 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Transposed Convolutions on FPGA-based Edge Devices
Jul 10, 2025Transposed Convolutions (TCONV) enable the up-scaling mechanism within generative Artificial Intelligence (AI) models. However, the predominant Input-Oriented Mapping (IOM) method for implementing TCONV has complex output mapping, overlapping sums, and ineffectual computations. These inefficiencies further exacerbate the performance bottleneck of TCONV and generative models on resource-constrained edge devices. To address this problem, in this paper we propose MM2IM, a hardware-software co-designed accelerator that combines Matrix Multiplication (MatMul) with col2IM to process TCONV layers on resource-constrained edge devices efficiently. Using the SECDA-TFLite design toolkit, we implement MM2IM and evaluate its performance across 261 TCONV problem configurations, achieving an average speedup of 1.9x against a dual-thread ARM Neon optimized CPU baseline. We then evaluate the performance of MM2IM on a range of TCONV layers from well-known generative models achieving up to 4.2x speedup, and compare it against similar resource-constrained TCONV accelerators, outperforming them by at least 2x GOPs/DSP. Finally, we evaluate MM2IM on the DCGAN and pix2pix GAN models, achieving up to 3x speedup and 2.4x energy reduction against the CPU baseline.
Accelerating PoT Quantization on Edge Devices
Sep 30, 2024



Non-uniform quantization, such as power-of-two (PoT) quantization, matches data distributions better than uniform quantization, which reduces the quantization error of Deep Neural Networks (DNNs). PoT quantization also allows bit-shift operations to replace multiplications, but there are limited studies on the efficiency of shift-based accelerators for PoT quantization. Furthermore, existing pipelines for accelerating PoT-quantized DNNs on edge devices are not open-source. In this paper, we first design shift-based processing elements (shift-PE) for different PoT quantization methods and evaluate their efficiency using synthetic benchmarks. Then we design a shift-based accelerator using our most efficient shift-PE and propose PoTAcc, an open-source pipeline for end-to-end acceleration of PoT-quantized DNNs on resource-constrained edge devices. Using PoTAcc, we evaluate the performance of our shift-based accelerator across three DNNs. On average, it achieves a 1.23x speedup and 1.24x energy reduction compared to a multiplier-based accelerator, and a 2.46x speedup and 1.83x energy reduction compared to CPU-only execution. Our code is available at https://github.com/gicLAB/PoTAcc
Designing Efficient LLM Accelerators for Edge Devices
Aug 01, 2024
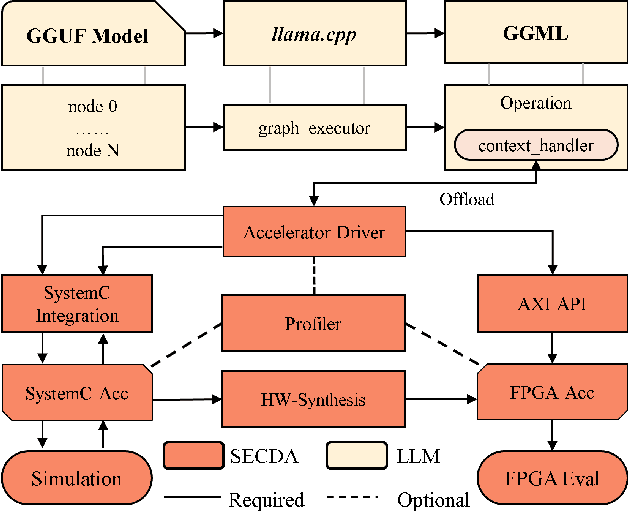
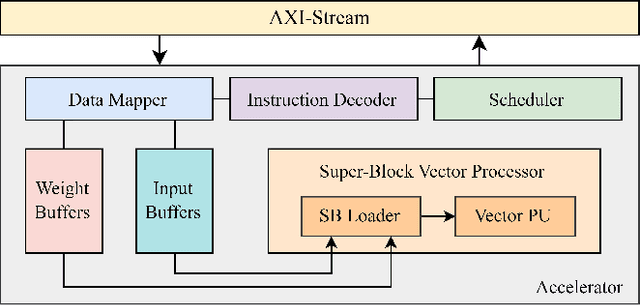
The increase in open-source availability of Large Language Models (LLMs) has enabled users to deploy them on more and more resource-constrained edge devices to reduce reliance on network connections and provide more privacy. However, the high computation and memory demands of LLMs make their execution on resource-constrained edge devices challenging and inefficient. To address this issue, designing new and efficient edge accelerators for LLM inference is crucial. FPGA-based accelerators are ideal for LLM acceleration due to their reconfigurability, as they enable model-specific optimizations and higher performance per watt. However, creating and integrating FPGA-based accelerators for LLMs (particularly on edge devices) has proven challenging, mainly due to the limited hardware design flows for LLMs in existing FPGA platforms. To tackle this issue, in this paper we first propose a new design platform, named SECDA-LLM, that utilizes the SECDA methodology to streamline the process of designing, integrating, and deploying efficient FPGA-based LLM accelerators for the llama.cpp inference framework. We then demonstrate, through a case study, the potential benefits of SECDA-LLM by creating a new MatMul accelerator that supports block floating point quantized operations for LLMs. Our initial accelerator design, deployed on the PYNQ-Z1 board, reduces latency 1.7 seconds per token or ~2 seconds per word) by 11x over the dual-core Arm NEON-based CPU execution for the TinyLlama model.
SECDA: Efficient Hardware/Software Co-Design of FPGA-based DNN Accelerators for Edge Inference
Oct 01, 2021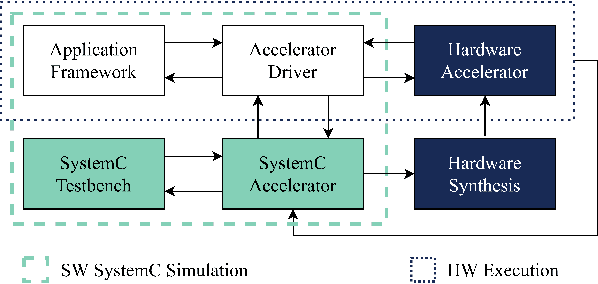
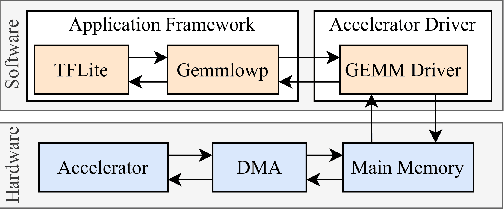
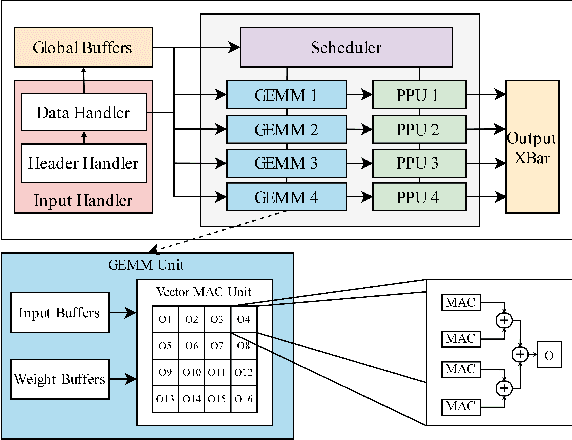
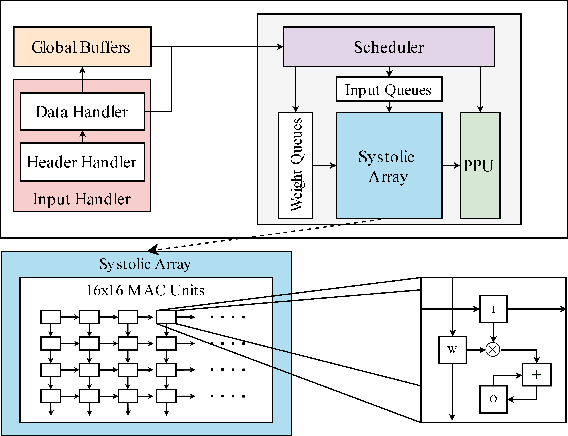
Edge computing devices inherently face tight resource constraints, which is especially apparent when deploying Deep Neural Networks (DNN) with high memory and compute demands. FPGAs are commonly available in edge devices. Since these reconfigurable circuits can achieve higher throughput and lower power consumption than general purpose processors, they are especially well-suited for DNN acceleration. However, existing solutions for designing FPGA-based DNN accelerators for edge devices come with high development overheads, given the cost of repeated FPGA synthesis passes, reimplementation in a Hardware Description Language (HDL) of the simulated design, and accelerator system integration. In this paper we propose SECDA, a new hardware/software co-design methodology to reduce design time of optimized DNN inference accelerators on edge devices with FPGAs. SECDA combines cost-effective SystemC simulation with hardware execution, streamlining design space exploration and the development process via reduced design evaluation time. As a case study, we use SECDA to efficiently develop two different DNN accelerator designs on a PYNQ-Z1 board, a platform that includes an edge FPGA. We quickly and iteratively explore the system's hardware/software stack, while identifying and mitigating performance bottlenecks. We evaluate the two accelerator designs with four common DNN models, achieving an average performance speedup across models of up to 3.5$\times$ with a 2.9$\times$ reduction in energy consumption over CPU-only inference. Our code is available at https://github.com/gicLAB/SECDA