 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbracing Unknown Step by Step: Towards Reliable Sparse Training in Real World
Mar 29, 2024Sparse training has emerged as a promising method for resource-efficient deep neural networks (DNNs) in real-world applications. However, the reliability of sparse models remains a crucial concern, particularly in detecting unknown out-of-distribution (OOD) data. This study addresses the knowledge gap by investigating the reliability of sparse training from an OOD perspective and reveals that sparse training exacerbates OOD unreliability. The lack of unknown information and the sparse constraints hinder the effective exploration of weight space and accurate differentiation between known and unknown knowledge. To tackle these challenges, we propose a new unknown-aware sparse training method, which incorporates a loss modification, auto-tuning strategy, and a voting scheme to guide weight space exploration and mitigate confusion between known and unknown information without incurring significant additional costs or requiring access to additional OOD data. Theoretical insights demonstrate how our method reduces model confidence when faced with OOD samples. Empirical experiments across multiple datasets, model architectures, and sparsity levels validate the effectiveness of our method, with improvements of up to \textbf{8.4\%} in AUROC while maintaining comparable or higher accuracy and calibration. This research enhances the understanding and readiness of sparse DNNs for deployment in resource-limited applications. Our code is available on: \url{https://github.com/StevenBoys/MOON}.
InVA: Integrative Variational Autoencoder for Harmonization of Multi-modal Neuroimaging Data
Feb 05, 2024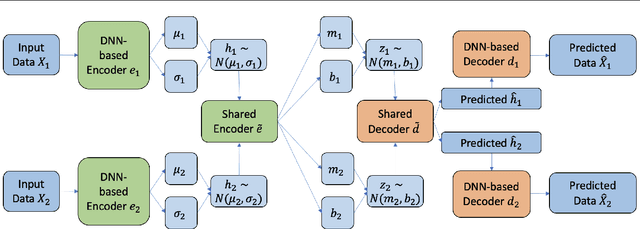
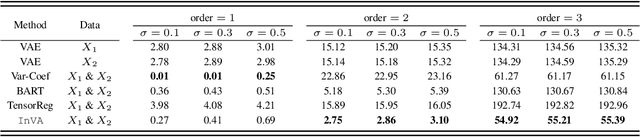
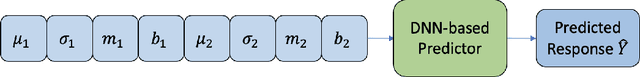
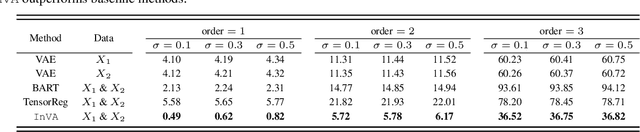
There is a significant interest in exploring non-linear associations among multiple images derived from diverse imaging modalities. While there is a growing literature on image-on-image regression to delineate predictive inference of an image based on multiple images, existing approaches have limitations in efficiently borrowing information between multiple imaging modalities in the prediction of an image. Building on the literature of Variational Auto Encoders (VAEs), this article proposes a novel approach, referred to as Integrative Variational Autoencoder (\texttt{InVA}) method, which borrows information from multiple images obtained from different sources to draw predictive inference of an image. The proposed approach captures complex non-linear association between the outcome image and input images, while allowing rapid computation. Numerical results demonstrate substantial advantages of \texttt{InVA} over VAEs, which typically do not allow borrowing information between input images. The proposed framework offers highly accurate predictive inferences for costly positron emission topography (PET) from multiple measures of cortical structure in human brain scans readily available from magnetic resonance imaging (MRI).
Adaptive Conditional Quantile Neural Processes
Jun 08, 2023
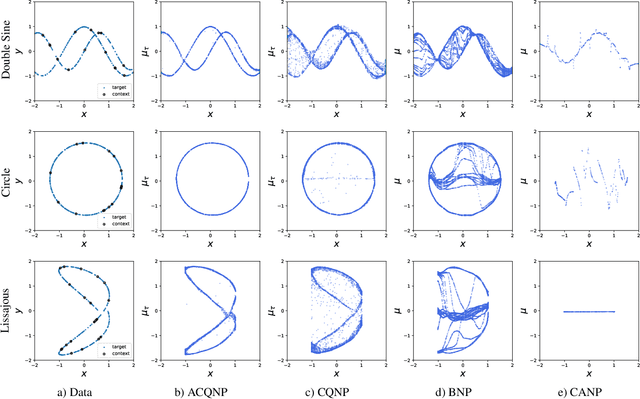
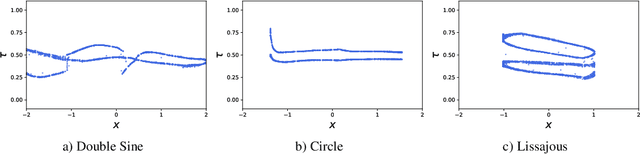
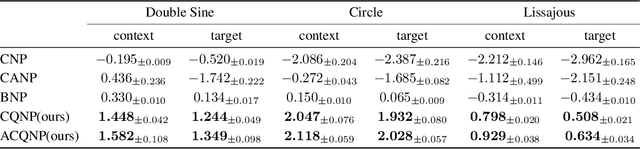
Neural processes are a family of probabilistic models that inherit the flexibility of neural networks to parameterize stochastic processes. Despite providing well-calibrated predictions, especially in regression problems, and quick adaptation to new tasks, the Gaussian assumption that is commonly used to represent the predictive likelihood fails to capture more complicated distributions such as multimodal ones. To overcome this limitation, we propose Conditional Quantile Neural Processes (CQNPs), a new member of the neural processes family, which exploits the attractive properties of quantile regression in modeling the distributions irrespective of their form. By introducing an extension of quantile regression where the model learns to focus on estimating informative quantiles, we show that the sampling efficiency and prediction accuracy can be further enhanced. Our experiments with real and synthetic datasets demonstrate substantial improvements in predictive performance compared to the baselines, and better modeling of heterogeneous distributions' characteristics such as multimodality.
Calibrating the Rigged Lottery: Making All Tickets Reliable
Mar 01, 2023



Although sparse training has been successfully used in various resource-limited deep learning tasks to save memory, accelerate training, and reduce inference time, the reliability of the produced sparse models remains unexplored. Previous research has shown that deep neural networks tend to be over-confident, and we find that sparse training exacerbates this problem. Therefore, calibrating the sparse models is crucial for reliable prediction and decision-making. In this paper, we propose a new sparse training method to produce sparse models with improved confidence calibration. In contrast to previous research that uses only one mask to control the sparse topology, our method utilizes two masks, including a deterministic mask and a random mask. The former efficiently searches and activates important weights by exploiting the magnitude of weights and gradients. While the latter brings better exploration and finds more appropriate weight values by random updates. Theoretically, we prove our method can be viewed as a hierarchical variational approximation of a probabilistic deep Gaussian process. Extensive experiments on multiple datasets, model architectures, and sparsities show that our method reduces ECE values by up to 47.8\% and simultaneously maintains or even improves accuracy with only a slight increase in computation and storage burden.
Ordinal Causal Discovery
Jan 24, 2022


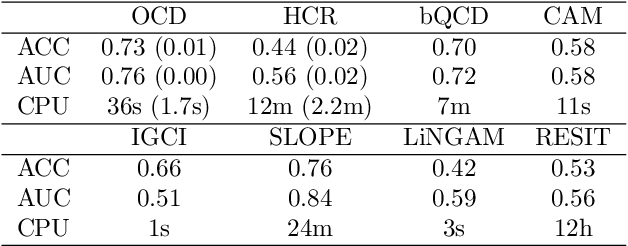
Causal discovery for purely observational, categorical data is a long-standing challenging problem. Unlike continuous data, the vast majority of existing methods for categorical data focus on inferring the Markov equivalence class only, which leaves the direction of some causal relationships undetermined. This paper proposes an identifiable ordinal causal discovery method that exploits the ordinal information contained in many real-world applications to uniquely identify the causal structure. The proposed method is applicable beyond ordinal data via data discretization. Through real-world and synthetic experiments, we demonstrate that the proposed ordinal causal discovery method combined with simple score-and-search algorithms has favorable and robust performance compared to state-of-the-art alternative methods in both ordinal categorical and non-categorical data. An accompanied R package OCD is freely available at https://web.stat.tamu.edu/~yni/files/OCD_0.1.0.tar.gz.
Off-Policy Evaluation Using Information Borrowing and Context-Based Switching
Dec 18, 2021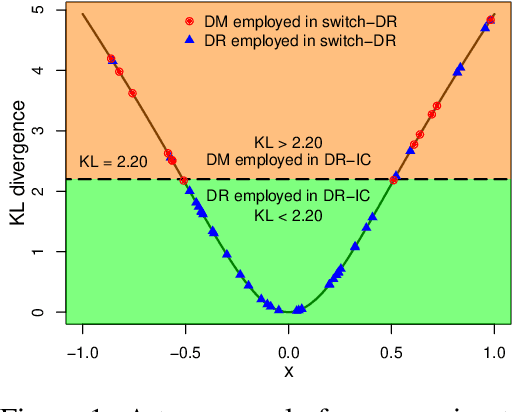

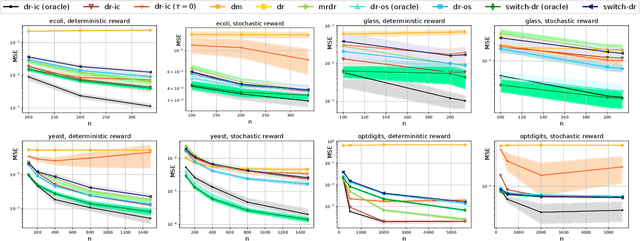

We consider the off-policy evaluation (OPE) problem in contextual bandits, where the goal is to estimate the value of a target policy using the data collected by a logging policy. Most popular approaches to the OPE are variants of the doubly robust (DR) estimator obtained by combining a direct method (DM) estimator and a correction term involving the inverse propensity score (IPS). Existing algorithms primarily focus on strategies to reduce the variance of the DR estimator arising from large IPS. We propose a new approach called the Doubly Robust with Information borrowing and Context-based switching (DR-IC) estimator that focuses on reducing both bias and variance. The DR-IC estimator replaces the standard DM estimator with a parametric reward model that borrows information from the 'closer' contexts through a correlation structure that depends on the IPS. The DR-IC estimator also adaptively interpolates between this modified DM estimator and a modified DR estimator based on a context-specific switching rule. We give provable guarantees on the performance of the DR-IC estimator. We also demonstrate the superior performance of the DR-IC estimator compared to the state-of-the-art OPE algorithms on a number of benchmark problems.