 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex Environments
Dec 19, 2025



This paper proposes VLA-AN, an efficient and onboard Vision-Language-Action (VLA) framework dedicated to autonomous drone navigation in complex environments. VLA-AN addresses four major limitations of existing large aerial navigation models: the data domain gap, insufficient temporal navigation with reasoning, safety issues with generative action policies, and onboard deployment constraints. First, we construct a high-fidelity dataset utilizing 3D Gaussian Splatting (3D-GS) to effectively bridge the domain gap. Second, we introduce a progressive three-stage training framework that sequentially reinforces scene comprehension, core flight skills, and complex navigation capabilities. Third, we design a lightweight, real-time action module coupled with geometric safety correction. This module ensures fast, collision-free, and stable command generation, mitigating the safety risks inherent in stochastic generative policies. Finally, through deep optimization of the onboard deployment pipeline, VLA-AN achieves a robust real-time 8.3x improvement in inference throughput on resource-constrained UAVs. Extensive experiments demonstrate that VLA-AN significantly improves spatial grounding, scene reasoning, and long-horizon navigation, achieving a maximum single-task success rate of 98.1%, and providing an efficient, practical solution for realizing full-chain closed-loop autonomy in lightweight aerial robots.
Research on the Online Update Method for Retrieval-Augmented Generation (RAG) Model with Incremental Learning
Jan 13, 2025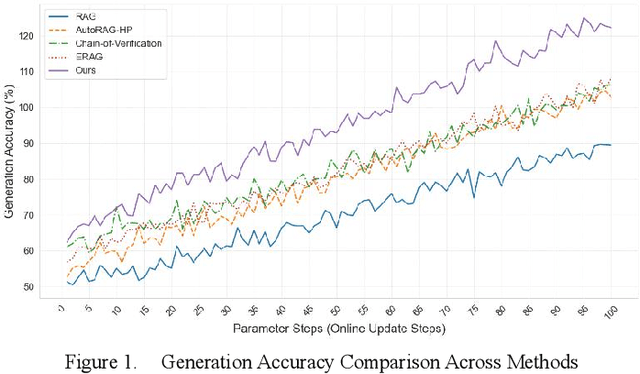
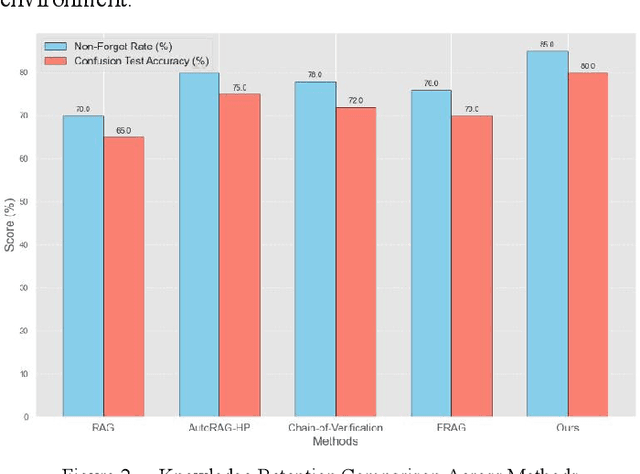
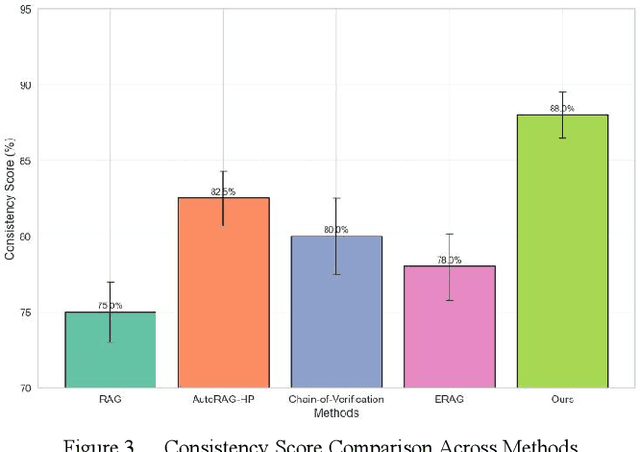
In the contemporary context of rapid advancements in information technology and the exponential growth of data volume, language models are confronted with significant challenges in effectively navigating the dynamic and ever-evolving information landscape to update and adapt to novel knowledge in real time. In this work, an online update method is proposed, which is based on the existing Retrieval Enhanced Generation (RAG) model with multiple innovation mechanisms. Firstly, the dynamic memory is used to capture the emerging data samples, and then gradually integrate them into the core model through a tunable knowledge distillation strategy. At the same time, hierarchical indexing and multi-layer gating mechanism are introduced into the retrieval module to ensure that the retrieved content is more targeted and accurate. Finally, a multi-stage network structure is established for different types of inputs in the generation stage, and cross-attention matching and screening are carried out on the intermediate representations of each stage to ensure the effective integration and iterative update of new and old knowledge. Experimental results show that the proposed method is better than the existing mainstream comparison models in terms of knowledge retention and inference accuracy.
Research on Optimizing Real-Time Data Processing in High-Frequency Trading Algorithms using Machine Learning
Dec 02, 2024High-frequency trading (HFT) represents a pivotal and intensely competitive domain within the financial markets. The velocity and accuracy of data processing exert a direct influence on profitability, underscoring the significance of this field. The objective of this work is to optimise the real-time processing of data in high-frequency trading algorithms. The dynamic feature selection mechanism is responsible for monitoring and analysing market data in real time through clustering and feature weight analysis, with the objective of automatically selecting the most relevant features. This process employs an adaptive feature extraction method, which enables the system to respond and adjust its feature set in a timely manner when the data input changes, thus ensuring the efficient utilisation of data. The lightweight neural networks are designed in a modular fashion, comprising fast convolutional layers and pruning techniques that facilitate the expeditious completion of data processing and output prediction. In contrast to conventional deep learning models, the neural network architecture has been specifically designed to minimise the number of parameters and computational complexity, thereby markedly reducing the inference time. The experimental results demonstrate that the model is capable of maintaining consistent performance in the context of varying market conditions, thereby illustrating its advantages in terms of processing speed and revenue enhancement.
A New Approach to Solving SMAC Task: Generating Decision Tree Code from Large Language Models
Oct 21, 2024StarCraft Multi-Agent Challenge (SMAC) is one of the most commonly used experimental environments in multi-agent reinforcement learning (MARL), where the specific task is to control a set number of allied units to defeat enemy forces. Traditional MARL algorithms often require interacting with the environment for up to 1 million steps to train a model, and the resulting policies are typically non-interpretable with weak transferability. In this paper, we propose a novel approach to solving SMAC tasks called LLM-SMAC. In our framework, agents leverage large language models (LLMs) to generate decision tree code by providing task descriptions. The model is further self-reflection using feedback from the rewards provided by the environment. We conduct experiments in the SMAC and demonstrate that our method can produce high-quality, interpretable decision trees with minimal environmental exploration. Moreover, these models exhibit strong transferability, successfully applying to similar SMAC environments without modification. We believe this approach offers a new direction for solving decision-making tasks in the future.