 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Space Cost Fault Tolerance for Transformer-based Language Models on ReRAM
Jan 22, 2024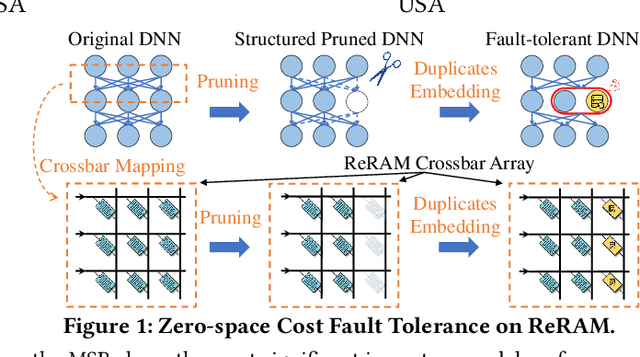

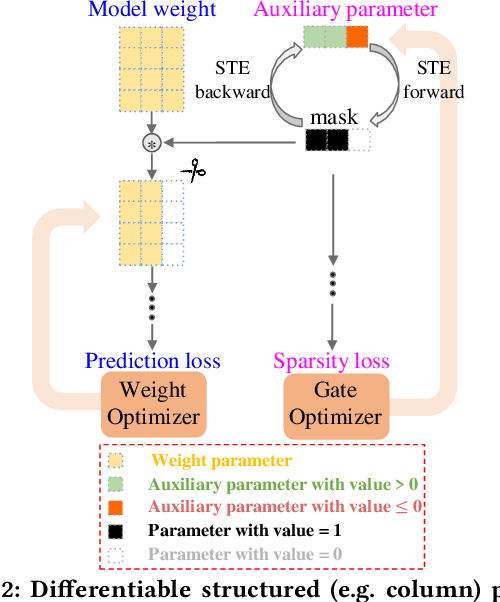

Resistive Random Access Memory (ReRAM) has emerged as a promising platform for deep neural networks (DNNs) due to its support for parallel in-situ matrix-vector multiplication. However, hardware failures, such as stuck-at-fault defects, can result in significant prediction errors during model inference. While additional crossbars can be used to address these failures, they come with storage overhead and are not efficient in terms of space, energy, and cost. In this paper, we propose a fault protection mechanism that incurs zero space cost. Our approach includes: 1) differentiable structure pruning of rows and columns to reduce model redundancy, 2) weight duplication and voting for robust output, and 3) embedding duplicated most significant bits (MSBs) into the model weight. We evaluate our method on nine tasks of the GLUE benchmark with the BERT model, and experimental results prove its effectiveness.
AutoReP: Automatic ReLU Replacement for Fast Private Network Inference
Aug 20, 2023



The growth of the Machine-Learning-As-A-Service (MLaaS) market has highlighted clients' data privacy and security issues. Private inference (PI) techniques using cryptographic primitives offer a solution but often have high computation and communication costs, particularly with non-linear operators like ReLU. Many attempts to reduce ReLU operations exist, but they may need heuristic threshold selection or cause substantial accuracy loss. This work introduces AutoReP, a gradient-based approach to lessen non-linear operators and alleviate these issues. It automates the selection of ReLU and polynomial functions to speed up PI applications and introduces distribution-aware polynomial approximation (DaPa) to maintain model expressivity while accurately approximating ReLUs. Our experimental results demonstrate significant accuracy improvements of 6.12% (94.31%, 12.9K ReLU budget, CIFAR-10), 8.39% (74.92%, 12.9K ReLU budget, CIFAR-100), and 9.45% (63.69%, 55K ReLU budget, Tiny-ImageNet) over current state-of-the-art methods, e.g., SNL. Morever, AutoReP is applied to EfficientNet-B2 on ImageNet dataset, and achieved 75.55% accuracy with 176.1 times ReLU budget reduction.
Deep Learning Based Page Creation for Improving E-Commerce Organic Search Traffic
Sep 25, 2022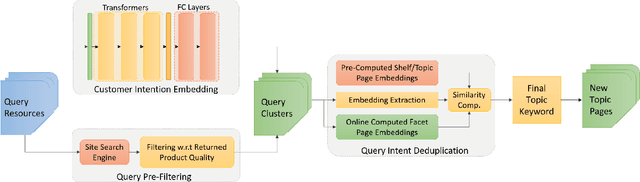

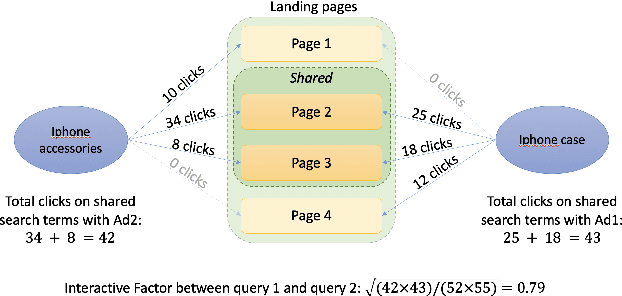

Organic search comprises a large portion of the total traffic for e-commerce companies. One approach to expand company's exposure on organic search channel lies on creating landing pages having broader coverage on customer intentions. In this paper, we present a transformer language model based organic channel page management system aiming at increasing prominence of the company's overall clicks on the channel. Our system successfully handles the creation and deployment process of millions of new landing pages. We show and discuss the real-world performances of state-of-the-art language representation learning method, and reveal how we find them as the production-optimal solutions.
An Efficient Group-based Search Engine Marketing System for E-Commerce
Jul 17, 2021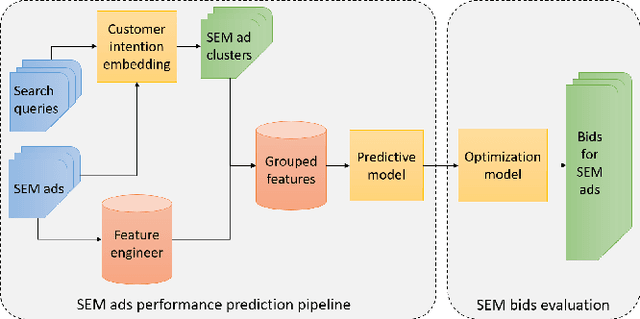
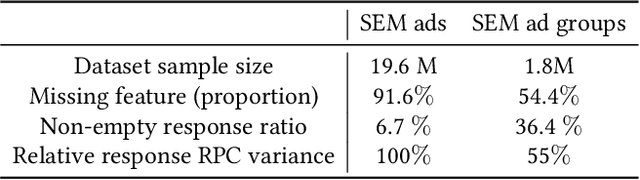
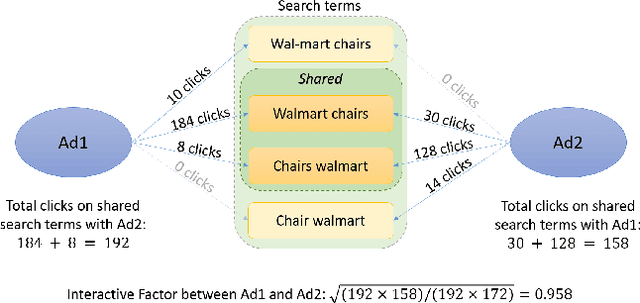

With the increasing scale of search engine marketing, designing an efficient bidding system is becoming paramount for the success of e-commerce companies. The critical challenges faced by a modern industrial-level bidding system include: 1. the catalog is enormous, and the relevant bidding features are of high sparsity; 2. the large volume of bidding requests induces significant computation burden to both the offline and online serving. Leveraging extraneous user-item information proves essential to mitigate the sparsity issue, for which we exploit the natural language signals from the users' query and the contextual knowledge from the products. In particular, we extract the vector representations of ads via the Transformer model and leverage their geometric relation to building collaborative bidding predictions via clustering. The two-step procedure also significantly reduces the computation stress of bid evaluation and optimization. In this paper, we introduce the end-to-end structure of the bidding system for search engine marketing for Walmart e-commerce, which successfully handles tens of millions of bids each day. We analyze the online and offline performances of our approach and discuss how we find it as a production-efficient solution.
MCMIA: Model Compression Against Membership Inference Attack in Deep Neural Networks
Aug 28, 2020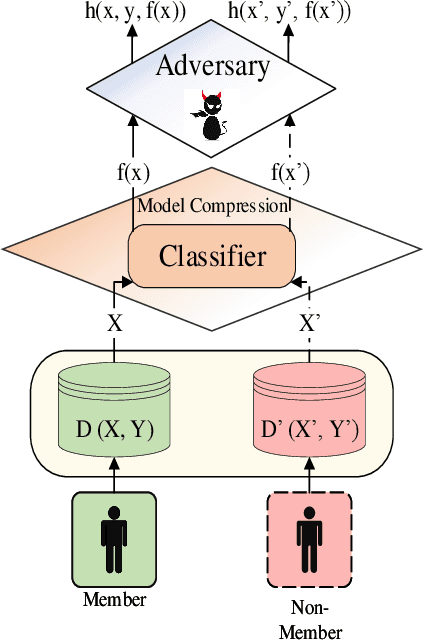
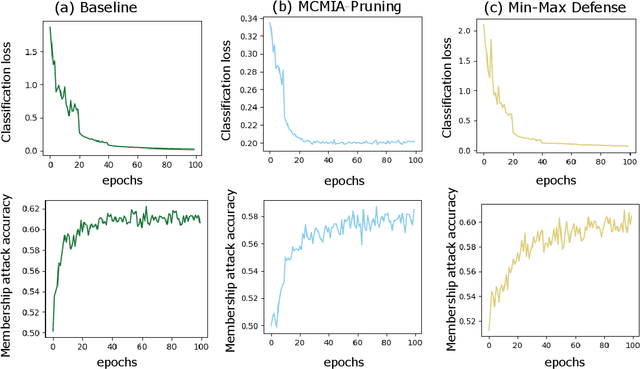
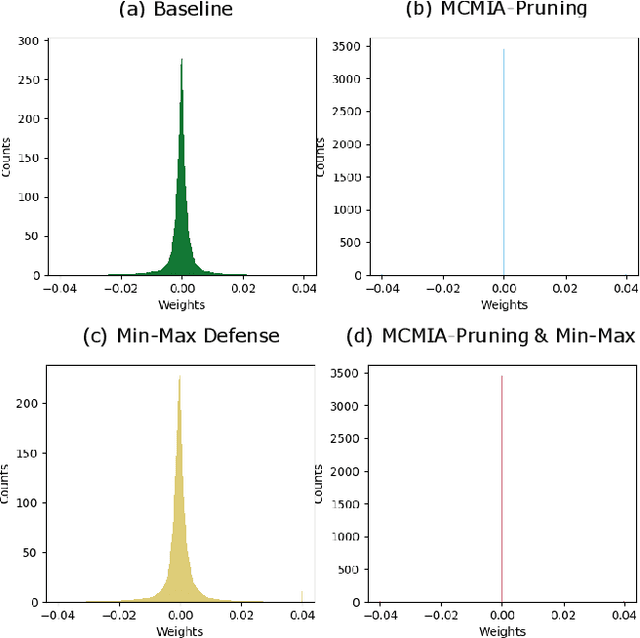
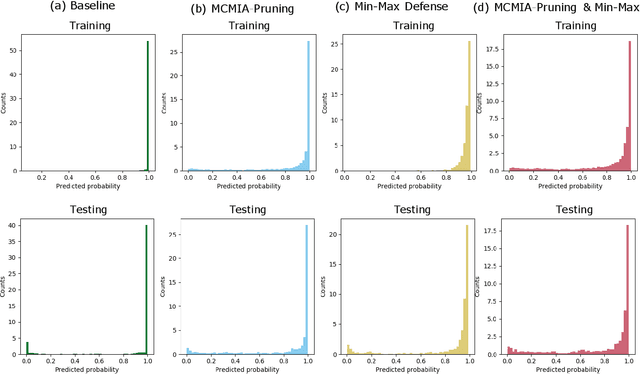
Deep learning or deep neural networks (DNNs) have nowadays enabled high performance, including but not limited to fraud detection, recommendations, and different kinds of analytical transactions. However, the large model size, high computational cost, and vulnerability against membership inference attack (MIA) have impeded its popularity, especially on resource-constrained edge devices. As the first attempt to simultaneously address these challenges, we envision that DNN model compression technique will help deep learning models against MIA while reducing model storage and computational cost. We jointly formulate model compression and MIA as MCMIA, and provide an analytic method of solving the problem. We evaluate our method on LeNet-5, VGG16, MobileNetV2, ResNet18 on different datasets including MNIST, CIFAR-10, CIFAR-100, and ImageNet. Experimental results show that our MCMIA model can reduce the attack accuracy, therefore reduce the information leakage from MIA. Our proposed method significantly outperforms differential privacy (DP) on MIA. Compared with our MCMIA--Pruning, our MCMIA--Pruning \& Min-Max game can achieve the lowest attack accuracy, therefore maximally enhance DNN model privacy. Thanks to the hardware-friendly characteristic of model compression, our proposed MCMIA is especially useful in deploying DNNs on resource-constrained platforms in a privacy-preserving manner.