 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Framework for Boundary-Aware Semantic Segmentation
Mar 28, 2025As a fundamental task in computer vision, semantic segmentation is widely applied in fields such as autonomous driving, remote sensing image analysis, and medical image processing. In recent years, Transformer-based segmentation methods have demonstrated strong performance in global feature modeling. However, they still struggle with blurred target boundaries and insufficient recognition of small targets. To address these issues, this study proposes a Mask2Former-based semantic segmentation algorithm incorporating a boundary enhancement feature bridging module (BEFBM). The goal is to improve target boundary accuracy and segmentation consistency. Built upon the Mask2Former framework, this method constructs a boundary-aware feature map and introduces a feature bridging mechanism. This enables effective cross-scale feature fusion, enhancing the model's ability to focus on target boundaries. Experiments on the Cityscapes dataset demonstrate that, compared to mainstream segmentation methods, the proposed approach achieves significant improvements in metrics such as mIOU, mDICE, and mRecall. It also exhibits superior boundary retention in complex scenes. Visual analysis further confirms the model's advantages in fine-grained regions. Future research will focus on optimizing computational efficiency and exploring its potential in other high-precision segmentation tasks.
Survey for Landing Generative AI in Social and E-commerce Recsys -- the Industry Perspectives
Jun 10, 2024Recently, generative AI (GAI), with their emerging capabilities, have presented unique opportunities for augmenting and revolutionizing industrial recommender systems (Recsys). Despite growing research efforts at the intersection of these fields, the integration of GAI into industrial Recsys remains in its infancy, largely due to the intricate nature of modern industrial Recsys infrastructure, operations, and product sophistication. Drawing upon our experiences in successfully integrating GAI into several major social and e-commerce platforms, this survey aims to comprehensively examine the underlying system and AI foundations, solution frameworks, connections to key research advancements, as well as summarize the practical insights and challenges encountered in the endeavor to integrate GAI into industrial Recsys. As pioneering work in this domain, we hope outline the representative developments of relevant fields, shed lights on practical GAI adoptions in the industry, and motivate future research.
Pretrained Embeddings for E-commerce Machine Learning: When it Fails and Why?
Apr 09, 2023The use of pretrained embeddings has become widespread in modern e-commerce machine learning (ML) systems. In practice, however, we have encountered several key issues when using pretrained embedding in a real-world production system, many of which cannot be fully explained by current knowledge. Unfortunately, we find that there is a lack of a thorough understanding of how pre-trained embeddings work, especially their intrinsic properties and interactions with downstream tasks. Consequently, it becomes challenging to make interactive and scalable decisions regarding the use of pre-trained embeddings in practice. Our investigation leads to two significant discoveries about using pretrained embeddings in e-commerce applications. Firstly, we find that the design of the pretraining and downstream models, particularly how they encode and decode information via embedding vectors, can have a profound impact. Secondly, we establish a principled perspective of pre-trained embeddings via the lens of kernel analysis, which can be used to evaluate their predictability, interactively and scalably. These findings help to address the practical challenges we faced and offer valuable guidance for successful adoption of pretrained embeddings in real-world production. Our conclusions are backed by solid theoretical reasoning, benchmark experiments, as well as online testings.
Causal Structure Learning with Recommendation System
Oct 19, 2022
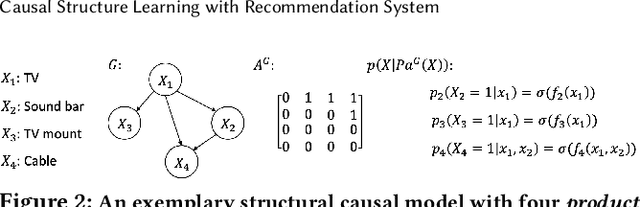
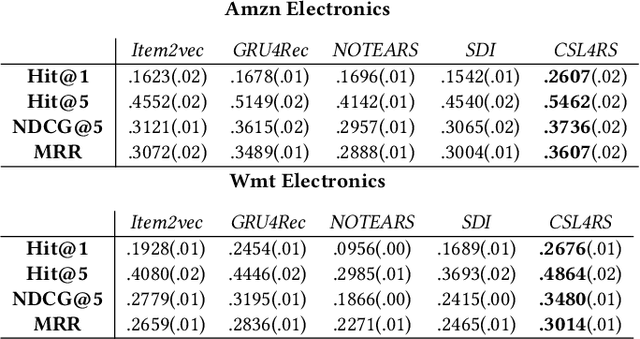
A fundamental challenge of recommendation systems (RS) is understanding the causal dynamics underlying users' decision making. Most existing literature addresses this problem by using causal structures inferred from domain knowledge. However, there are numerous phenomenons where domain knowledge is insufficient, and the causal mechanisms must be learnt from the feedback data. Discovering the causal mechanism from RS feedback data is both novel and challenging, since RS itself is a source of intervention that can influence both the users' exposure and their willingness to interact. Also for this reason, most existing solutions become inappropriate since they require data collected free from any RS. In this paper, we first formulate the underlying causal mechanism as a causal structural model and describe a general causal structure learning framework grounded in the real-world working mechanism of RS. The essence of our approach is to acknowledge the unknown nature of RS intervention. We then derive the learning objective from our framework and propose an augmented Lagrangian solver for efficient optimization. We conduct both simulation and real-world experiments to demonstrate how our approach compares favorably to existing solutions, together with the empirical analysis from sensitivity and ablation studies.
Deep Learning Based Page Creation for Improving E-Commerce Organic Search Traffic
Sep 25, 2022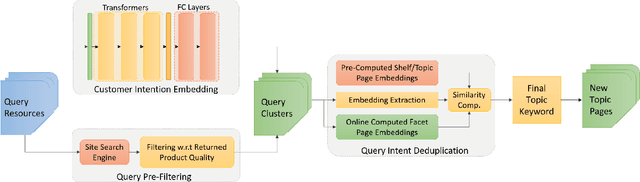

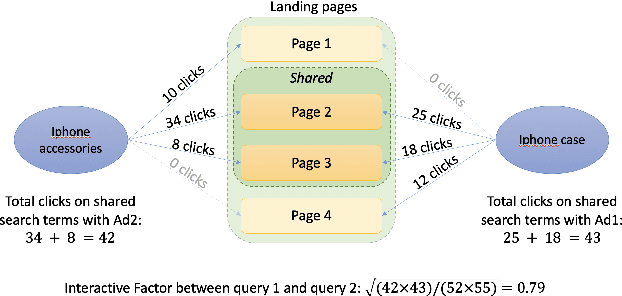

Organic search comprises a large portion of the total traffic for e-commerce companies. One approach to expand company's exposure on organic search channel lies on creating landing pages having broader coverage on customer intentions. In this paper, we present a transformer language model based organic channel page management system aiming at increasing prominence of the company's overall clicks on the channel. Our system successfully handles the creation and deployment process of millions of new landing pages. We show and discuss the real-world performances of state-of-the-art language representation learning method, and reveal how we find them as the production-optimal solutions.
Tutorial: Modern Theoretical Tools for Understanding and Designing Next-generation Information Retrieval System
Mar 26, 2022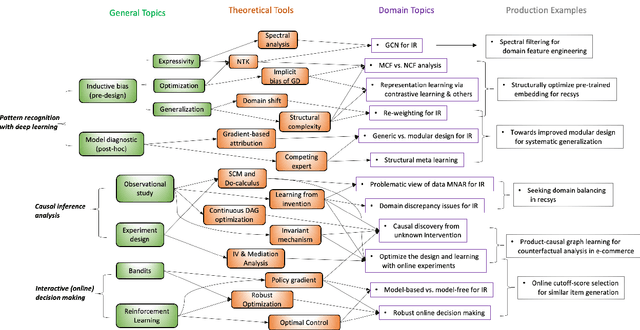
In the relatively short history of machine learning, the subtle balance between engineering and theoretical progress has been proved critical at various stages. The most recent wave of AI has brought to the IR community powerful techniques, particularly for pattern recognition. While many benefits from the burst of ideas as numerous tasks become algorithmically feasible, the balance is tilting toward the application side. The existing theoretical tools in IR can no longer explain, guide, and justify the newly-established methodologies. The consequences can be suffering: in stark contrast to how the IR industry has envisioned modern AI making life easier, many are experiencing increased confusion and costs in data manipulation, model selection, monitoring, censoring, and decision making. This reality is not surprising: without handy theoretical tools, we often lack principled knowledge of the pattern recognition model's expressivity, optimization property, generalization guarantee, and our decision-making process has to rely on over-simplified assumptions and human judgments from time to time. Time is now to bring the community a systematic tutorial on how we successfully adapt those tools and make significant progress in understanding, designing, and eventually productionize impactful IR systems. We emphasize systematicity because IR is a comprehensive discipline that touches upon particular aspects of learning, causal inference analysis, interactive (online) decision-making, etc. It thus requires systematic calibrations to render the actual usefulness of the imported theoretical tools to serve IR problems, as they usually exhibit unique structures and definitions. Therefore, we plan this tutorial to systematically demonstrate our learning and successful experience of using advanced theoretical tools for understanding and designing IR systems.
From Intervention to Domain Transportation: A Novel Perspective to Optimize Recommendation
Mar 26, 2022
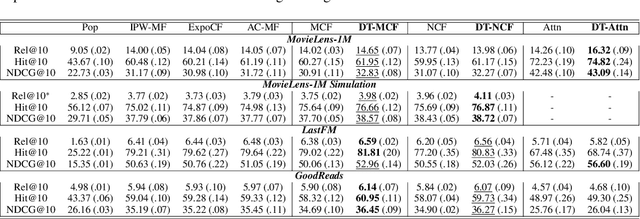
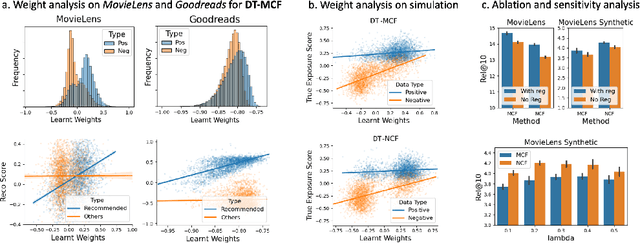
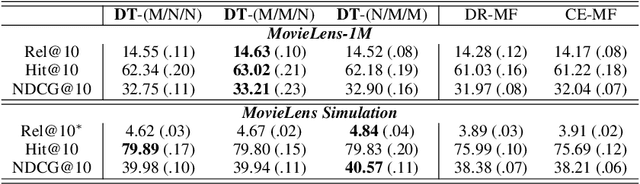
The interventional nature of recommendation has attracted increasing attention in recent years. It particularly motivates researchers to formulate learning and evaluating recommendation as causal inference and data missing-not-at-random problems. However, few take seriously the consequence of violating the critical assumption of overlapping, which we prove can significantly threaten the validity and interpretation of the outcome. We find a critical piece missing in the current understanding of information retrieval (IR) systems: as interventions, recommendation not only affects the already observed data, but it also interferes with the target domain (distribution) of interest. We then rephrase optimizing recommendation as finding an intervention that best transports the patterns it learns from the observed domain to its intervention domain. Towards this end, we use domain transportation to characterize the learning-intervention mechanism of recommendation. We design a principled transportation-constraint risk minimization objective and convert it to a two-player minimax game. We prove the consistency, generalization, and excessive risk bounds for the proposed objective, and elaborate how they compare to the current results. Finally, we carry out extensive real-data and semi-synthetic experiments to demonstrate the advantage of our approach, and launch online testing with a real-world IR system.
On the Advances and Challenges of Adaptive Online Testing
Mar 15, 2022In recent years, the interest in developing adaptive solutions for online testing has grown significantly in the industry. While the advances related to this relative new technology have been developed in multiple domains, it lacks in the literature a systematic and complete treatment of the procedure that involves exploration, inference, and analysis. This short paper aims to develop a comprehensive understanding of adaptive online testing, including various building blocks and analytical results. We also address the latest developments, research directions, and challenges that have been less mentioned in the literature.
Towards Robust Off-policy Learning for Runtime Uncertainty
Feb 27, 2022
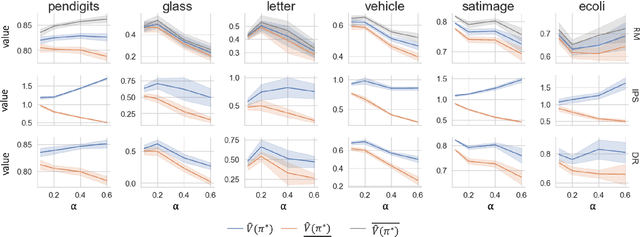
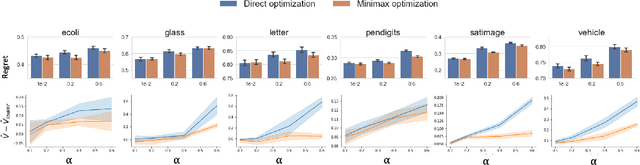

Off-policy learning plays a pivotal role in optimizing and evaluating policies prior to the online deployment. However, during the real-time serving, we observe varieties of interventions and constraints that cause inconsistency between the online and offline settings, which we summarize and term as runtime uncertainty. Such uncertainty cannot be learned from the logged data due to its abnormality and rareness nature. To assert a certain level of robustness, we perturb the off-policy estimators along an adversarial direction in view of the runtime uncertainty. It allows the resulting estimators to be robust not only to observed but also unexpected runtime uncertainties. Leveraging this idea, we bring runtime-uncertainty robustness to three major off-policy learning methods: the inverse propensity score method, reward-model method, and doubly robust method. We theoretically justify the robustness of our methods to runtime uncertainty, and demonstrate their effectiveness using both the simulation and the real-world online experiments.
Clutter Edges Detection Algorithms for Structured Clutter Covariance Matrices
Feb 03, 2022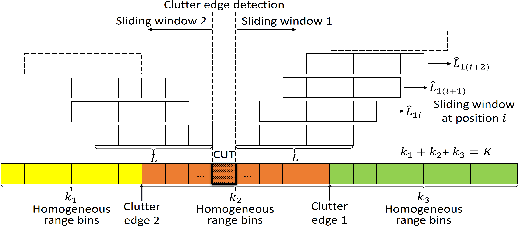
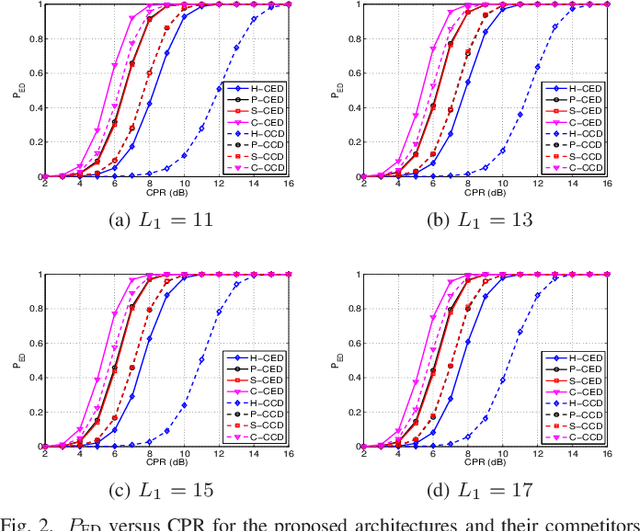
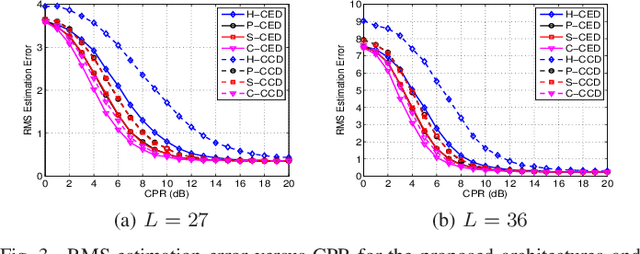
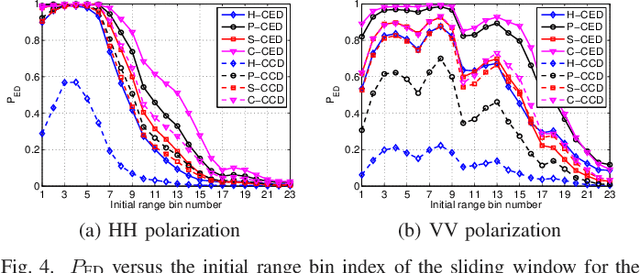
This letter deals with the problem of clutter edge detection and localization in training data. To this end, the problem is formulated as a binary hypothesis test assuming that the ranks of the clutter covariance matrix are known, and adaptive architectures are designed based on the generalized likelihood ratio test to decide whether the training data within a sliding window contains a homogeneous set or two heterogeneous subsets. In the design stage, we utilize four different covariance matrix structures (i.e., Hermitian, persymmetric, symmetric, and centrosymmetric) to exploit the a priori information. Then, for the case of unknown ranks, the architectures are extended by devising a preliminary estimation stage resorting to the model order selection rules. Numerical examples based on both synthetic and real data highlight that the proposed solutions possess superior detection and localization performance with respect to the competitors that do not use any a priori information.