 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation Using Information Borrowing and Context-Based Switching
Paper and Code
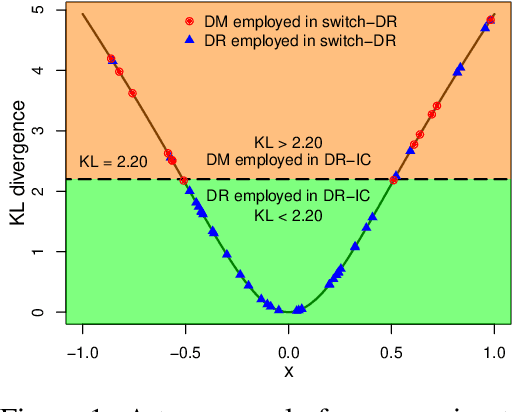

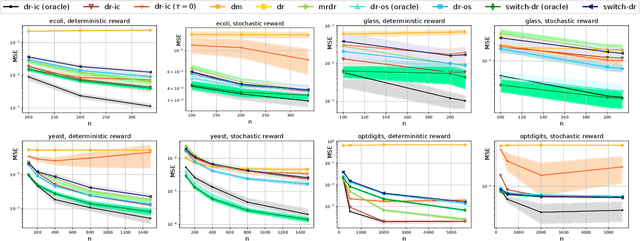

We consider the off-policy evaluation (OPE) problem in contextual bandits, where the goal is to estimate the value of a target policy using the data collected by a logging policy. Most popular approaches to the OPE are variants of the doubly robust (DR) estimator obtained by combining a direct method (DM) estimator and a correction term involving the inverse propensity score (IPS). Existing algorithms primarily focus on strategies to reduce the variance of the DR estimator arising from large IPS. We propose a new approach called the Doubly Robust with Information borrowing and Context-based switching (DR-IC) estimator that focuses on reducing both bias and variance. The DR-IC estimator replaces the standard DM estimator with a parametric reward model that borrows information from the 'closer' contexts through a correlation structure that depends on the IPS. The DR-IC estimator also adaptively interpolates between this modified DM estimator and a modified DR estimator based on a context-specific switching rule. We give provable guarantees on the performance of the DR-IC estimator. We also demonstrate the superior performance of the DR-IC estimator compared to the state-of-the-art OPE algorithms on a number of benchmark problems.