 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Knowledge in Large Language Models: A Framework for Categorization and Comprehension
Jan 02, 2025


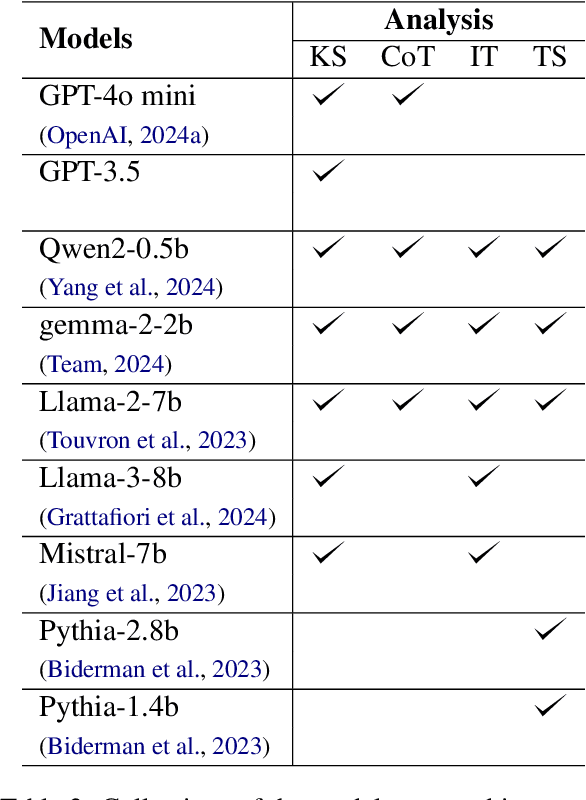
Understanding how large language models (LLMs) acquire, retain, and apply knowledge remains an open challenge. This paper introduces a novel framework, K-(CSA)^2, which categorizes LLM knowledge along two dimensions: correctness and confidence. The framework defines six categories of knowledge, ranging from highly confident correctness to confidently held misconceptions, enabling a nuanced evaluation of model comprehension beyond binary accuracy. Using this framework, we demonstrate how techniques like chain-of-thought prompting and reinforcement learning with human feedback fundamentally alter the knowledge structures of internal (pre-trained) and external (context-dependent) knowledge in LLMs. CoT particularly enhances base model performance and shows synergistic benefits when applied to aligned LLMs. Moreover, our layer-wise analysis reveals that higher layers in LLMs encode more high-confidence knowledge, while low-confidence knowledge tends to emerge in middle-to-lower layers.
Rethinking Data Distillation: Do Not Overlook Calibration
Jul 24, 2023



Neural networks trained on distilled data often produce over-confident output and require correction by calibration methods. Existing calibration methods such as temperature scaling and mixup work well for networks trained on original large-scale data. However, we find that these methods fail to calibrate networks trained on data distilled from large source datasets. In this paper, we show that distilled data lead to networks that are not calibratable due to (i) a more concentrated distribution of the maximum logits and (ii) the loss of information that is semantically meaningful but unrelated to classification tasks. To address this problem, we propose Masked Temperature Scaling (MTS) and Masked Distillation Training (MDT) which mitigate the limitations of distilled data and achieve better calibration results while maintaining the efficiency of dataset distillation.