 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiloFuse: Cross-silo Synthetic Data Generation with Latent Tabular Diffusion Models
Apr 04, 2024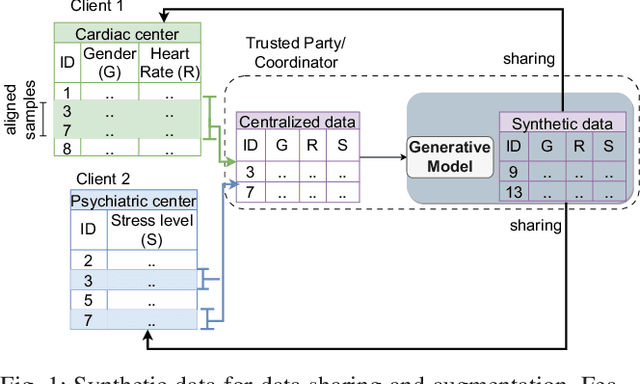
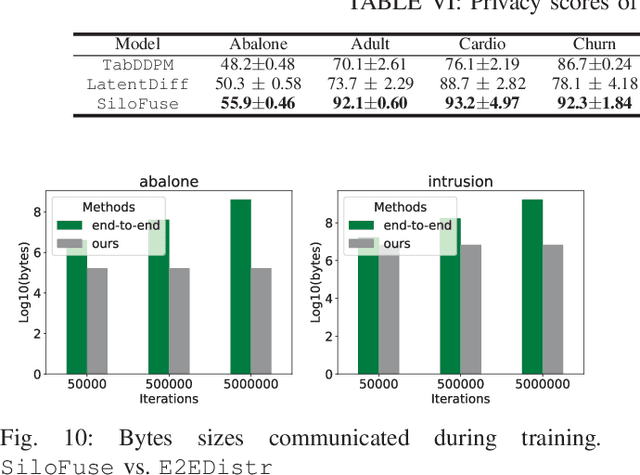
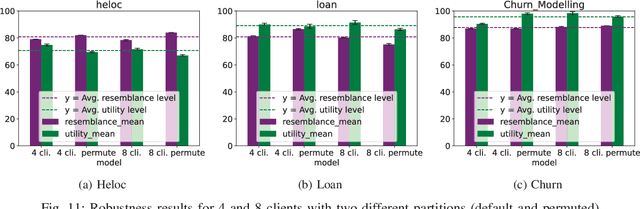
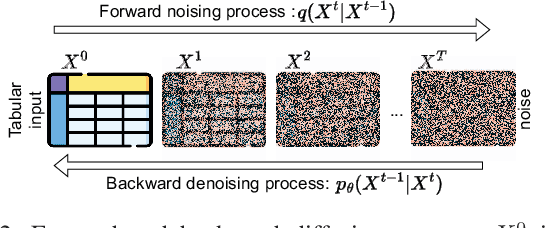
Synthetic tabular data is crucial for sharing and augmenting data across silos, especially for enterprises with proprietary data. However, existing synthesizers are designed for centrally stored data. Hence, they struggle with real-world scenarios where features are distributed across multiple silos, necessitating on-premise data storage. We introduce SiloFuse, a novel generative framework for high-quality synthesis from cross-silo tabular data. To ensure privacy, SiloFuse utilizes a distributed latent tabular diffusion architecture. Through autoencoders, latent representations are learned for each client's features, masking their actual values. We employ stacked distributed training to improve communication efficiency, reducing the number of rounds to a single step. Under SiloFuse, we prove the impossibility of data reconstruction for vertically partitioned synthesis and quantify privacy risks through three attacks using our benchmark framework. Experimental results on nine datasets showcase SiloFuse's competence against centralized diffusion-based synthesizers. Notably, SiloFuse achieves 43.8 and 29.8 higher percentage points over GANs in resemblance and utility. Experiments on communication show stacked training's fixed cost compared to the growing costs of end-to-end training as the number of training iterations increases. Additionally, SiloFuse proves robust to feature permutations and varying numbers of clients.
Quantifying and Mitigating Privacy Risks for Tabular Generative Models
Mar 12, 2024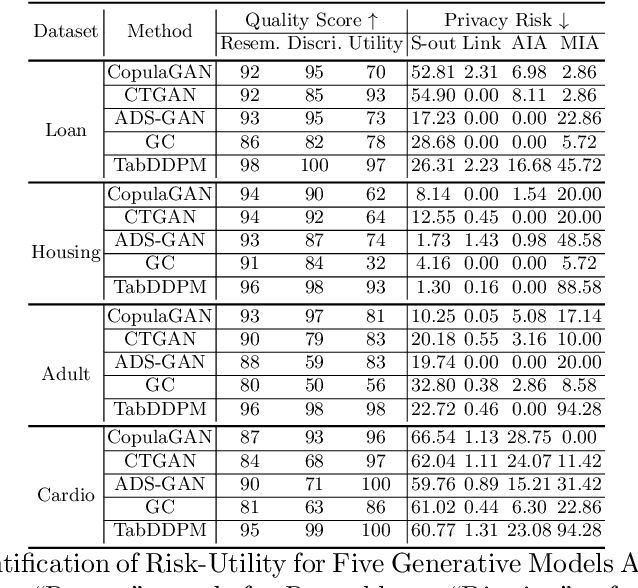
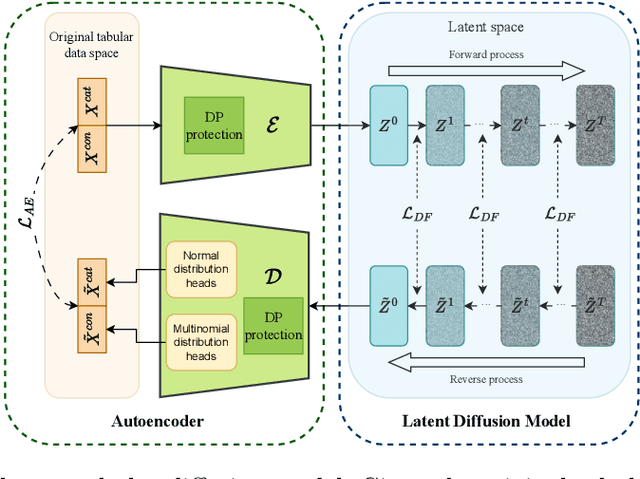
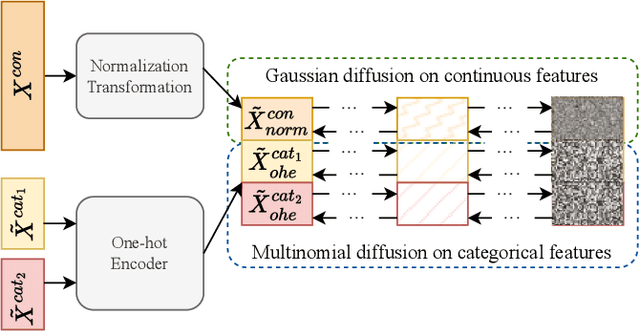
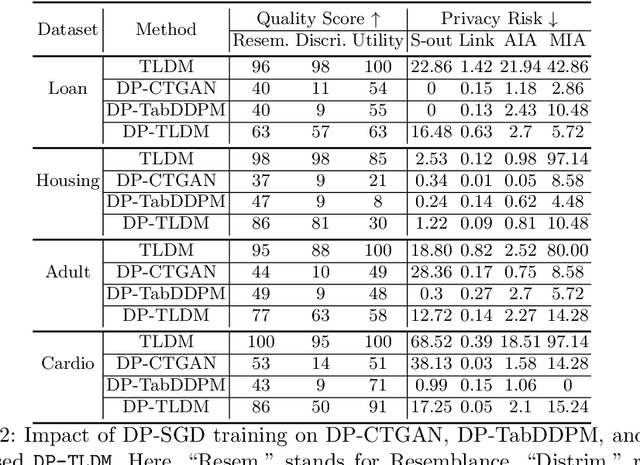
Synthetic data from generative models emerges as the privacy-preserving data-sharing solution. Such a synthetic data set shall resemble the original data without revealing identifiable private information. The backbone technology of tabular synthesizers is rooted in image generative models, ranging from Generative Adversarial Networks (GANs) to recent diffusion models. Recent prior work sheds light on the utility-privacy tradeoff on tabular data, revealing and quantifying privacy risks on synthetic data. We first conduct an exhaustive empirical analysis, highlighting the utility-privacy tradeoff of five state-of-the-art tabular synthesizers, against eight privacy attacks, with a special focus on membership inference attacks. Motivated by the observation of high data quality but also high privacy risk in tabular diffusion, we propose DP-TLDM, Differentially Private Tabular Latent Diffusion Model, which is composed of an autoencoder network to encode the tabular data and a latent diffusion model to synthesize the latent tables. Following the emerging f-DP framework, we apply DP-SGD to train the auto-encoder in combination with batch clipping and use the separation value as the privacy metric to better capture the privacy gain from DP algorithms. Our empirical evaluation demonstrates that DP-TLDM is capable of achieving a meaningful theoretical privacy guarantee while also significantly enhancing the utility of synthetic data. Specifically, compared to other DP-protected tabular generative models, DP-TLDM improves the synthetic quality by an average of 35% in data resemblance, 15% in the utility for downstream tasks, and 50% in data discriminability, all while preserving a comparable level of privacy risk.