 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Graph Convolution and Sequential Modeling for Scalable Network Traffic Estimation
May 12, 2025This study focuses on the challenge of predicting network traffic within complex topological environments. It introduces a spatiotemporal modeling approach that integrates Graph Convolutional Networks (GCN) with Gated Recurrent Units (GRU). The GCN component captures spatial dependencies among network nodes, while the GRU component models the temporal evolution of traffic data. This combination allows for precise forecasting of future traffic patterns. The effectiveness of the proposed model is validated through comprehensive experiments on the real-world Abilene network traffic dataset. The model is benchmarked against several popular deep learning methods. Furthermore, a set of ablation experiments is conducted to examine the influence of various components on performance, including changes in the number of graph convolution layers, different temporal modeling strategies, and methods for constructing the adjacency matrix. Results indicate that the proposed approach achieves superior performance across multiple metrics, demonstrating robust stability and strong generalization capabilities in complex network traffic forecasting scenarios.
Towards Robust Few-Shot Text Classification Using Transformer Architectures and Dual Loss Strategies
May 09, 2025
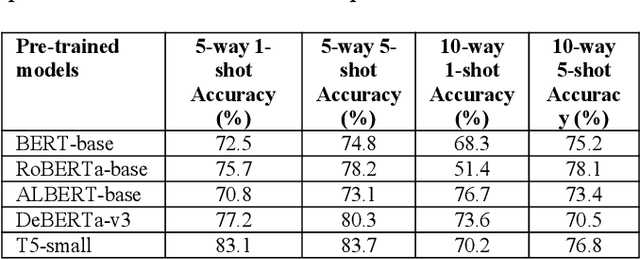
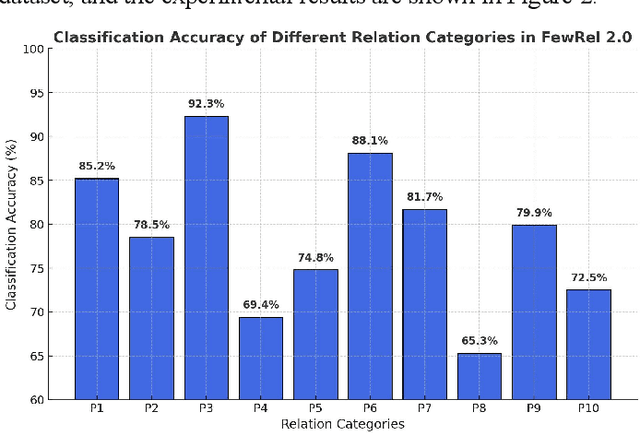
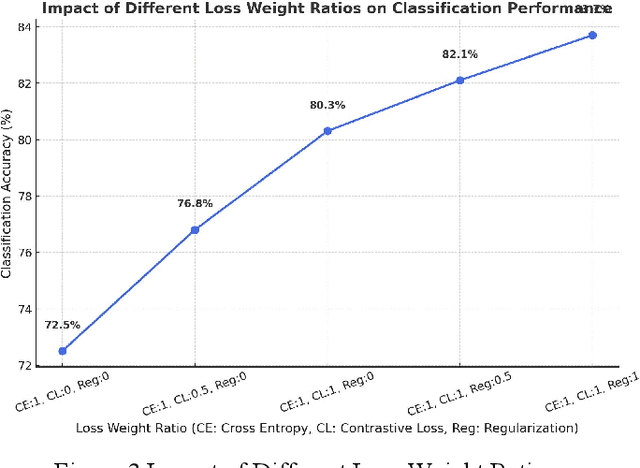
Few-shot text classification has important application value in low-resource environments. This paper proposes a strategy that combines adaptive fine-tuning, contrastive learning, and regularization optimization to improve the classification performance of Transformer-based models. Experiments on the FewRel 2.0 dataset show that T5-small, DeBERTa-v3, and RoBERTa-base perform well in few-shot tasks, especially in the 5-shot setting, which can more effectively capture text features and improve classification accuracy. The experiment also found that there are significant differences in the classification difficulty of different relationship categories. Some categories have fuzzy semantic boundaries or complex feature distributions, making it difficult for the standard cross entropy loss to learn the discriminative information required to distinguish categories. By introducing contrastive loss and regularization loss, the generalization ability of the model is enhanced, effectively alleviating the overfitting problem in few-shot environments. In addition, the research results show that the use of Transformer models or generative architectures with stronger self-attention mechanisms can help improve the stability and accuracy of few-shot classification.
State-Aware IoT Scheduling Using Deep Q-Networks and Edge-Based Coordination
Apr 22, 2025This paper addresses the challenge of energy efficiency management faced by intelligent IoT devices in complex application environments. A novel optimization method is proposed, combining Deep Q-Network (DQN) with an edge collaboration mechanism. The method builds a state-action-reward interaction model and introduces edge nodes as intermediaries for state aggregation and policy scheduling. This enables dynamic resource coordination and task allocation among multiple devices. During the modeling process, device status, task load, and network resources are jointly incorporated into the state space. The DQN is used to approximate and learn the optimal scheduling strategy. To enhance the model's ability to perceive inter-device relationships, a collaborative graph structure is introduced to model the multi-device environment and assist in decision optimization. Experiments are conducted using real-world IoT data collected from the FastBee platform. Several comparative and validation tests are performed, including energy efficiency comparisons across different scheduling strategies, robustness analysis under varying task loads, and evaluation of state dimension impacts on policy convergence speed. The results show that the proposed method outperforms existing baseline approaches in terms of average energy consumption, processing latency, and resource utilization. This confirms its effectiveness and practicality in intelligent IoT scenarios.
Context-Aware Adaptive Sampling for Intelligent Data Acquisition Systems Using DQN
Apr 12, 2025



Multi-sensor systems are widely used in the Internet of Things, environmental monitoring, and intelligent manufacturing. However, traditional fixed-frequency sampling strategies often lead to severe data redundancy, high energy consumption, and limited adaptability, failing to meet the dynamic sensing needs of complex environments. To address these issues, this paper proposes a DQN-based multi-sensor adaptive sampling optimization method. By leveraging a reinforcement learning framework to learn the optimal sampling strategy, the method balances data quality, energy consumption, and redundancy. We first model the multi-sensor sampling task as a Markov Decision Process (MDP), then employ a Deep Q-Network to optimize the sampling policy. Experiments on the Intel Lab Data dataset confirm that, compared with fixed-frequency sampling, threshold-triggered sampling, and other reinforcement learning approaches, DQN significantly improves data quality while lowering average energy consumption and redundancy rates. Moreover, in heterogeneous multi-sensor environments, DQN-based adaptive sampling shows enhanced robustness, maintaining superior data collection performance even in the presence of interference factors. These findings demonstrate that DQN-based adaptive sampling can enhance overall data acquisition efficiency in multi-sensor systems, providing a new solution for efficient and intelligent sensing.
Improving Harmful Text Detection with Joint Retrieval and External Knowledge
Apr 03, 2025Harmful text detection has become a crucial task in the development and deployment of large language models, especially as AI-generated content continues to expand across digital platforms. This study proposes a joint retrieval framework that integrates pre-trained language models with knowledge graphs to improve the accuracy and robustness of harmful text detection. Experimental results demonstrate that the joint retrieval approach significantly outperforms single-model baselines, particularly in low-resource training scenarios and multilingual environments. The proposed method effectively captures nuanced harmful content by leveraging external contextual information, addressing the limitations of traditional detection models. Future research should focus on optimizing computational efficiency, enhancing model interpretability, and expanding multimodal detection capabilities to better tackle evolving harmful content patterns. This work contributes to the advancement of AI safety, ensuring more trustworthy and reliable content moderation systems.
A Deep Learning Framework for Boundary-Aware Semantic Segmentation
Mar 28, 2025As a fundamental task in computer vision, semantic segmentation is widely applied in fields such as autonomous driving, remote sensing image analysis, and medical image processing. In recent years, Transformer-based segmentation methods have demonstrated strong performance in global feature modeling. However, they still struggle with blurred target boundaries and insufficient recognition of small targets. To address these issues, this study proposes a Mask2Former-based semantic segmentation algorithm incorporating a boundary enhancement feature bridging module (BEFBM). The goal is to improve target boundary accuracy and segmentation consistency. Built upon the Mask2Former framework, this method constructs a boundary-aware feature map and introduces a feature bridging mechanism. This enables effective cross-scale feature fusion, enhancing the model's ability to focus on target boundaries. Experiments on the Cityscapes dataset demonstrate that, compared to mainstream segmentation methods, the proposed approach achieves significant improvements in metrics such as mIOU, mDICE, and mRecall. It also exhibits superior boundary retention in complex scenes. Visual analysis further confirms the model's advantages in fine-grained regions. Future research will focus on optimizing computational efficiency and exploring its potential in other high-precision segmentation tasks.