 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbracing Unknown Step by Step: Towards Reliable Sparse Training in Real World
Mar 29, 2024Sparse training has emerged as a promising method for resource-efficient deep neural networks (DNNs) in real-world applications. However, the reliability of sparse models remains a crucial concern, particularly in detecting unknown out-of-distribution (OOD) data. This study addresses the knowledge gap by investigating the reliability of sparse training from an OOD perspective and reveals that sparse training exacerbates OOD unreliability. The lack of unknown information and the sparse constraints hinder the effective exploration of weight space and accurate differentiation between known and unknown knowledge. To tackle these challenges, we propose a new unknown-aware sparse training method, which incorporates a loss modification, auto-tuning strategy, and a voting scheme to guide weight space exploration and mitigate confusion between known and unknown information without incurring significant additional costs or requiring access to additional OOD data. Theoretical insights demonstrate how our method reduces model confidence when faced with OOD samples. Empirical experiments across multiple datasets, model architectures, and sparsity levels validate the effectiveness of our method, with improvements of up to \textbf{8.4\%} in AUROC while maintaining comparable or higher accuracy and calibration. This research enhances the understanding and readiness of sparse DNNs for deployment in resource-limited applications. Our code is available on: \url{https://github.com/StevenBoys/MOON}.
InVA: Integrative Variational Autoencoder for Harmonization of Multi-modal Neuroimaging Data
Feb 05, 2024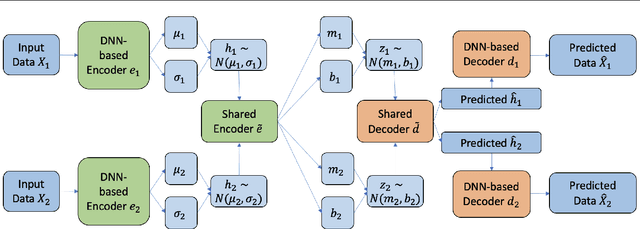
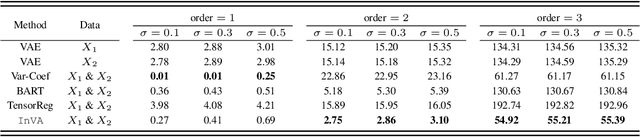
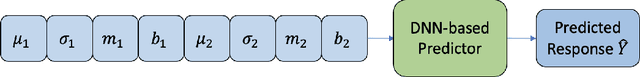
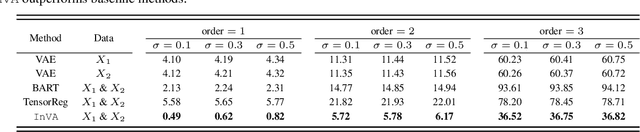
There is a significant interest in exploring non-linear associations among multiple images derived from diverse imaging modalities. While there is a growing literature on image-on-image regression to delineate predictive inference of an image based on multiple images, existing approaches have limitations in efficiently borrowing information between multiple imaging modalities in the prediction of an image. Building on the literature of Variational Auto Encoders (VAEs), this article proposes a novel approach, referred to as Integrative Variational Autoencoder (\texttt{InVA}) method, which borrows information from multiple images obtained from different sources to draw predictive inference of an image. The proposed approach captures complex non-linear association between the outcome image and input images, while allowing rapid computation. Numerical results demonstrate substantial advantages of \texttt{InVA} over VAEs, which typically do not allow borrowing information between input images. The proposed framework offers highly accurate predictive inferences for costly positron emission topography (PET) from multiple measures of cortical structure in human brain scans readily available from magnetic resonance imaging (MRI).
Rethinking Data Distillation: Do Not Overlook Calibration
Jul 24, 2023



Neural networks trained on distilled data often produce over-confident output and require correction by calibration methods. Existing calibration methods such as temperature scaling and mixup work well for networks trained on original large-scale data. However, we find that these methods fail to calibrate networks trained on data distilled from large source datasets. In this paper, we show that distilled data lead to networks that are not calibratable due to (i) a more concentrated distribution of the maximum logits and (ii) the loss of information that is semantically meaningful but unrelated to classification tasks. To address this problem, we propose Masked Temperature Scaling (MTS) and Masked Distillation Training (MDT) which mitigate the limitations of distilled data and achieve better calibration results while maintaining the efficiency of dataset distillation.
Towards Reliable Rare Category Analysis on Graphs via Individual Calibration
Jul 19, 2023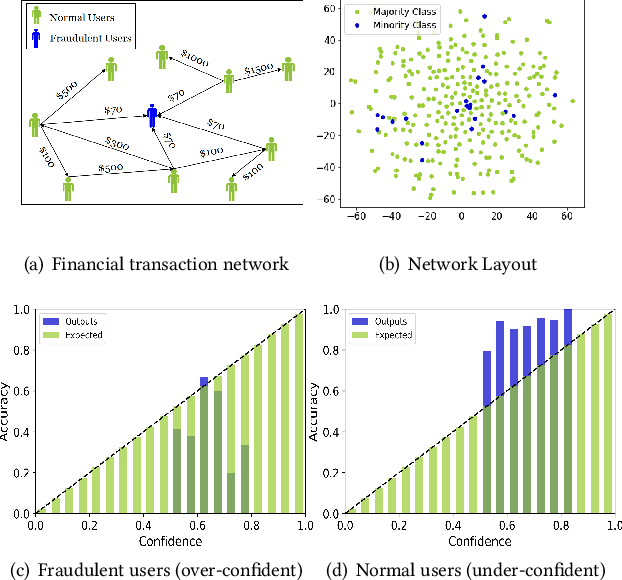
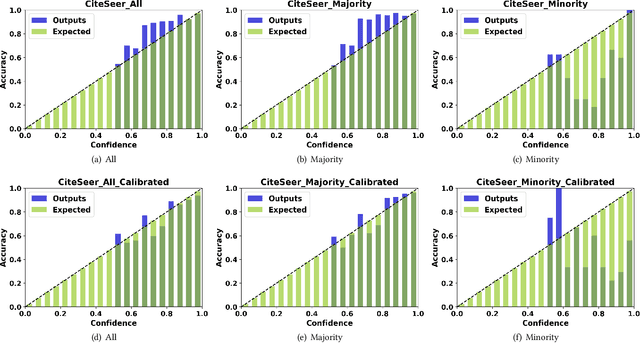
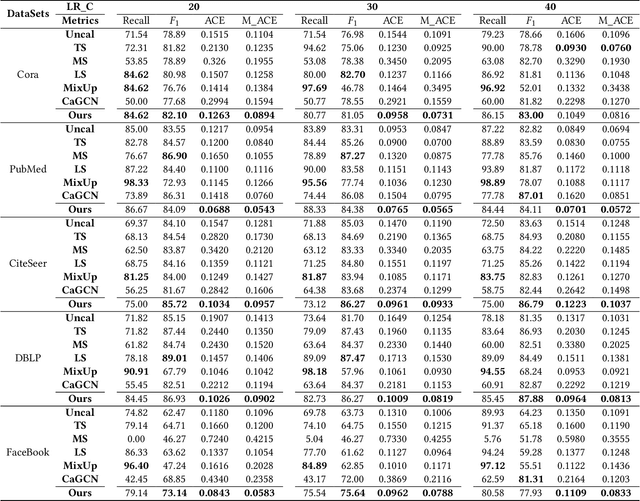
Rare categories abound in a number of real-world networks and play a pivotal role in a variety of high-stakes applications, including financial fraud detection, network intrusion detection, and rare disease diagnosis. Rare category analysis (RCA) refers to the task of detecting, characterizing, and comprehending the behaviors of minority classes in a highly-imbalanced data distribution. While the vast majority of existing work on RCA has focused on improving the prediction performance, a few fundamental research questions heretofore have received little attention and are less explored: How confident or uncertain is a prediction model in rare category analysis? How can we quantify the uncertainty in the learning process and enable reliable rare category analysis? To answer these questions, we start by investigating miscalibration in existing RCA methods. Empirical results reveal that state-of-the-art RCA methods are mainly over-confident in predicting minority classes and under-confident in predicting majority classes. Motivated by the observation, we propose a novel individual calibration framework, named CALIRARE, for alleviating the unique challenges of RCA, thus enabling reliable rare category analysis. In particular, to quantify the uncertainties in RCA, we develop a node-level uncertainty quantification algorithm to model the overlapping support regions with high uncertainty; to handle the rarity of minority classes in miscalibration calculation, we generalize the distribution-based calibration metric to the instance level and propose the first individual calibration measurement on graphs named Expected Individual Calibration Error (EICE). We perform extensive experimental evaluations on real-world datasets, including rare category characterization and model calibration tasks, which demonstrate the significance of our proposed framework.
Neurogenesis Dynamics-inspired Spiking Neural Network Training Acceleration
Apr 24, 2023



Biologically inspired Spiking Neural Networks (SNNs) have attracted significant attention for their ability to provide extremely energy-efficient machine intelligence through event-driven operation and sparse activities. As artificial intelligence (AI) becomes ever more democratized, there is an increasing need to execute SNN models on edge devices. Existing works adopt weight pruning to reduce SNN model size and accelerate inference. However, these methods mainly focus on how to obtain a sparse model for efficient inference, rather than training efficiency. To overcome these drawbacks, in this paper, we propose a Neurogenesis Dynamics-inspired Spiking Neural Network training acceleration framework, NDSNN. Our framework is computational efficient and trains a model from scratch with dynamic sparsity without sacrificing model fidelity. Specifically, we design a new drop-and-grow strategy with decreasing number of non-zero weights, to maintain extreme high sparsity and high accuracy. We evaluate NDSNN using VGG-16 and ResNet-19 on CIFAR-10, CIFAR-100 and TinyImageNet. Experimental results show that NDSNN achieves up to 20.52\% improvement in accuracy on Tiny-ImageNet using ResNet-19 (with a sparsity of 99\%) as compared to other SOTA methods (e.g., Lottery Ticket Hypothesis (LTH), SET-SNN, RigL-SNN). In addition, the training cost of NDSNN is only 40.89\% of the LTH training cost on ResNet-19 and 31.35\% of the LTH training cost on VGG-16 on CIFAR-10.
Calibrating the Rigged Lottery: Making All Tickets Reliable
Mar 01, 2023



Although sparse training has been successfully used in various resource-limited deep learning tasks to save memory, accelerate training, and reduce inference time, the reliability of the produced sparse models remains unexplored. Previous research has shown that deep neural networks tend to be over-confident, and we find that sparse training exacerbates this problem. Therefore, calibrating the sparse models is crucial for reliable prediction and decision-making. In this paper, we propose a new sparse training method to produce sparse models with improved confidence calibration. In contrast to previous research that uses only one mask to control the sparse topology, our method utilizes two masks, including a deterministic mask and a random mask. The former efficiently searches and activates important weights by exploiting the magnitude of weights and gradients. While the latter brings better exploration and finds more appropriate weight values by random updates. Theoretically, we prove our method can be viewed as a hierarchical variational approximation of a probabilistic deep Gaussian process. Extensive experiments on multiple datasets, model architectures, and sparsities show that our method reduces ECE values by up to 47.8\% and simultaneously maintains or even improves accuracy with only a slight increase in computation and storage burden.
Efficient Informed Proposals for Discrete Distributions via Newton's Series Approximation
Feb 27, 2023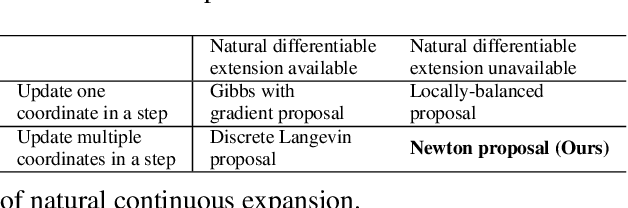
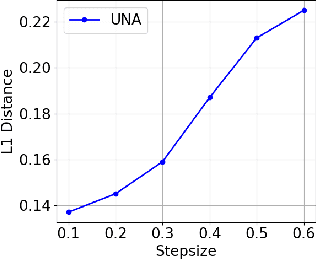
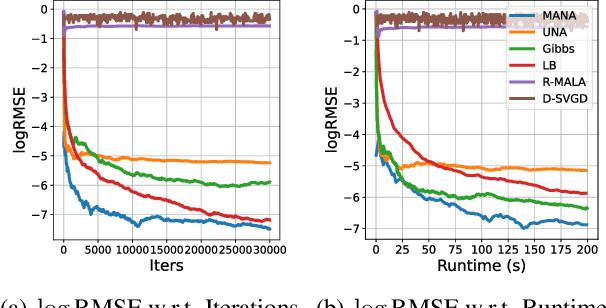

Gradients have been exploited in proposal distributions to accelerate the convergence of Markov chain Monte Carlo algorithms on discrete distributions. However, these methods require a natural differentiable extension of the target discrete distribution, which often does not exist or does not provide effective gradient guidance. In this paper, we develop a gradient-like proposal for any discrete distribution without this strong requirement. Built upon a locally-balanced proposal, our method efficiently approximates the discrete likelihood ratio via Newton's series expansion to enable a large and efficient exploration in discrete spaces. We show that our method can also be viewed as a multilinear extension, thus inheriting its desired properties. We prove that our method has a guaranteed convergence rate with or without the Metropolis-Hastings step. Furthermore, our method outperforms a number of popular alternatives in several different experiments, including the facility location problem, extractive text summarization, and image retrieval.
Balance is Essence: Accelerating Sparse Training via Adaptive Gradient Correction
Jan 09, 2023



Despite impressive performance on a wide variety of tasks, deep neural networks require significant memory and computation costs, prohibiting their application in resource-constrained scenarios. Sparse training is one of the most common techniques to reduce these costs, however, the sparsity constraints add difficulty to the optimization, resulting in an increase in training time and instability. In this work, we aim to overcome this problem and achieve space-time co-efficiency. To accelerate and stabilize the convergence of sparse training, we analyze the gradient changes and develop an adaptive gradient correction method. Specifically, we approximate the correlation between the current and previous gradients, which is used to balance the two gradients to obtain a corrected gradient. Our method can be used with most popular sparse training pipelines under both standard and adversarial setups. Theoretically, we prove that our method can accelerate the convergence rate of sparse training. Extensive experiments on multiple datasets, model architectures, and sparsities demonstrate that our method outperforms leading sparse training methods by up to \textbf{5.0\%} in accuracy given the same number of training epochs, and reduces the number of training epochs by up to \textbf{52.1\%} to achieve the same accuracy.
Dynamic Sparse Training via More Exploration
Dec 14, 2022



Over-parameterization of deep neural networks (DNNs) has shown high prediction accuracy for many applications. Although effective, the large number of parameters hinders its popularity on resource-limited devices and has an outsize environmental impact. Sparse training (using a fixed number of nonzero weights in each iteration) could significantly mitigate the training costs by reducing the model size. However, existing sparse training methods mainly use either random-based or greedy-based drop-and-grow strategies, resulting in local minimal and low accuracy. In this work, we consider the dynamic sparse training as a sparse connectivity search problem and design an exploitation and exploration acquisition function to escape from local optima and saddle points. We further design an acquisition function and provide the theoretical guarantees for the proposed method and clarify its convergence property. Experimental results show that sparse models (up to 98\% sparsity) obtained by our proposed method outperform the SOTA sparse training methods on a wide variety of deep learning tasks. On VGG-19 / CIFAR-100, ResNet-50 / CIFAR-10, ResNet-50 / CIFAR-100, our method has even higher accuracy than dense models. On ResNet-50 / ImageNet, the proposed method has up to 8.2\% accuracy improvement compared to SOTA sparse training methods.
Accelerating Dataset Distillation via Model Augmentation
Dec 12, 2022



Dataset Distillation (DD), a newly emerging field, aims at generating much smaller and high-quality synthetic datasets from large ones. Existing DD methods based on gradient matching achieve leading performance; however, they are extremely computationally intensive as they require continuously optimizing a dataset among thousands of randomly initialized models. In this paper, we assume that training the synthetic data with diverse models leads to better generalization performance. Thus we propose two \textbf{model augmentation} techniques, ~\ie using \textbf{early-stage models} and \textbf{weight perturbation} to learn an informative synthetic set with significantly reduced training cost. Extensive experiments demonstrate that our method achieves up to 20$\times$ speedup and comparable performance on par with state-of-the-art baseline methods.