 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Adversarial Robustness Using Heterogeneous Teachers
Feb 23, 2024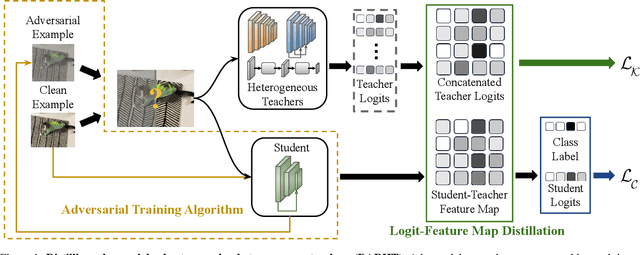
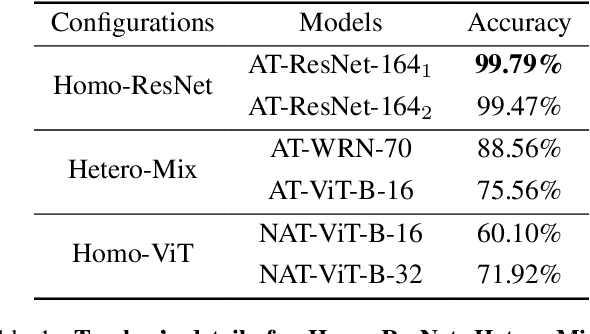
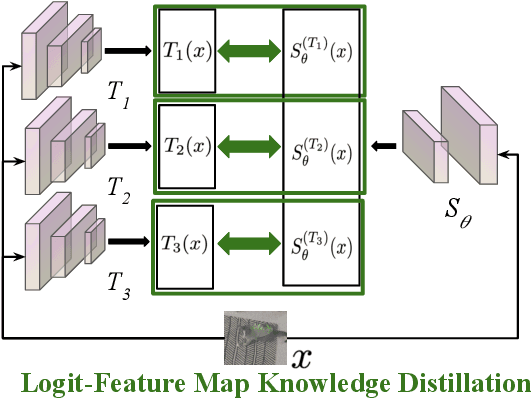
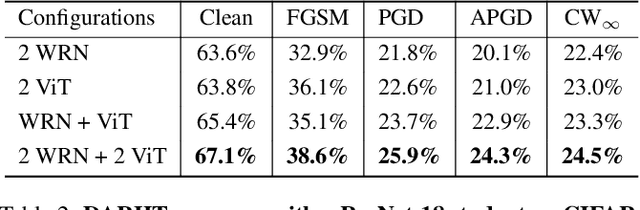
Achieving resiliency against adversarial attacks is necessary prior to deploying neural network classifiers in domains where misclassification incurs substantial costs, e.g., self-driving cars or medical imaging. Recent work has demonstrated that robustness can be transferred from an adversarially trained teacher to a student model using knowledge distillation. However, current methods perform distillation using a single adversarial and vanilla teacher and consider homogeneous architectures (i.e., residual networks) that are susceptible to misclassify examples from similar adversarial subspaces. In this work, we develop a defense framework against adversarial attacks by distilling adversarial robustness using heterogeneous teachers (DARHT). In DARHT, the student model explicitly represents teacher logits in a student-teacher feature map and leverages multiple teachers that exhibit low adversarial example transferability (i.e., exhibit high performance on dissimilar adversarial examples). Experiments on classification tasks in both white-box and black-box scenarios demonstrate that DARHT achieves state-of-the-art clean and robust accuracies when compared to competing adversarial training and distillation methods in the CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. Comparisons with homogeneous and heterogeneous teacher sets suggest that leveraging teachers with low adversarial example transferability increases student model robustness.
Back in Black: A Comparative Evaluation of Recent State-Of-The-Art Black-Box Attacks
Sep 29, 2021
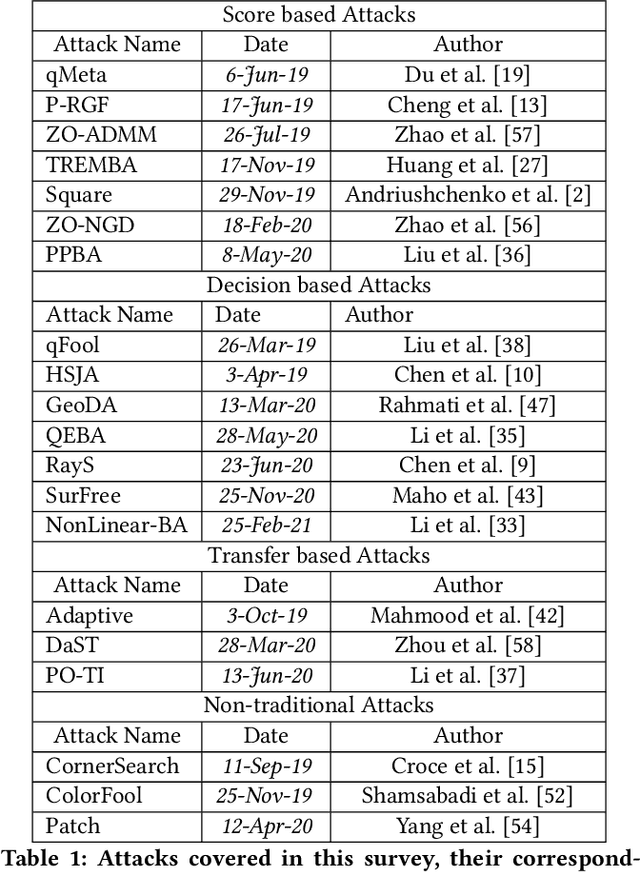
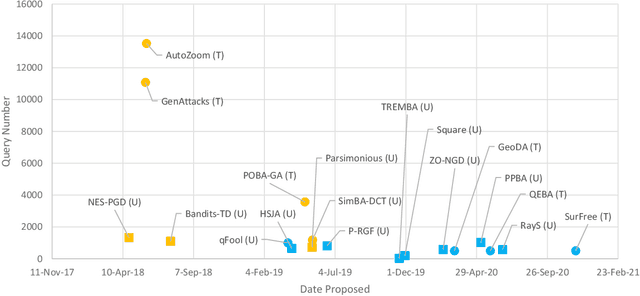

The field of adversarial machine learning has experienced a near exponential growth in the amount of papers being produced since 2018. This massive information output has yet to be properly processed and categorized. In this paper, we seek to help alleviate this problem by systematizing the recent advances in adversarial machine learning black-box attacks since 2019. Our survey summarizes and categorizes 20 recent black-box attacks. We also present a new analysis for understanding the attack success rate with respect to the adversarial model used in each paper. Overall, our paper surveys a wide body of literature to highlight recent attack developments and organizes them into four attack categories: score based attacks, decision based attacks, transfer attacks and non-traditional attacks. Further, we provide a new mathematical framework to show exactly how attack results can fairly be compared.
On the Robustness of Vision Transformers to Adversarial Examples
Mar 31, 2021

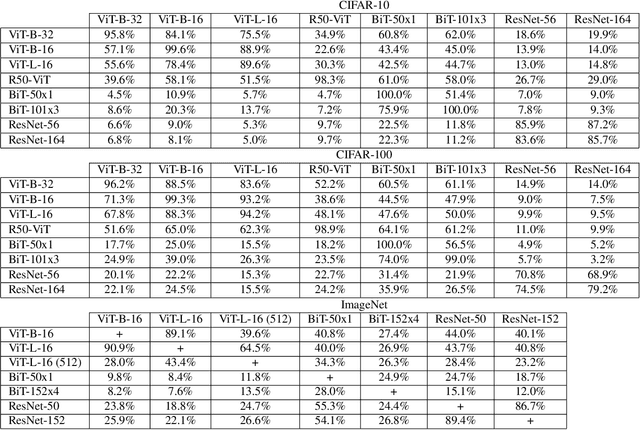

Recent advances in attention-based networks have shown that Vision Transformers can achieve state-of-the-art or near state-of-the-art results on many image classification tasks. This puts transformers in the unique position of being a promising alternative to traditional convolutional neural networks (CNNs). While CNNs have been carefully studied with respect to adversarial attacks, the same cannot be said of Vision Transformers. In this paper, we study the robustness of Vision Transformers to adversarial examples. Our analyses of transformer security is divided into three parts. First, we test the transformer under standard white-box and black-box attacks. Second, we study the transferability of adversarial examples between CNNs and transformers. We show that adversarial examples do not readily transfer between CNNs and transformers. Based on this finding, we analyze the security of a simple ensemble defense of CNNs and transformers. By creating a new attack, the self-attention blended gradient attack, we show that such an ensemble is not secure under a white-box adversary. However, under a black-box adversary, we show that an ensemble can achieve unprecedented robustness without sacrificing clean accuracy. Our analysis for this work is done using six types of white-box attacks and two types of black-box attacks. Our study encompasses multiple Vision Transformers, Big Transfer Models and CNN architectures trained on CIFAR-10, CIFAR-100 and ImageNet.