama.cpp inference framework. We then demonstrate, through a case study, the potential benefits of SECDA-LLM by creating a new MatMul accelerator that supports block floating point quantized operations for LLMs. Our initial accelerator design, deployed on the PYNQ-Z1 board, reduces latency 1.7 seconds per token or ~2 seconds per word) by 11x over the dual-core Arm NEON-based CPU execution for the TinyLlama model.