 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Harmful Text Detection with Joint Retrieval and External Knowledge
Apr 03, 2025Harmful text detection has become a crucial task in the development and deployment of large language models, especially as AI-generated content continues to expand across digital platforms. This study proposes a joint retrieval framework that integrates pre-trained language models with knowledge graphs to improve the accuracy and robustness of harmful text detection. Experimental results demonstrate that the joint retrieval approach significantly outperforms single-model baselines, particularly in low-resource training scenarios and multilingual environments. The proposed method effectively captures nuanced harmful content by leveraging external contextual information, addressing the limitations of traditional detection models. Future research should focus on optimizing computational efficiency, enhancing model interpretability, and expanding multimodal detection capabilities to better tackle evolving harmful content patterns. This work contributes to the advancement of AI safety, ensuring more trustworthy and reliable content moderation systems.
Research on the Online Update Method for Retrieval-Augmented Generation (RAG) Model with Incremental Learning
Jan 13, 2025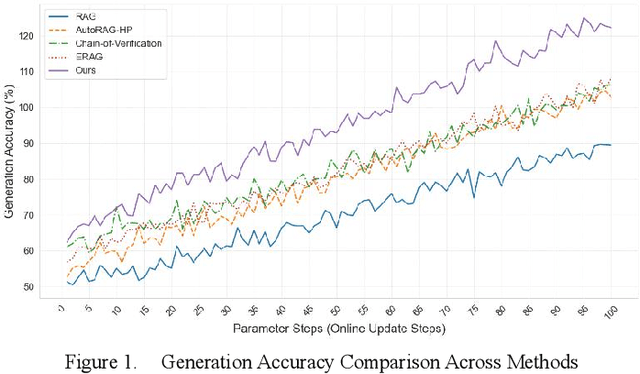
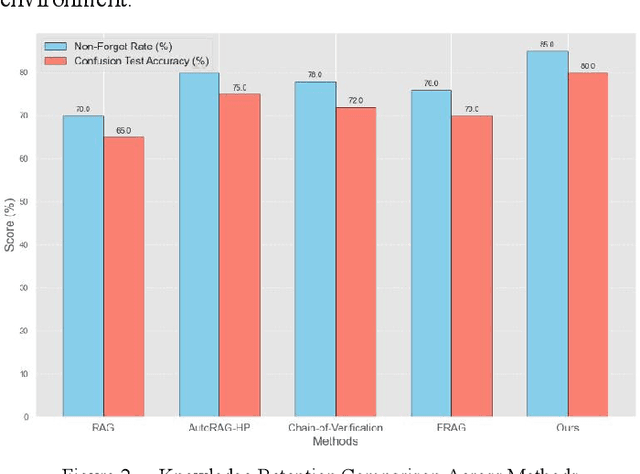
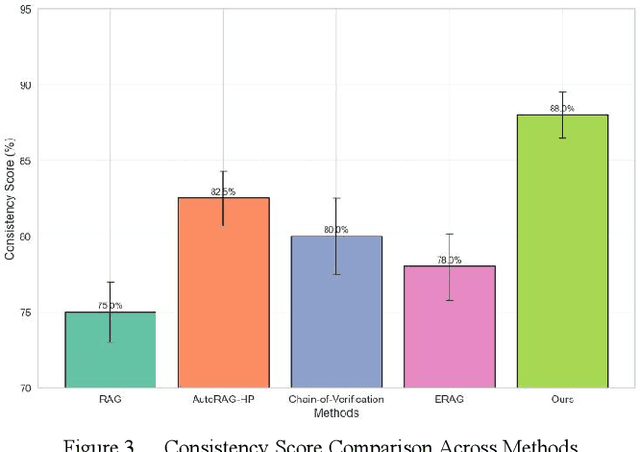
In the contemporary context of rapid advancements in information technology and the exponential growth of data volume, language models are confronted with significant challenges in effectively navigating the dynamic and ever-evolving information landscape to update and adapt to novel knowledge in real time. In this work, an online update method is proposed, which is based on the existing Retrieval Enhanced Generation (RAG) model with multiple innovation mechanisms. Firstly, the dynamic memory is used to capture the emerging data samples, and then gradually integrate them into the core model through a tunable knowledge distillation strategy. At the same time, hierarchical indexing and multi-layer gating mechanism are introduced into the retrieval module to ensure that the retrieved content is more targeted and accurate. Finally, a multi-stage network structure is established for different types of inputs in the generation stage, and cross-attention matching and screening are carried out on the intermediate representations of each stage to ensure the effective integration and iterative update of new and old knowledge. Experimental results show that the proposed method is better than the existing mainstream comparison models in terms of knowledge retention and inference accuracy.