 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMA: Structure-Invariant Generative Molecular Alignment for Chemical Language Models via Autoregressive Contrastive Learning
Mar 26, 2026Linearized string representations serve as the foundation of scalable autoregressive molecular generation; however, they introduce a fundamental modality mismatch where a single molecular graph maps to multiple distinct sequences. This ambiguity leads to \textit{trajectory divergence}, where the latent representations of structurally equivalent partial graphs drift apart due to differences in linearization history. To resolve this without abandoning the efficient string formulation, we propose Structure-Invariant Generative Molecular Alignment (SIGMA). Rather than altering the linear representation, SIGMA enables the model to strictly recognize geometric symmetries via a token-level contrastive objective, which explicitly aligns the latent states of prefixes that share identical suffixes. Furthermore, we introduce Isomorphic Beam Search (IsoBeam) to eliminate isomorphic redundancy during inference by dynamically pruning equivalent paths. Empirical evaluations on standard benchmarks demonstrate that SIGMA bridges the gap between sequence scalability and graph fidelity, yielding superior sample efficiency and structural diversity in multi-parameter optimization compared to strong baselines.
LARV: Data-Free Layer-wise Adaptive Rescaling Veneer for Model Merging
Feb 10, 2026Model merging aims to combine multiple fine-tuned models into a single multi-task model without access to training data. Existing task-vector merging methods such as TIES, TSV-M, and Iso-C/CTS differ in their aggregation rules but treat all layers nearly uniformly. This assumption overlooks the strong layer-wise heterogeneity in large vision transformers, where shallow layers are sensitive to interference while deeper layers encode stable task-specific features. We introduce LARV, a training-free, data-free, merger-agnostic Layer-wise Adaptive Rescaling Veneer that plugs into any task-vector merger and assigns a per-layer scale to each task vector before aggregation, and show it consistently boosts diverse merging rules. LARV adaptively suppresses shallow-layer interference and amplifies deeper-layer alignment using a simple deterministic schedule, requiring no retraining or modification to existing mergers. To our knowledge, this is the first work to perform layer-aware scaling for task-vector merging. LARV computes simple data-free layer proxies and turns them into scales through a lightweight rule; we study several instantiations within one framework (e.g., tiered two/three-level scaling with fixed values, or continuous mappings) and show that tiered choices offer the best robustness, while continuous mappings remain an ablation. LARV is orthogonal to the base merger and adds negligible cost. On FusionBench with Vision Transformers, LARV consistently improves all task-vector baselines across 8/14/20-task settings; for example, Iso-C + LARV reaches 85.9% on ViT-B/32, 89.2% on ViT-B/16, and 92.6% on ViT-L/14. Layerwise analysis and corruption tests further indicate that LARV suppresses shallow-layer interference while modestly amplifying deeper, task-stable features, turning model merging into a robust, layer-aware procedure rather than a uniform one.
VEDA: 3D Molecular Generation via Variance-Exploding Diffusion with Annealing
Nov 11, 2025Diffusion models show promise for 3D molecular generation, but face a fundamental trade-off between sampling efficiency and conformational accuracy. While flow-based models are fast, they often produce geometrically inaccurate structures, as they have difficulty capturing the multimodal distributions of molecular conformations. In contrast, denoising diffusion models are more accurate but suffer from slow sampling, a limitation attributed to sub-optimal integration between diffusion dynamics and SE(3)-equivariant architectures. To address this, we propose VEDA, a unified SE(3)-equivariant framework that combines variance-exploding diffusion with annealing to efficiently generate conformationally accurate 3D molecular structures. Specifically, our key technical contributions include: (1) a VE schedule that enables noise injection functionally analogous to simulated annealing, improving 3D accuracy and reducing relaxation energy; (2) a novel preconditioning scheme that reconciles the coordinate-predicting nature of SE(3)-equivariant networks with a residual-based diffusion objective, and (3) a new arcsin-based scheduler that concentrates sampling in critical intervals of the logarithmic signal-to-noise ratio. On the QM9 and GEOM-DRUGS datasets, VEDA matches the sampling efficiency of flow-based models, achieving state-of-the-art valency stability and validity with only 100 sampling steps. More importantly, VEDA's generated structures are remarkably stable, as measured by their relaxation energy during GFN2-xTB optimization. The median energy change is only 1.72 kcal/mol, significantly lower than the 32.3 kcal/mol from its architectural baseline, SemlaFlow. Our framework demonstrates that principled integration of VE diffusion with SE(3)-equivariant architectures can achieve both high chemical accuracy and computational efficiency.
Leveraging Partial SMILES Validation Scheme for Enhanced Drug Design in Reinforcement Learning Frameworks
May 01, 2025SMILES-based molecule generation has emerged as a powerful approach in drug discovery. Deep reinforcement learning (RL) using large language model (LLM) has been incorporated into the molecule generation process to achieve high matching score in term of likelihood of desired molecule candidates. However, a critical challenge in this approach is catastrophic forgetting during the RL phase, where knowledge such as molecule validity, which often exceeds 99\% during pretraining, significantly deteriorates. Current RL algorithms applied in drug discovery, such as REINVENT, use prior models as anchors to retian pretraining knowledge, but these methods lack robust exploration mechanisms. To address these issues, we propose Partial SMILES Validation-PPO (PSV-PPO), a novel RL algorithm that incorporates real-time partial SMILES validation to prevent catastrophic forgetting while encouraging exploration. Unlike traditional RL approaches that validate molecule structures only after generating entire sequences, PSV-PPO performs stepwise validation at each auto-regressive step, evaluating not only the selected token candidate but also all potential branches stemming from the prior partial sequence. This enables early detection of invalid partial SMILES across all potential paths. As a result, PSV-PPO maintains high validity rates even during aggressive exploration of the vast chemical space. Our experiments on the PMO and GuacaMol benchmark datasets demonstrate that PSV-PPO significantly reduces the number of invalid generated structures while maintaining competitive exploration and optimization performance. While our work primarily focuses on maintaining validity, the framework of PSV-PPO can be extended in future research to incorporate additional forms of valuable domain knowledge, further enhancing reinforcement learning applications in drug discovery.
Cross-platform Prediction of Depression Treatment Outcome Using Location Sensory Data on Smartphones
Mar 10, 2025Currently, depression treatment relies on closely monitoring patients response to treatment and adjusting the treatment as needed. Using self-reported or physician-administrated questionnaires to monitor treatment response is, however, burdensome, costly and suffers from recall bias. In this paper, we explore using location sensory data collected passively on smartphones to predict treatment outcome. To address heterogeneous data collection on Android and iOS phones, the two predominant smartphone platforms, we explore using domain adaptation techniques to map their data to a common feature space, and then use the data jointly to train machine learning models. Our results show that this domain adaptation approach can lead to significantly better prediction than that with no domain adaptation. In addition, our results show that using location features and baseline self-reported questionnaire score can lead to F1 score up to 0.67, comparable to that obtained using periodic self-reported questionnaires, indicating that using location data is a promising direction for predicting depression treatment outcome.
Certifying Adapters: Enabling and Enhancing the Certification of Classifier Adversarial Robustness
May 25, 2024
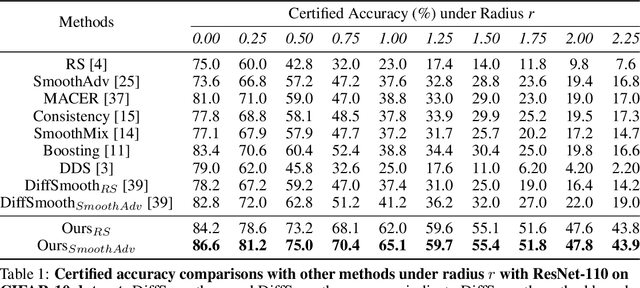
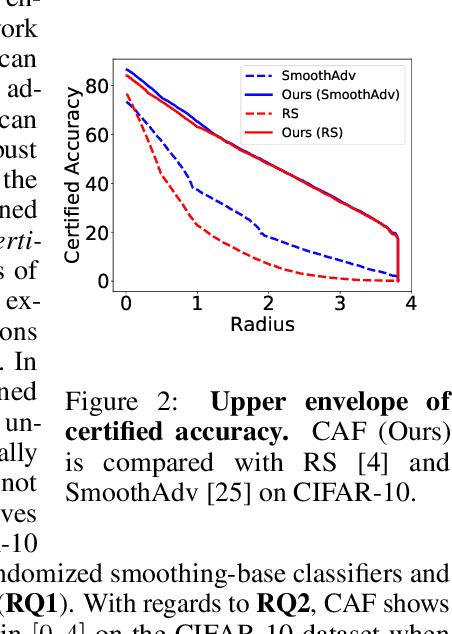

Randomized smoothing has become a leading method for achieving certified robustness in deep classifiers against l_{p}-norm adversarial perturbations. Current approaches for achieving certified robustness, such as data augmentation with Gaussian noise and adversarial training, require expensive training procedures that tune large models for different Gaussian noise levels and thus cannot leverage high-performance pre-trained neural networks. In this work, we introduce a novel certifying adapters framework (CAF) that enables and enhances the certification of classifier adversarial robustness. Our approach makes few assumptions about the underlying training algorithm or feature extractor and is thus broadly applicable to different feature extractor architectures (e.g., convolutional neural networks or vision transformers) and smoothing algorithms. We show that CAF (a) enables certification in uncertified models pre-trained on clean datasets and (b) substantially improves the performance of certified classifiers via randomized smoothing and SmoothAdv at multiple radii in CIFAR-10 and ImageNet. We demonstrate that CAF achieves improved certified accuracies when compared to methods based on random or denoised smoothing, and that CAF is insensitive to certifying adapter hyperparameters. Finally, we show that an ensemble of adapters enables a single pre-trained feature extractor to defend against a range of noise perturbation scales.
Weakly Supervised Change Detection via Knowledge Distillation and Multiscale Sigmoid Inference
Mar 09, 2024Change detection, which aims to detect spatial changes from a pair of multi-temporal images due to natural or man-made causes, has been widely applied in remote sensing, disaster management, urban management, etc. Most existing change detection approaches, however, are fully supervised and require labor-intensive pixel-level labels. To address this, we develop a novel weakly supervised change detection technique via Knowledge Distillation and Multiscale Sigmoid Inference (KD-MSI) that leverages image-level labels. In our approach, the Class Activation Maps (CAM) are utilized not only to derive a change probability map but also to serve as a foundation for the knowledge distillation process. This is done through a joint training strategy of the teacher and student networks, enabling the student network to highlight potential change areas more accurately than teacher network based on image-level labels. Moreover, we designed a Multiscale Sigmoid Inference (MSI) module as a post processing step to further refine the change probability map from the trained student network. Empirical results on three public datasets, i.e., WHU-CD, DSIFN-CD, and LEVIR-CD, demonstrate that our proposed technique, with its integrated training strategy, significantly outperforms the state-of-the-art.
Distilling Adversarial Robustness Using Heterogeneous Teachers
Feb 23, 2024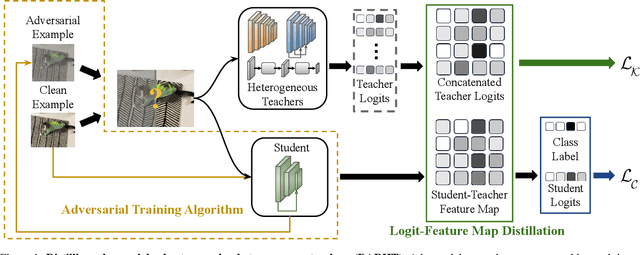
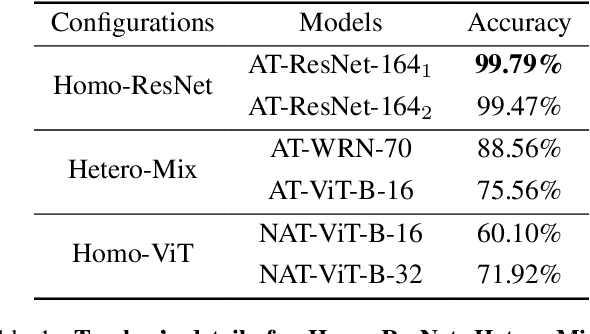
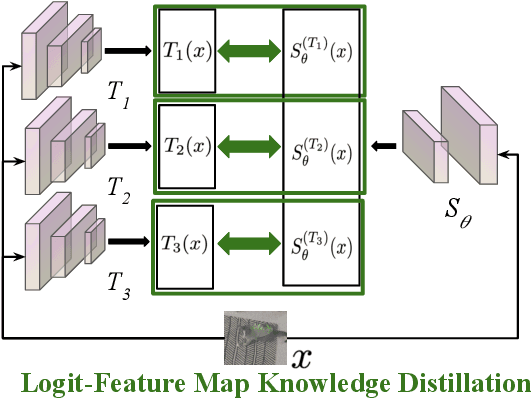
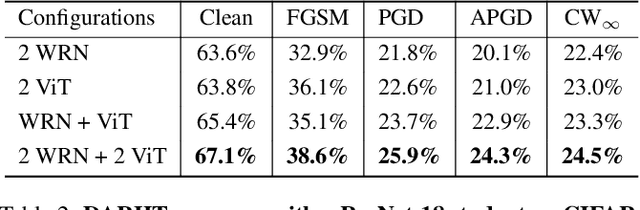
Achieving resiliency against adversarial attacks is necessary prior to deploying neural network classifiers in domains where misclassification incurs substantial costs, e.g., self-driving cars or medical imaging. Recent work has demonstrated that robustness can be transferred from an adversarially trained teacher to a student model using knowledge distillation. However, current methods perform distillation using a single adversarial and vanilla teacher and consider homogeneous architectures (i.e., residual networks) that are susceptible to misclassify examples from similar adversarial subspaces. In this work, we develop a defense framework against adversarial attacks by distilling adversarial robustness using heterogeneous teachers (DARHT). In DARHT, the student model explicitly represents teacher logits in a student-teacher feature map and leverages multiple teachers that exhibit low adversarial example transferability (i.e., exhibit high performance on dissimilar adversarial examples). Experiments on classification tasks in both white-box and black-box scenarios demonstrate that DARHT achieves state-of-the-art clean and robust accuracies when compared to competing adversarial training and distillation methods in the CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. Comparisons with homogeneous and heterogeneous teacher sets suggest that leveraging teachers with low adversarial example transferability increases student model robustness.
Heterogeneous Graph Sparsification for Efficient Representation Learning
Nov 14, 2022Graph sparsification is a powerful tool to approximate an arbitrary graph and has been used in machine learning over homogeneous graphs. In heterogeneous graphs such as knowledge graphs, however, sparsification has not been systematically exploited to improve efficiency of learning tasks. In this work, we initiate the study on heterogeneous graph sparsification and develop sampling-based algorithms for constructing sparsifiers that are provably sparse and preserve important information in the original graphs. We have performed extensive experiments to confirm that the proposed method can improve time and space complexities of representation learning while achieving comparable, or even better performance in subsequent graph learning tasks based on the learned embedding.
Auto-Encoding Goodness of Fit
Oct 12, 2022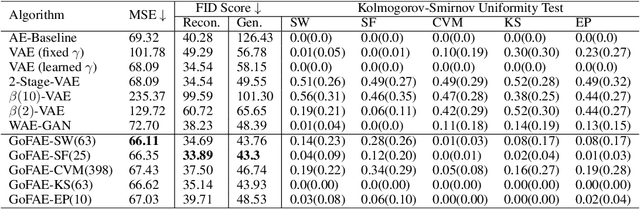
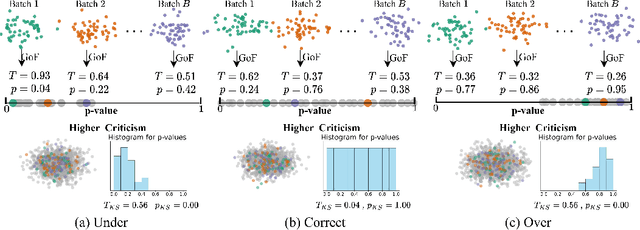
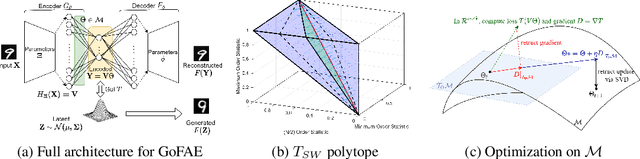
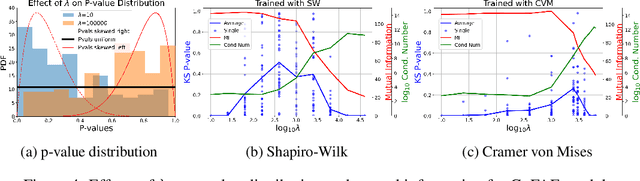
For generative autoencoders to learn a meaningful latent representation for data generation, a careful balance must be achieved between reconstruction error and how close the distribution in the latent space is to the prior. However, this balance is challenging to achieve due to a lack of criteria that work both at the mini-batch (local) and aggregated posterior (global) level. Goodness of fit (GoF) hypothesis tests provide a measure of statistical indistinguishability between the latent distribution and a target distribution class. In this work, we develop the Goodness of Fit Autoencoder (GoFAE), which incorporates hypothesis tests at two levels. At the mini-batch level, it uses GoF test statistics as regularization objectives. At a more global level, it selects a regularization coefficient based on higher criticism, i.e., a test on the uniformity of the local GoF p-values. We justify the use of GoF tests by providing a relaxed $L_2$-Wasserstein bound on the distance between the latent distribution and target prior. We propose to use GoF tests and prove that optimization based on these tests can be done with stochastic gradient (SGD) descent on a compact Riemannian manifold. Empirically, we show that our higher criticism parameter selection procedure balances reconstruction and generation using mutual information and uniformity of p-values respectively. Finally, we show that GoFAE achieves comparable FID scores and mean squared errors with competing deep generative models while retaining statistical indistinguishability from Gaussian in the latent space based on a variety of hypothesis tests.