 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: Scaling Long-Sequence Homomorphic Encrypted Transformer Inference via Hybrid Parallelism on Multi-GPU Systems
Apr 03, 2026Fully Homomorphic Encryption (FHE) enables privacy-preserving Transformer inference, but long-sequence encrypted Transformers quickly exceed single-GPU memory capacity because encoded weights are already large and encrypted activations grow rapidly with sequence length. Multi-GPU execution therefore becomes unavoidable, yet scaling remains challenging because communication is jointly induced by application-level aggregation and encryption-level RNS coupling. Existing approaches either synchronize between devices frequently or replicate encrypted tensors across devices, leading to excessive communication and latency. We present AEGIS, an Application-Encryption Guided Inference System for scalable long-sequence encrypted Transformer inference on multi-GPU platforms. AEGIS derives device placement from ciphertext dependencies jointly induced by Transformer dataflow and CKKS polynomial coupling, co-locating modulus-coherent and token-coherent data so that communication is introduced only when application dependencies require it, while reordering polynomial operators to overlap the remaining collectives with computation. On 2048-token inputs, AEGIS reduces inter-GPU communication by up to 57.9% in feed-forward networks and 81.3% in self-attention versus prior state-of-the-art designs. On four GPUs, it achieves up to 96.62% scaling efficiency, 3.86x end-to-end speedup, and 69.1% per-device memory reduction. These results establish coordinated application-encryption parallelism as a practical foundation for scalable homomorphic Transformer inference.
When Small Variations Become Big Failures: Reliability Challenges in Compute-in-Memory Neural Accelerators
Mar 03, 2026Compute-in-memory (CiM) architectures promise significant improvements in energy efficiency and throughput for deep neural network acceleration by alleviating the von Neumann bottleneck. However, their reliance on emerging non-volatile memory devices introduces device-level non-idealities-such as write variability, conductance drift, and stochastic noise-that fundamentally challenge reliability, predictability, and safety, especially in safety-critical applications. This talk examines the reliability limits of CiM-based neural accelerators and presents a series of techniques that bridge device physics, architecture, and learning algorithms to address these challenges. We first demonstrate that even small device variations can lead to disproportionately large accuracy degradation and catastrophic failures in safety-critical inference workloads, revealing a critical gap between average-case evaluations and worst-case behavior. Building on this insight, we introduce SWIM, a selective write-verify mechanism that strategically applies verification only where it is most impactful, significantly improving reliability while maintaining CiM's efficiency advantages. Finally, we explore a learning-centric solution that improves realistic worst-case performance by training neural networks with right-censored Gaussian noise, aligning training assumptions with hardware-induced variability and enabling robust deployment without excessive hardware overhead. Together, these works highlight the necessity of cross-layer co-design for CiM accelerators and provide a principled path toward dependable, efficient neural inference on emerging memory technologies-paving the way for their adoption in safety- and reliability-critical systems.
A 10.60 $μ$W 150 GOPS Mixed-Bit-Width Sparse CNN Accelerator for Life-Threatening Ventricular Arrhythmia Detection
Oct 22, 2024



This paper proposes an ultra-low power, mixed-bit-width sparse convolutional neural network (CNN) accelerator to accelerate ventricular arrhythmia (VA) detection. The chip achieves 50% sparsity in a quantized 1D CNN using a sparse processing element (SPE) architecture. Measurement on the prototype chip TSMC 40nm CMOS low-power (LP) process for the VA classification task demonstrates that it consumes 10.60 $\mu$W of power while achieving a performance of 150 GOPS and a diagnostic accuracy of 99.95%. The computation power density is only 0.57 $\mu$W/mm$^2$, which is 14.23X smaller than state-of-the-art works, making it highly suitable for implantable and wearable medical devices.
AdaPI: Facilitating DNN Model Adaptivity for Efficient Private Inference in Edge Computing
Jul 08, 2024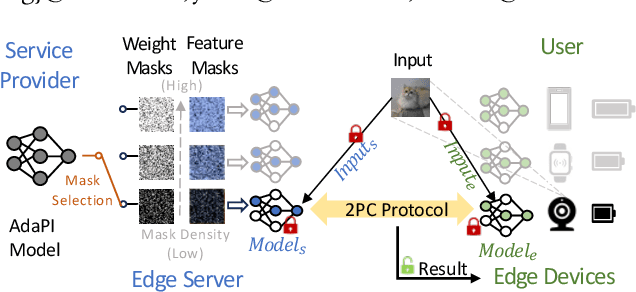
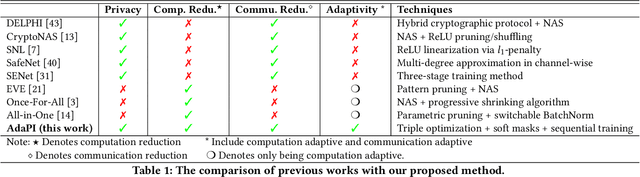
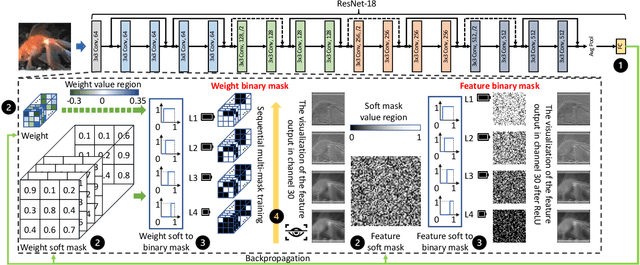
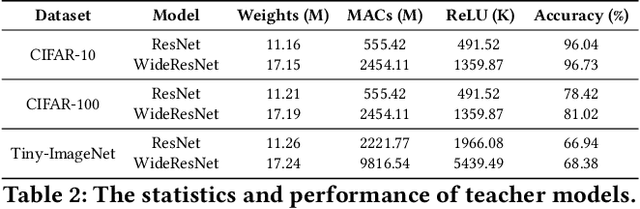
Private inference (PI) has emerged as a promising solution to execute computations on encrypted data, safeguarding user privacy and model parameters in edge computing. However, existing PI methods are predominantly developed considering constant resource constraints, overlooking the varied and dynamic resource constraints in diverse edge devices, like energy budgets. Consequently, model providers have to design specialized models for different devices, where all of them have to be stored on the edge server, resulting in inefficient deployment. To fill this gap, this work presents AdaPI, a novel approach that achieves adaptive PI by allowing a model to perform well across edge devices with diverse energy budgets. AdaPI employs a PI-aware training strategy that optimizes the model weights alongside weight-level and feature-level soft masks. These soft masks are subsequently transformed into multiple binary masks to enable adjustments in communication and computation workloads. Through sequentially training the model with increasingly dense binary masks, AdaPI attains optimal accuracy for each energy budget, which outperforms the state-of-the-art PI methods by 7.3\% in terms of test accuracy on CIFAR-100. The code of AdaPI can be accessed via https://github.com/jiahuiiiiii/AdaPI.
SSNet: A Lightweight Multi-Party Computation Scheme for Practical Privacy-Preserving Machine Learning Service in the Cloud
Jun 04, 2024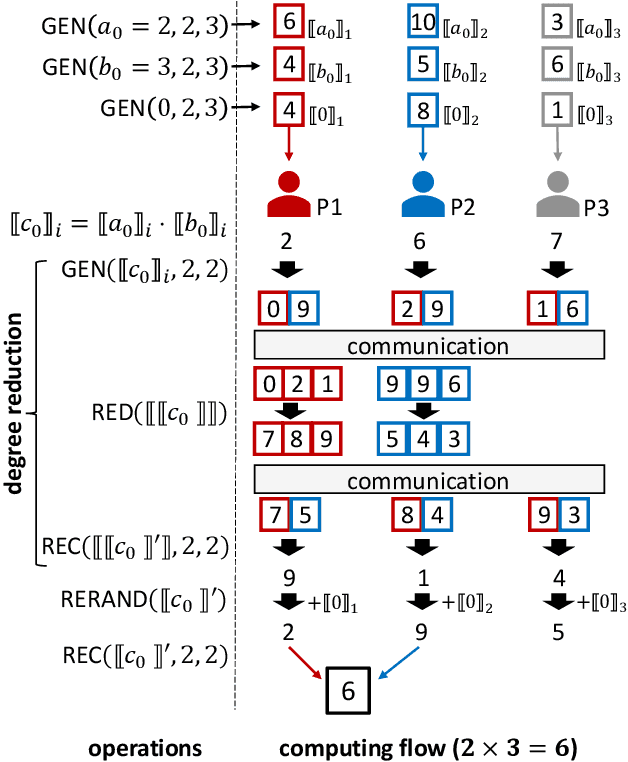
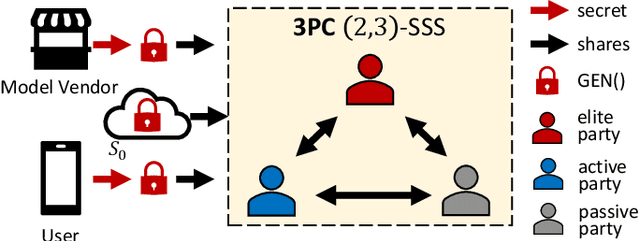
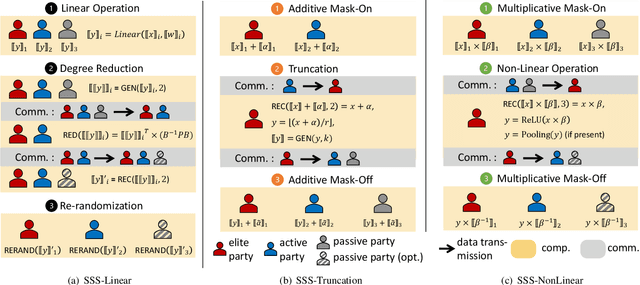
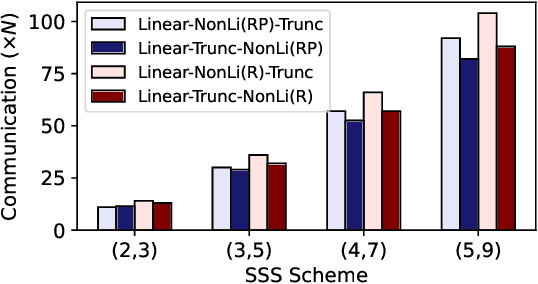
As privacy-preserving becomes a pivotal aspect of deep learning (DL) development, multi-party computation (MPC) has gained prominence for its efficiency and strong security. However, the practice of current MPC frameworks is limited, especially when dealing with large neural networks, exemplified by the prolonged execution time of 25.8 seconds for secure inference on ResNet-152. The primary challenge lies in the reliance of current MPC approaches on additive secret sharing, which incurs significant communication overhead with non-linear operations such as comparisons. Furthermore, additive sharing suffers from poor scalability on party size. In contrast, the evolving landscape of MPC necessitates accommodating a larger number of compute parties and ensuring robust performance against malicious activities or computational failures. In light of these challenges, we propose SSNet, which for the first time, employs Shamir's secret sharing (SSS) as the backbone of MPC-based ML framework. We meticulously develop all framework primitives and operations for secure DL models tailored to seamlessly integrate with the SSS scheme. SSNet demonstrates the ability to scale up party numbers straightforwardly and embeds strategies to authenticate the computation correctness without incurring significant performance overhead. Additionally, SSNet introduces masking strategies designed to reduce communication overhead associated with non-linear operations. We conduct comprehensive experimental evaluations on commercial cloud computing infrastructure from Amazon AWS, as well as across diverse prevalent DNN models and datasets. SSNet demonstrates a substantial performance boost, achieving speed-ups ranging from 3x to 14x compared to SOTA MPC frameworks. Moreover, SSNet also represents the first framework that is evaluated on a five-party computation setup, in the context of secure DL inference.
Zero-Space Cost Fault Tolerance for Transformer-based Language Models on ReRAM
Jan 22, 2024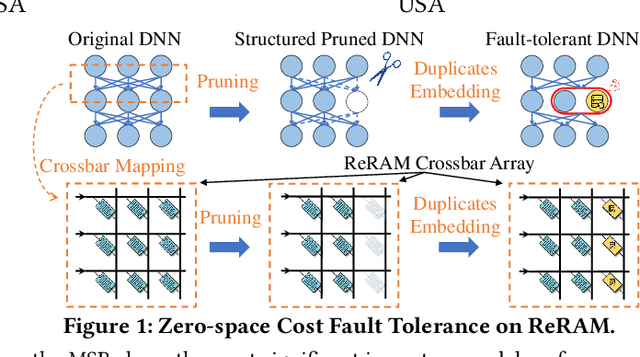

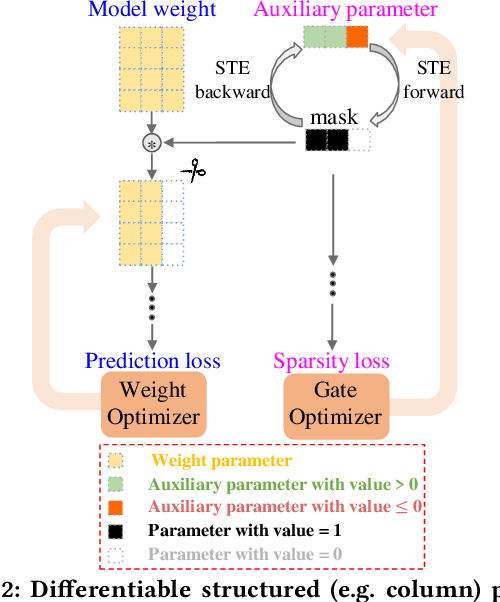

Resistive Random Access Memory (ReRAM) has emerged as a promising platform for deep neural networks (DNNs) due to its support for parallel in-situ matrix-vector multiplication. However, hardware failures, such as stuck-at-fault defects, can result in significant prediction errors during model inference. While additional crossbars can be used to address these failures, they come with storage overhead and are not efficient in terms of space, energy, and cost. In this paper, we propose a fault protection mechanism that incurs zero space cost. Our approach includes: 1) differentiable structure pruning of rows and columns to reduce model redundancy, 2) weight duplication and voting for robust output, and 3) embedding duplicated most significant bits (MSBs) into the model weight. We evaluate our method on nine tasks of the GLUE benchmark with the BERT model, and experimental results prove its effectiveness.
LinGCN: Structural Linearized Graph Convolutional Network for Homomorphically Encrypted Inference
Sep 30, 2023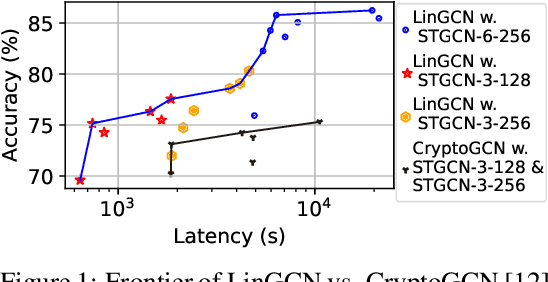

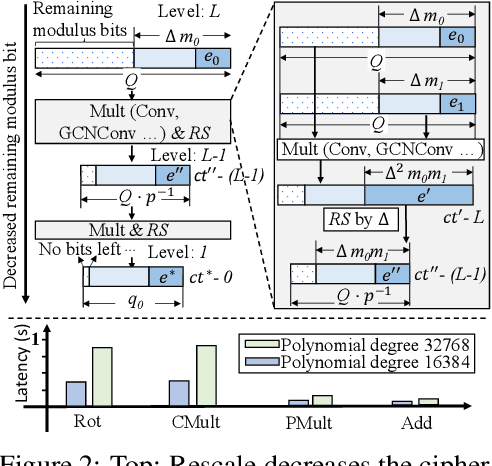
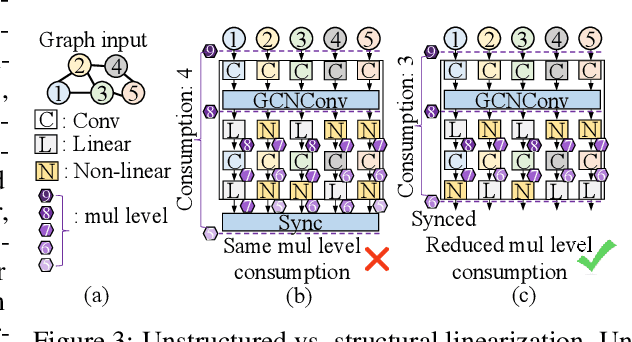
The growth of Graph Convolution Network (GCN) model sizes has revolutionized numerous applications, surpassing human performance in areas such as personal healthcare and financial systems. The deployment of GCNs in the cloud raises privacy concerns due to potential adversarial attacks on client data. To address security concerns, Privacy-Preserving Machine Learning (PPML) using Homomorphic Encryption (HE) secures sensitive client data. However, it introduces substantial computational overhead in practical applications. To tackle those challenges, we present LinGCN, a framework designed to reduce multiplication depth and optimize the performance of HE based GCN inference. LinGCN is structured around three key elements: (1) A differentiable structural linearization algorithm, complemented by a parameterized discrete indicator function, co-trained with model weights to meet the optimization goal. This strategy promotes fine-grained node-level non-linear location selection, resulting in a model with minimized multiplication depth. (2) A compact node-wise polynomial replacement policy with a second-order trainable activation function, steered towards superior convergence by a two-level distillation approach from an all-ReLU based teacher model. (3) an enhanced HE solution that enables finer-grained operator fusion for node-wise activation functions, further reducing multiplication level consumption in HE-based inference. Our experiments on the NTU-XVIEW skeleton joint dataset reveal that LinGCN excels in latency, accuracy, and scalability for homomorphically encrypted inference, outperforming solutions such as CryptoGCN. Remarkably, LinGCN achieves a 14.2x latency speedup relative to CryptoGCN, while preserving an inference accuracy of 75% and notably reducing multiplication depth.
AutoReP: Automatic ReLU Replacement for Fast Private Network Inference
Aug 20, 2023



The growth of the Machine-Learning-As-A-Service (MLaaS) market has highlighted clients' data privacy and security issues. Private inference (PI) techniques using cryptographic primitives offer a solution but often have high computation and communication costs, particularly with non-linear operators like ReLU. Many attempts to reduce ReLU operations exist, but they may need heuristic threshold selection or cause substantial accuracy loss. This work introduces AutoReP, a gradient-based approach to lessen non-linear operators and alleviate these issues. It automates the selection of ReLU and polynomial functions to speed up PI applications and introduces distribution-aware polynomial approximation (DaPa) to maintain model expressivity while accurately approximating ReLUs. Our experimental results demonstrate significant accuracy improvements of 6.12% (94.31%, 12.9K ReLU budget, CIFAR-10), 8.39% (74.92%, 12.9K ReLU budget, CIFAR-100), and 9.45% (63.69%, 55K ReLU budget, Tiny-ImageNet) over current state-of-the-art methods, e.g., SNL. Morever, AutoReP is applied to EfficientNet-B2 on ImageNet dataset, and achieved 75.55% accuracy with 176.1 times ReLU budget reduction.
Improving Realistic Worst-Case Performance of NVCiM DNN Accelerators through Training with Right-Censored Gaussian Noise
Jul 29, 2023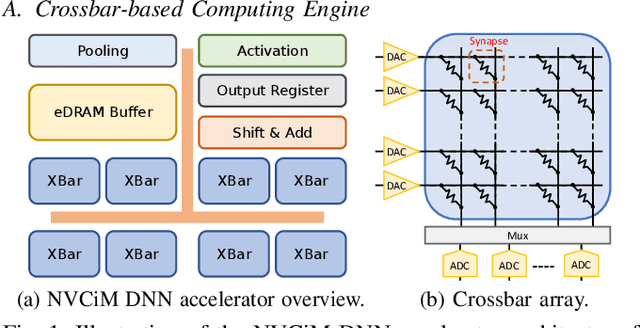
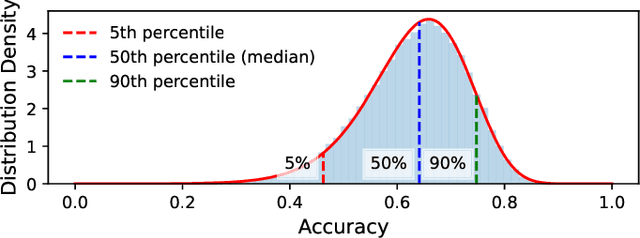
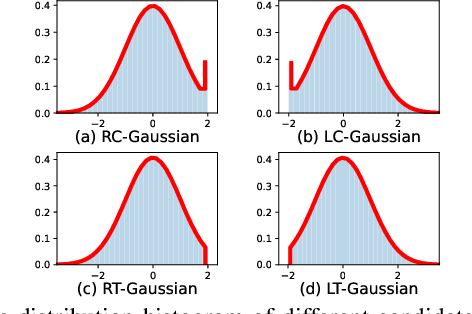
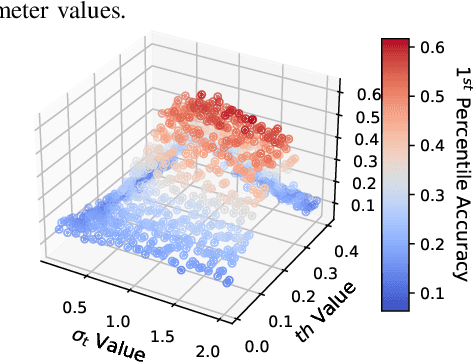
Compute-in-Memory (CiM), built upon non-volatile memory (NVM) devices, is promising for accelerating deep neural networks (DNNs) owing to its in-situ data processing capability and superior energy efficiency. Unfortunately, the well-trained model parameters, after being mapped to NVM devices, can often exhibit large deviations from their intended values due to device variations, resulting in notable performance degradation in these CiM-based DNN accelerators. There exists a long list of solutions to address this issue. However, they mainly focus on improving the mean performance of CiM DNN accelerators. How to guarantee the worst-case performance under the impact of device variations, which is crucial for many safety-critical applications such as self-driving cars, has been far less explored. In this work, we propose to use the k-th percentile performance (KPP) to capture the realistic worst-case performance of DNN models executing on CiM accelerators. Through a formal analysis of the properties of KPP and the noise injection-based DNN training, we demonstrate that injecting a novel right-censored Gaussian noise, as opposed to the conventional Gaussian noise, significantly improves the KPP of DNNs. We further propose an automated method to determine the optimal hyperparameters for injecting this right-censored Gaussian noise during the training process. Our method achieves up to a 26% improvement in KPP compared to the state-of-the-art methods employed to enhance DNN robustness under the impact of device variations.
Spectral-DP: Differentially Private Deep Learning through Spectral Perturbation and Filtering
Jul 25, 2023



Differential privacy is a widely accepted measure of privacy in the context of deep learning algorithms, and achieving it relies on a noisy training approach known as differentially private stochastic gradient descent (DP-SGD). DP-SGD requires direct noise addition to every gradient in a dense neural network, the privacy is achieved at a significant utility cost. In this work, we present Spectral-DP, a new differentially private learning approach which combines gradient perturbation in the spectral domain with spectral filtering to achieve a desired privacy guarantee with a lower noise scale and thus better utility. We develop differentially private deep learning methods based on Spectral-DP for architectures that contain both convolution and fully connected layers. In particular, for fully connected layers, we combine a block-circulant based spatial restructuring with Spectral-DP to achieve better utility. Through comprehensive experiments, we study and provide guidelines to implement Spectral-DP deep learning on benchmark datasets. In comparison with state-of-the-art DP-SGD based approaches, Spectral-DP is shown to have uniformly better utility performance in both training from scratch and transfer learning settings.