 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Evidentiary Limits of Membership Inference for Copyright Auditing
Jan 19, 2026As large language models (LLMs) are trained on increasingly opaque corpora, membership inference attacks (MIAs) have been proposed to audit whether copyrighted texts were used during training, despite growing concerns about their reliability under realistic conditions. We ask whether MIAs can serve as admissible evidence in adversarial copyright disputes where an accused model developer may obfuscate training data while preserving semantic content, and formalize this setting through a judge-prosecutor-accused communication protocol. To test robustness under this protocol, we introduce SAGE (Structure-Aware SAE-Guided Extraction), a paraphrasing framework guided by Sparse Autoencoders (SAEs) that rewrites training data to alter lexical structure while preserving semantic content and downstream utility. Our experiments show that state-of-the-art MIAs degrade when models are fine-tuned on SAGE-generated paraphrases, indicating that their signals are not robust to semantics-preserving transformations. While some leakage remains in certain fine-tuning regimes, these results suggest that MIAs are brittle in adversarial settings and insufficient, on their own, as a standalone mechanism for copyright auditing of LLMs.
Fundamental Limitations of Favorable Privacy-Utility Guarantees for DP-SGD
Jan 15, 2026Differentially Private Stochastic Gradient Descent (DP-SGD) is the dominant paradigm for private training, but its fundamental limitations under worst-case adversarial privacy definitions remain poorly understood. We analyze DP-SGD in the $f$-differential privacy framework, which characterizes privacy via hypothesis-testing trade-off curves, and study shuffled sampling over a single epoch with $M$ gradient updates. We derive an explicit suboptimal upper bound on the achievable trade-off curve. This result induces a geometric lower bound on the separation $κ$ which is the maximum distance between the mechanism's trade-off curve and the ideal random-guessing line. Because a large separation implies significant adversarial advantage, meaningful privacy requires small $κ$. However, we prove that enforcing a small separation imposes a strict lower bound on the Gaussian noise multiplier $σ$, which directly limits the achievable utility. In particular, under the standard worst-case adversarial model, shuffled DP-SGD must satisfy $σ\ge \frac{1}{\sqrt{2\ln M}}$ $\quad\text{or}\quad$ $κ\ge\ \frac{1}{\sqrt{8}}\!\left(1-\frac{1}{\sqrt{4π\ln M}}\right)$, and thus cannot simultaneously achieve strong privacy and high utility. Although this bound vanishes asymptotically as $M \to \infty$, the convergence is extremely slow: even for practically relevant numbers of updates the required noise magnitude remains substantial. We further show that the same limitation extends to Poisson subsampling up to constant factors. Our experiments confirm that the noise levels implied by this bound leads to significant accuracy degradation at realistic training settings, thus showing a critical bottleneck in DP-SGD under standard worst-case adversarial assumptions.
Beyond Anonymization: Object Scrubbing for Privacy-Preserving 2D and 3D Vision Tasks
Apr 23, 2025We introduce ROAR (Robust Object Removal and Re-annotation), a scalable framework for privacy-preserving dataset obfuscation that eliminates sensitive objects instead of modifying them. Our method integrates instance segmentation with generative inpainting to remove identifiable entities while preserving scene integrity. Extensive evaluations on 2D COCO-based object detection show that ROAR achieves 87.5% of the baseline detection average precision (AP), whereas image dropping achieves only 74.2% of the baseline AP, highlighting the advantage of scrubbing in preserving dataset utility. The degradation is even more severe for small objects due to occlusion and loss of fine-grained details. Furthermore, in NeRF-based 3D reconstruction, our method incurs a PSNR loss of at most 1.66 dB while maintaining SSIM and improving LPIPS, demonstrating superior perceptual quality. Our findings establish object removal as an effective privacy framework, achieving strong privacy guarantees with minimal performance trade-offs. The results highlight key challenges in generative inpainting, occlusion-robust segmentation, and task-specific scrubbing, setting the foundation for future advancements in privacy-preserving vision systems.
Quantifying and Mitigating Privacy Risks for Tabular Generative Models
Mar 12, 2024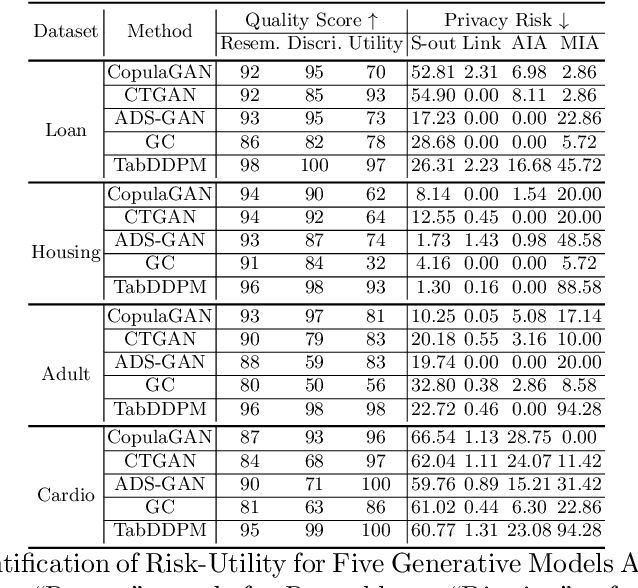
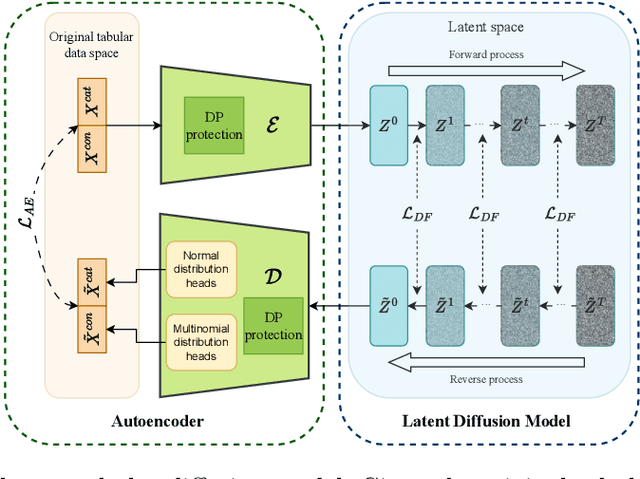
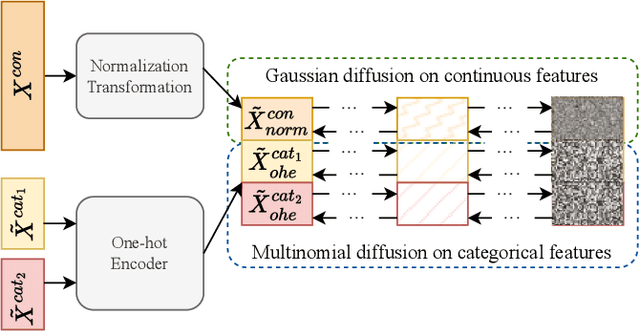
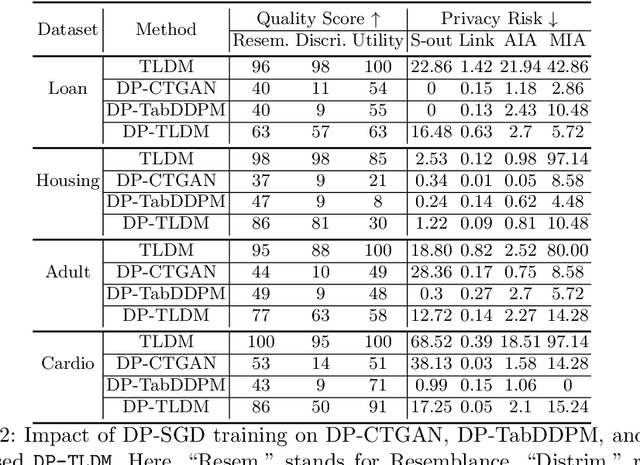
Synthetic data from generative models emerges as the privacy-preserving data-sharing solution. Such a synthetic data set shall resemble the original data without revealing identifiable private information. The backbone technology of tabular synthesizers is rooted in image generative models, ranging from Generative Adversarial Networks (GANs) to recent diffusion models. Recent prior work sheds light on the utility-privacy tradeoff on tabular data, revealing and quantifying privacy risks on synthetic data. We first conduct an exhaustive empirical analysis, highlighting the utility-privacy tradeoff of five state-of-the-art tabular synthesizers, against eight privacy attacks, with a special focus on membership inference attacks. Motivated by the observation of high data quality but also high privacy risk in tabular diffusion, we propose DP-TLDM, Differentially Private Tabular Latent Diffusion Model, which is composed of an autoencoder network to encode the tabular data and a latent diffusion model to synthesize the latent tables. Following the emerging f-DP framework, we apply DP-SGD to train the auto-encoder in combination with batch clipping and use the separation value as the privacy metric to better capture the privacy gain from DP algorithms. Our empirical evaluation demonstrates that DP-TLDM is capable of achieving a meaningful theoretical privacy guarantee while also significantly enhancing the utility of synthetic data. Specifically, compared to other DP-protected tabular generative models, DP-TLDM improves the synthetic quality by an average of 35% in data resemblance, 15% in the utility for downstream tasks, and 50% in data discriminability, all while preserving a comparable level of privacy risk.
Considerations on the Theory of Training Models with Differential Privacy
Mar 08, 2023In federated learning collaborative learning takes place by a set of clients who each want to remain in control of how their local training data is used, in particular, how can each client's local training data remain private? Differential privacy is one method to limit privacy leakage. We provide a general overview of its framework and provable properties, adopt the more recent hypothesis based definition called Gaussian DP or $f$-DP, and discuss Differentially Private Stochastic Gradient Descent (DP-SGD). We stay at a meta level and attempt intuitive explanations and insights \textit{in this book chapter}.
Gradient Descent-Type Methods: Background and Simple Unified Convergence Analysis
Dec 19, 2022In this book chapter, we briefly describe the main components that constitute the gradient descent method and its accelerated and stochastic variants. We aim at explaining these components from a mathematical point of view, including theoretical and practical aspects, but at an elementary level. We will focus on basic variants of the gradient descent method and then extend our view to recent variants, especially variance-reduced stochastic gradient schemes (SGD). Our approach relies on revealing the structures presented inside the problem and the assumptions imposed on the objective function. Our convergence analysis unifies several known results and relies on a general, but elementary recursive expression. We have illustrated this analysis on several common schemes.
Generalizing DP-SGD with Shuffling and Batching Clipping
Dec 12, 2022Classical differential private DP-SGD implements individual clipping with random subsampling, which forces a mini-batch SGD approach. We provide a general differential private algorithmic framework that goes beyond DP-SGD and allows any possible first order optimizers (e.g., classical SGD and momentum based SGD approaches) in combination with batch clipping, which clips an aggregate of computed gradients rather than summing clipped gradients (as is done in individual clipping). The framework also admits sampling techniques beyond random subsampling such as shuffling. Our DP analysis follows the $f$-DP approach and introduces a new proof technique which allows us to also analyse group privacy. In particular, for $E$ epochs work and groups of size $g$, we show a $\sqrt{g E}$ DP dependency for batch clipping with shuffling. This is much better than the previously anticipated linear dependency in $g$ and is much better than the previously expected square root dependency on the total number of rounds within $E$ epochs which is generally much more than $\sqrt{E}$.
Game Theoretic Mixed Experts for Combinational Adversarial Machine Learning
Nov 26, 2022Recent advances in adversarial machine learning have shown that defenses considered to be robust are actually susceptible to adversarial attacks which are specifically tailored to target their weaknesses. These defenses include Barrage of Random Transforms (BaRT), Friendly Adversarial Training (FAT), Trash is Treasure (TiT) and ensemble models made up of Vision Transformers (ViTs), Big Transfer models and Spiking Neural Networks (SNNs). A natural question arises: how can one best leverage a combination of adversarial defenses to thwart such attacks? In this paper, we provide a game-theoretic framework for ensemble adversarial attacks and defenses which answers this question. In addition to our framework we produce the first adversarial defense transferability study to further motivate a need for combinational defenses utilizing a diverse set of defense architectures. Our framework is called Game theoretic Mixed Experts (GaME) and is designed to find the Mixed-Nash strategy for a defender when facing an attacker employing compositional adversarial attacks. We show that this framework creates an ensemble of defenses with greater robustness than multiple state-of-the-art, single-model defenses in addition to combinational defenses with uniform probability distributions. Overall, our framework and analyses advance the field of adversarial machine learning by yielding new insights into compositional attack and defense formulations.
Finite-Sum Optimization: A New Perspective for Convergence to a Global Solution
Feb 07, 2022Deep neural networks (DNNs) have shown great success in many machine learning tasks. Their training is challenging since the loss surface of the network architecture is generally non-convex, or even non-smooth. How and under what assumptions is guaranteed convergence to a \textit{global} minimum possible? We propose a reformulation of the minimization problem allowing for a new recursive algorithmic framework. By using bounded style assumptions, we prove convergence to an $\varepsilon$-(global) minimum using $\mathcal{\tilde{O}}(1/\varepsilon^3)$ gradient computations. Our theoretical foundation motivates further study, implementation, and optimization of the new algorithmic framework and further investigation of its non-standard bounded style assumptions. This new direction broadens our understanding of why and under what circumstances training of a DNN converges to a global minimum.
Back in Black: A Comparative Evaluation of Recent State-Of-The-Art Black-Box Attacks
Sep 29, 2021
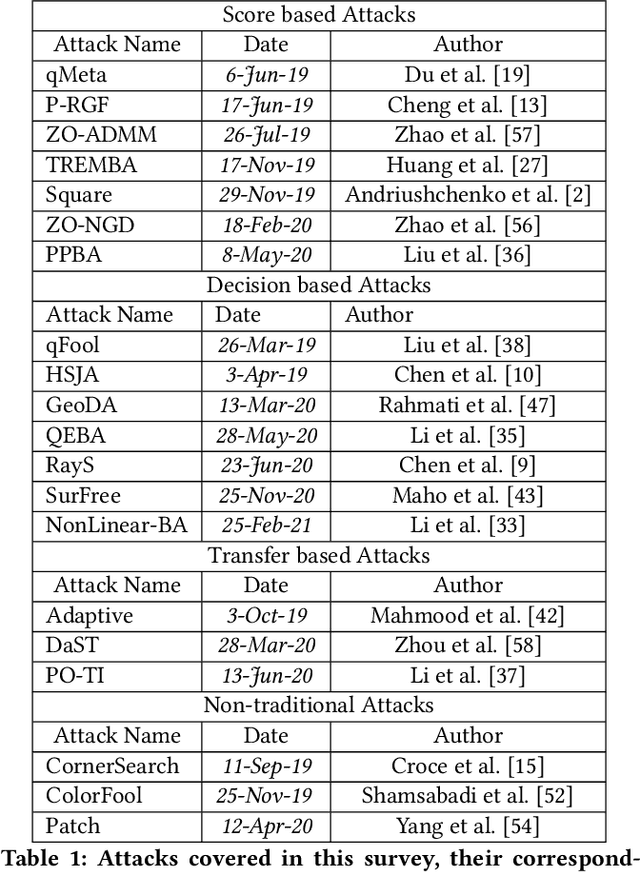
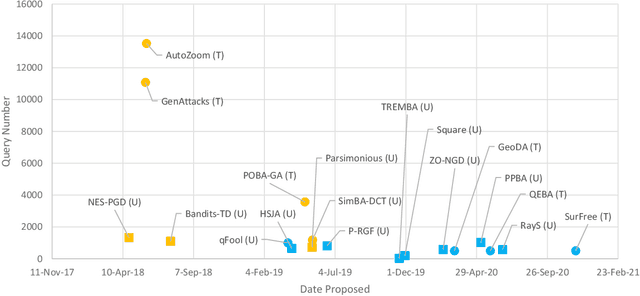

The field of adversarial machine learning has experienced a near exponential growth in the amount of papers being produced since 2018. This massive information output has yet to be properly processed and categorized. In this paper, we seek to help alleviate this problem by systematizing the recent advances in adversarial machine learning black-box attacks since 2019. Our survey summarizes and categorizes 20 recent black-box attacks. We also present a new analysis for understanding the attack success rate with respect to the adversarial model used in each paper. Overall, our paper surveys a wide body of literature to highlight recent attack developments and organizes them into four attack categories: score based attacks, decision based attacks, transfer attacks and non-traditional attacks. Further, we provide a new mathematical framework to show exactly how attack results can fairly be compared.