 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Unstructured Sparsity in Fully Homomorphic Encrypted DNNs
Mar 12, 2025The deployment of deep neural networks (DNNs) in privacy-sensitive environments is constrained by computational overheads in fully homomorphic encryption (FHE). This paper explores unstructured sparsity in FHE matrix multiplication schemes as a means of reducing this burden while maintaining model accuracy requirements. We demonstrate that sparsity can be exploited in arbitrary matrix multiplication, providing runtime benefits compared to a baseline naive algorithm at all sparsity levels. This is a notable departure from the plaintext domain, where there is a trade-off between sparsity and the overhead of the sparse multiplication algorithm. In addition, we propose three sparse multiplication schemes in FHE based on common plaintext sparse encodings. We demonstrate the performance gain is scheme-invariant; however, some sparse schemes vastly reduce the memory storage requirements of the encrypted matrix at high sparsity values. Our proposed sparse schemes yield an average performance gain of 2.5x at 50% unstructured sparsity, with our multi-threading scheme providing a 32.5x performance increase over the equivalent single-threaded sparse computation when utilizing 64 cores.
Benchmark of DNN Model Search at Deployment Time
Jun 01, 2022
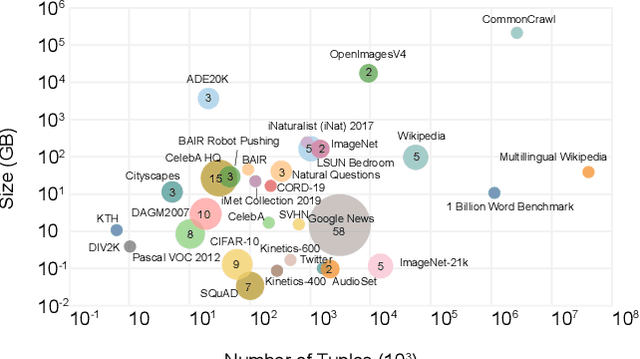
Deep learning has become the most popular direction in machine learning and artificial intelligence. However, the preparation of training data, as well as model training, are often time-consuming and become the bottleneck of the end-to-end machine learning lifecycle. Reusing models for inferring a dataset can avoid the costs of retraining. However, when there are multiple candidate models, it is challenging to discover the right model for reuse. Although there exist a number of model sharing platforms such as ModelDB, TensorFlow Hub, PyTorch Hub, and DLHub, most of these systems require model uploaders to manually specify the details of each model and model downloaders to screen keyword search results for selecting a model. We are lacking a highly productive model search tool that selects models for deployment without the need for any manual inspection and/or labeled data from the target domain. This paper proposes multiple model search strategies including various similarity-based approaches and non-similarity-based approaches. We design, implement, and evaluate these approaches on multiple model inference scenarios, including activity recognition, image recognition, text classification, natural language processing, and entity matching. The experimental evaluation showed that our proposed asymmetric similarity-based measurement, adaptivity, outperformed symmetric similarity-based measurements and non-similarity-based measurements in most of the workloads.
Survive the Schema Changes: Integration of Unmanaged Data Using Deep Learning
Oct 15, 2020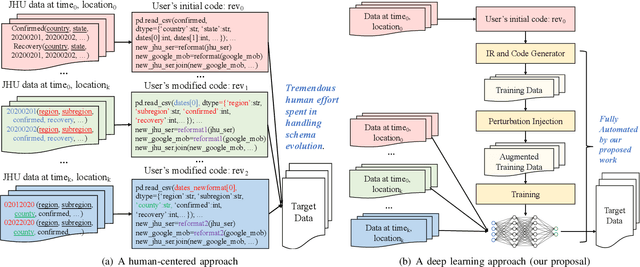
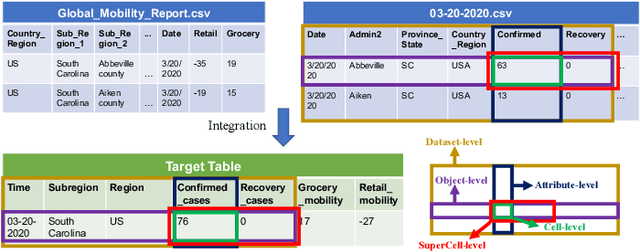
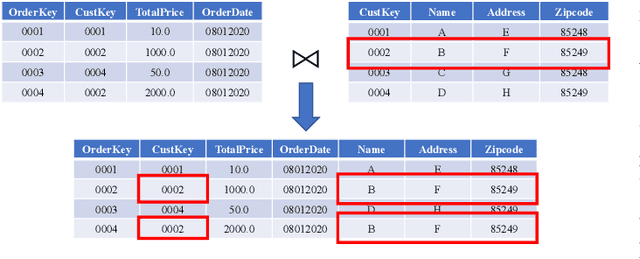
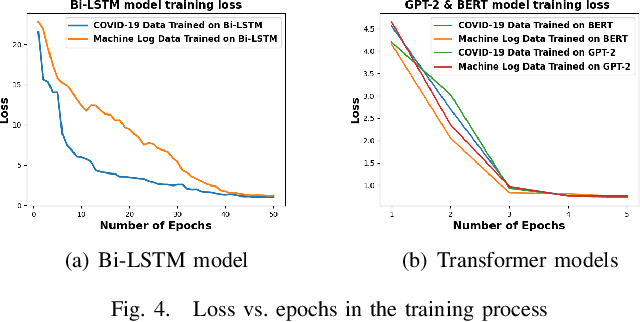
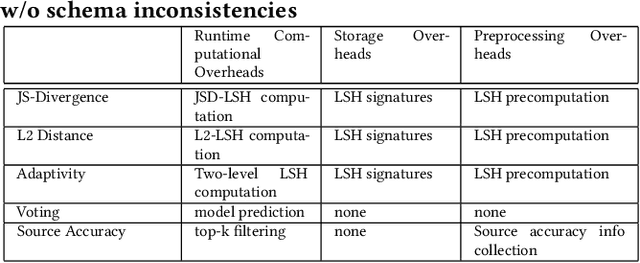
Data is the king in the age of AI. However data integration is often a laborious task that is hard to automate. Schema change is one significant obstacle to the automation of the end-to-end data integration process. Although there exist mechanisms such as query discovery and schema modification language to handle the problem, these approaches can only work with the assumption that the schema is maintained by a database. However, we observe diversified schema changes in heterogeneous data and open data, most of which has no schema defined. In this work, we propose to use deep learning to automatically deal with schema changes through a super cell representation and automatic injection of perturbations to the training data to make the model robust to schema changes. Our experimental results demonstrate that our proposed approach is effective for two real-world data integration scenarios: coronavirus data integration, and machine log integration.
It's the Best Only When It Fits You Most: Finding Related Models for Serving Based on Dynamic Locality Sensitive Hashing
Oct 13, 2020
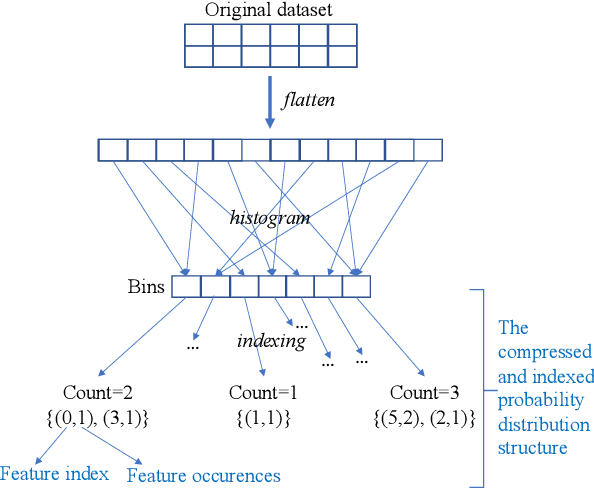
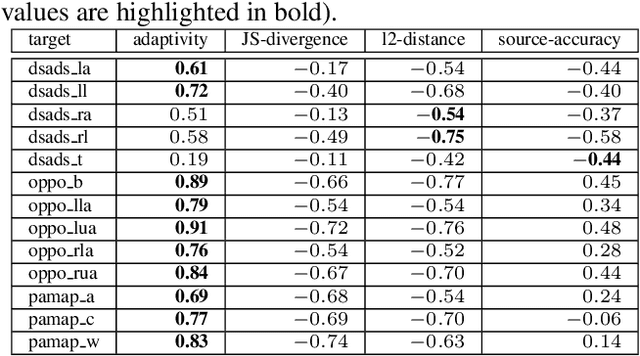
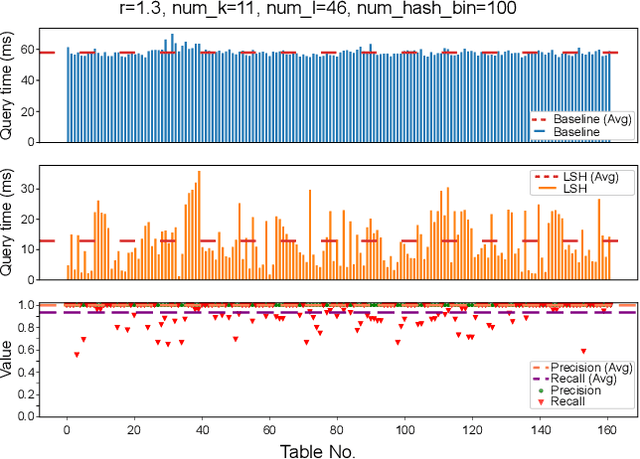
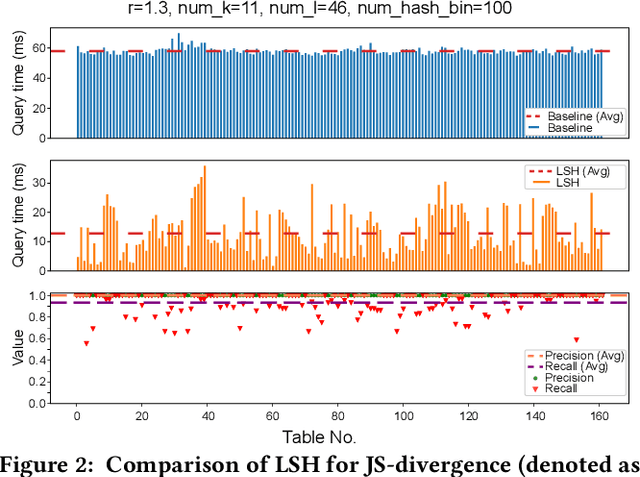
In recent, deep learning has become the most popular direction in machine learning and artificial intelligence. However, preparation of training data is often a bottleneck in the lifecycle of deploying a deep learning model for production or research. Reusing models for inferencing a dataset can greatly save the human costs required for training data creation. Although there exist a number of model sharing platform such as TensorFlow Hub, PyTorch Hub, DLHub, most of these systems require model uploaders to manually specify the details of each model and model downloaders to screen keyword search results for selecting a model. They are in lack of an automatic model searching tool. This paper proposes an end-to-end process of searching related models for serving based on the similarity of the target dataset and the training datasets of the available models. While there exist many similarity measurements, we study how to efficiently apply these metrics without pair-wise comparison and compare the effectiveness of these metrics. We find that our proposed adaptivity measurement which is based on Jensen-Shannon (JS) divergence, is an effective measurement, and its computation can be significantly accelerated by using the technique of locality sensitive hashing.