 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCMIA: Model Compression Against Membership Inference Attack in Deep Neural Networks
Paper and Code
Aug 28, 2020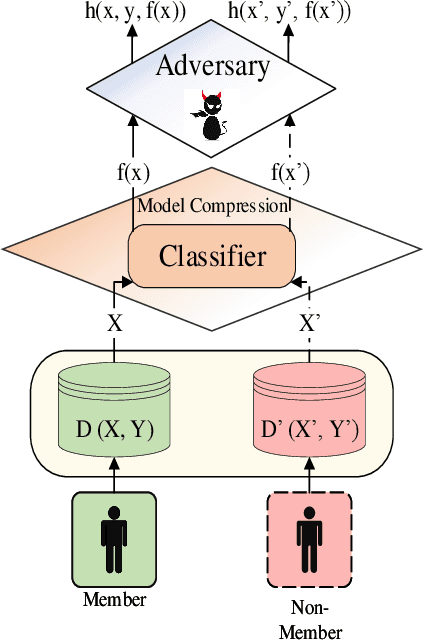
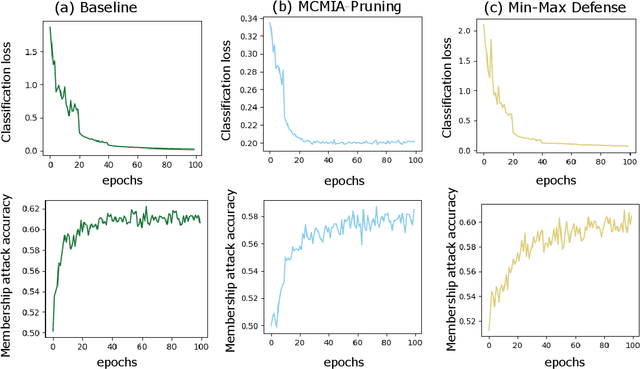
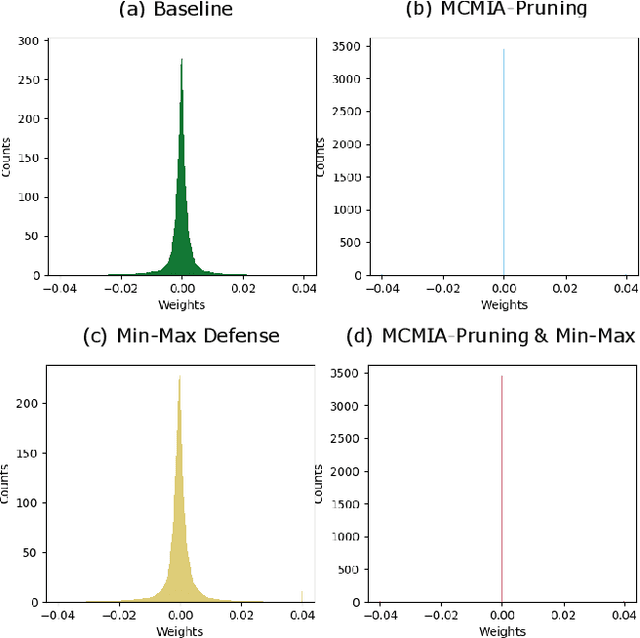
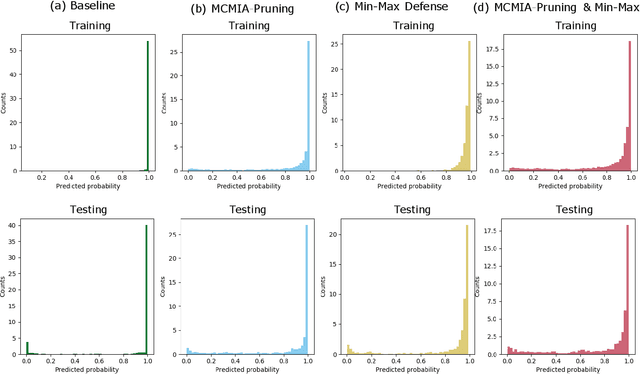
Deep learning or deep neural networks (DNNs) have nowadays enabled high performance, including but not limited to fraud detection, recommendations, and different kinds of analytical transactions. However, the large model size, high computational cost, and vulnerability against membership inference attack (MIA) have impeded its popularity, especially on resource-constrained edge devices. As the first attempt to simultaneously address these challenges, we envision that DNN model compression technique will help deep learning models against MIA while reducing model storage and computational cost. We jointly formulate model compression and MIA as MCMIA, and provide an analytic method of solving the problem. We evaluate our method on LeNet-5, VGG16, MobileNetV2, ResNet18 on different datasets including MNIST, CIFAR-10, CIFAR-100, and ImageNet. Experimental results show that our MCMIA model can reduce the attack accuracy, therefore reduce the information leakage from MIA. Our proposed method significantly outperforms differential privacy (DP) on MIA. Compared with our MCMIA--Pruning, our MCMIA--Pruning \& Min-Max game can achieve the lowest attack accuracy, therefore maximally enhance DNN model privacy. Thanks to the hardware-friendly characteristic of model compression, our proposed MCMIA is especially useful in deploying DNNs on resource-constrained platforms in a privacy-preserving manner.