 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeWak: Temporal Chained-Hashing Watermark for Time Series Data
Jun 06, 2025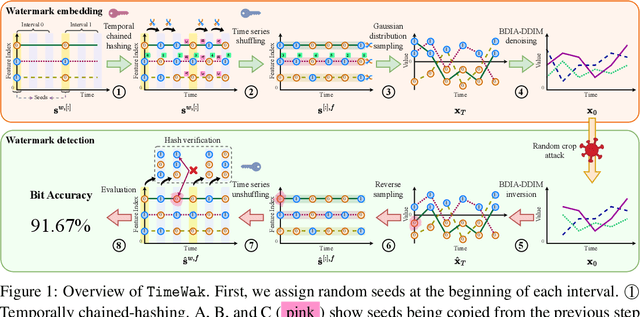
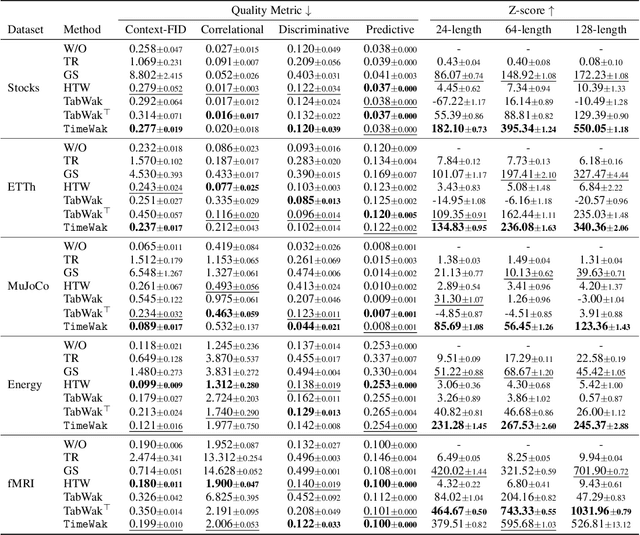
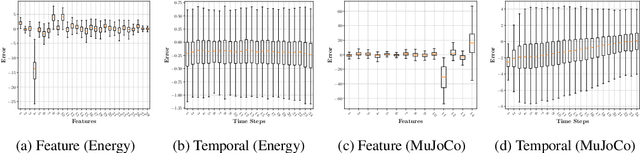
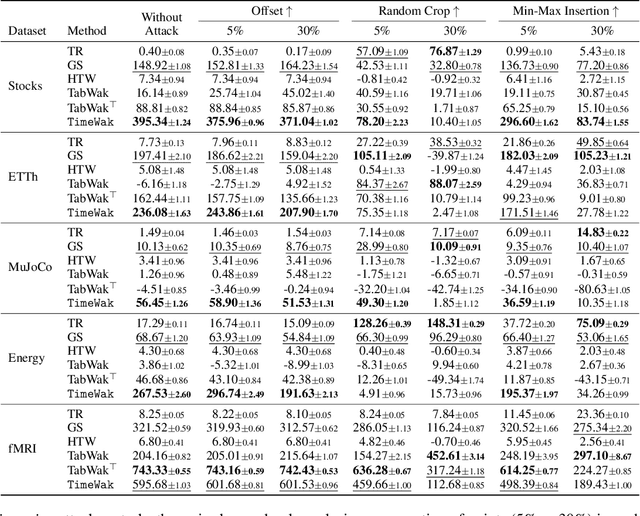
Synthetic time series generated by diffusion models enable sharing privacy-sensitive datasets, such as patients' functional MRI records. Key criteria for synthetic data include high data utility and traceability to verify the data source. Recent watermarking methods embed in homogeneous latent spaces, but state-of-the-art time series generators operate in real space, making latent-based watermarking incompatible. This creates the challenge of watermarking directly in real space while handling feature heterogeneity and temporal dependencies. We propose TimeWak, the first watermarking algorithm for multivariate time series diffusion models. To handle temporal dependence and spatial heterogeneity, TimeWak embeds a temporal chained-hashing watermark directly within the real temporal-feature space. The other unique feature is the $\epsilon$-exact inversion, which addresses the non-uniform reconstruction error distribution across features from inverting the diffusion process to detect watermarks. We derive the error bound of inverting multivariate time series and further maintain high watermark detectability. We extensively evaluate TimeWak on its impact on synthetic data quality, watermark detectability, and robustness under various post-editing attacks, against 5 datasets and baselines of different temporal lengths. Our results show that TimeWak achieves improvements of 61.96% in context-FID score, and 8.44% in correlational scores against the state-of-the-art baseline, while remaining consistently detectable.
WaveStitch: Flexible and Fast Conditional Time Series Generation with Diffusion Models
Mar 08, 2025



Generating temporal data under constraints is critical for forecasting, imputation, and synthesis. These datasets often include auxiliary conditions that influence the values within the time series signal. Existing methods face three key challenges: (1) they fail to adapt to conditions at inference time; (2) they rely on sequential generation, which slows the generation speed; and (3) they inefficiently encode categorical features, leading to increased sparsity and input sizes. We propose WaveStitch, a novel method that addresses these challenges by leveraging denoising diffusion probabilistic models to efficiently generate accurate temporal data under given auxiliary constraints. WaveStitch overcomes these limitations by: (1) modeling interactions between constraints and signals to generalize to new, unseen conditions; (2) enabling the parallel synthesis of sequential segments with a novel "stitching" mechanism to enforce coherence across segments; and (3) encoding categorical features as compact periodic signals while preserving temporal patterns. Extensive evaluations across diverse datasets highlight WaveStitch's ability to generalize to unseen conditions during inference, achieving up to a 10x lower mean-squared-error compared to the state-of-the-art methods. Moreover, WaveStitch generates data up to 460x faster than autoregressive methods while maintaining comparable accuracy. By efficiently encoding categorical features, WaveStitch provides a robust and efficient solution for temporal data generation. Our code is open-sourced: https://github.com/adis98/HierarchicalTS
Federated Time Series Generation on Feature and Temporally Misaligned Data
Oct 28, 2024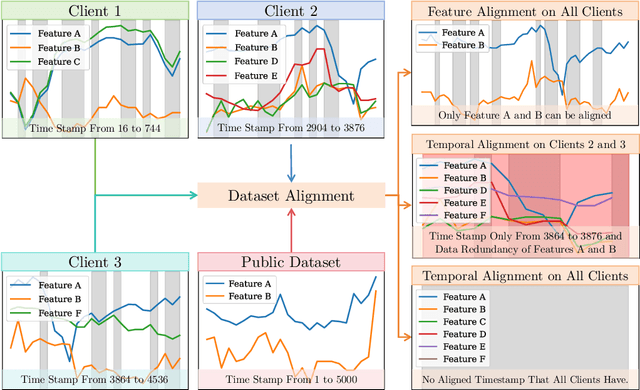

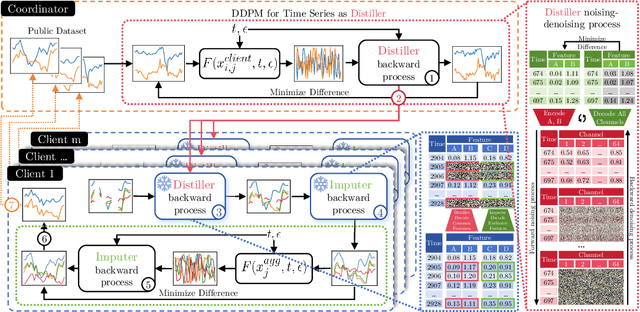
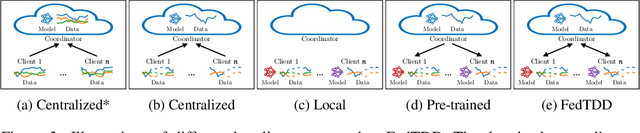
Distributed time series data presents a challenge for federated learning, as clients often possess different feature sets and have misaligned time steps. Existing federated time series models are limited by the assumption of perfect temporal or feature alignment across clients. In this paper, we propose FedTDD, a novel federated time series diffusion model that jointly learns a synthesizer across clients. At the core of FedTDD is a novel data distillation and aggregation framework that reconciles the differences between clients by imputing the misaligned timesteps and features. In contrast to traditional federated learning, FedTDD learns the correlation across clients' time series through the exchange of local synthetic outputs instead of model parameters. A coordinator iteratively improves a global distiller network by leveraging shared knowledge from clients through the exchange of synthetic data. As the distiller becomes more refined over time, it subsequently enhances the quality of the clients' local feature estimates, allowing each client to then improve its local imputations for missing data using the latest, more accurate distiller. Experimental results on five datasets demonstrate FedTDD's effectiveness compared to centralized training, and the effectiveness of sharing synthetic outputs to transfer knowledge of local time series. Notably, FedTDD achieves 79.4% and 62.8% improvement over local training in Context-FID and Correlational scores.
Parameterizing Federated Continual Learning for Reproducible Research
Jun 04, 2024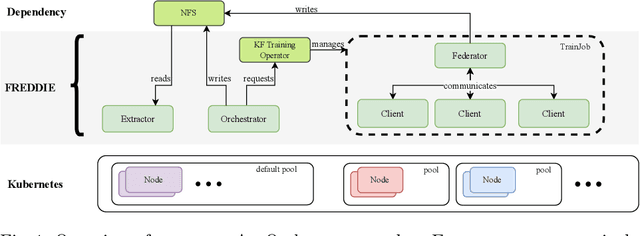

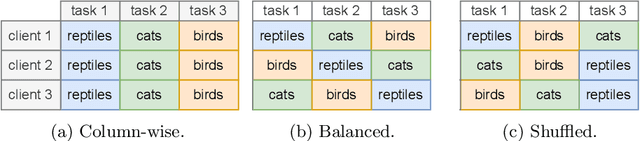
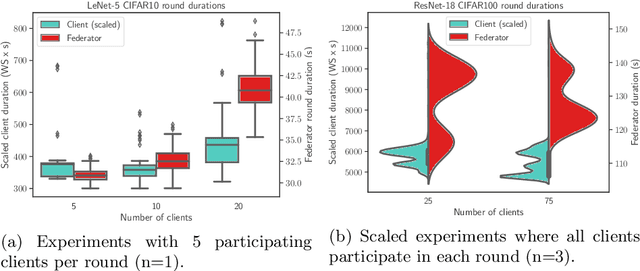
Federated Learning (FL) systems evolve in heterogeneous and ever-evolving environments that challenge their performance. Under real deployments, the learning tasks of clients can also evolve with time, which calls for the integration of methodologies such as Continual Learning. To enable research reproducibility, we propose a set of experimental best practices that precisely capture and emulate complex learning scenarios. Our framework, Freddie, is the first entirely configurable framework for Federated Continual Learning (FCL), and it can be seamlessly deployed on a large number of machines thanks to the use of Kubernetes and containerization. We demonstrate the effectiveness of Freddie on two use cases, (i) large-scale FL on CIFAR100 and (ii) heterogeneous task sequence on FCL, which highlight unaddressed performance challenges in FCL scenarios.
Share Your Secrets for Privacy! Confidential Forecasting with Vertical Federated Learning
May 31, 2024Vertical federated learning (VFL) is a promising area for time series forecasting in industrial applications, such as predictive maintenance and machine control. Critical challenges to address in manufacturing include data privacy and over-fitting on small and noisy datasets during both training and inference. Additionally, to increase industry adaptability, such forecasting models must scale well with the number of parties while ensuring strong convergence and low-tuning complexity. We address those challenges and propose 'Secret-shared Time Series Forecasting with VFL' (STV), a novel framework that exhibits the following key features: i) a privacy-preserving algorithm for forecasting with SARIMAX and autoregressive trees on vertically partitioned data; ii) serverless forecasting using secret sharing and multi-party computation; iii) novel N-party algorithms for matrix multiplication and inverse operations for direct parameter optimization, giving strong convergence with minimal hyperparameter tuning complexity. We conduct evaluations on six representative datasets from public and industry-specific contexts. Our results demonstrate that STV's forecasting accuracy is comparable to those of centralized approaches. They also show that our direct optimization can outperform centralized methods, which include state-of-the-art diffusion models and long-short-term memory, by 23.81% on forecasting accuracy. We also conduct a scalability analysis by examining the communication costs of direct and iterative optimization to navigate the choice between the two. Code and appendix are available: https://github.com/adis98/STV
SiloFuse: Cross-silo Synthetic Data Generation with Latent Tabular Diffusion Models
Apr 04, 2024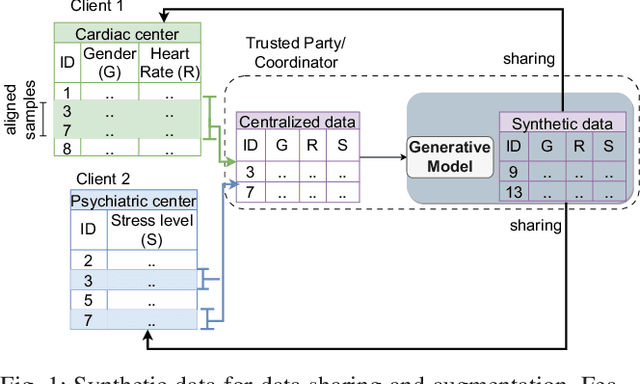
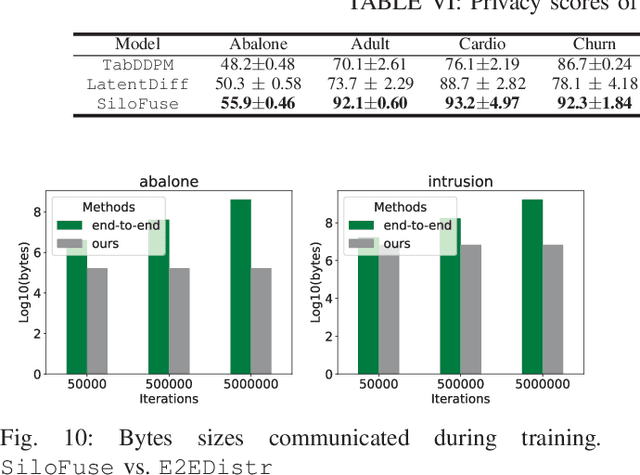
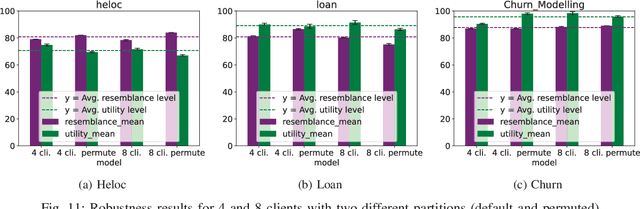
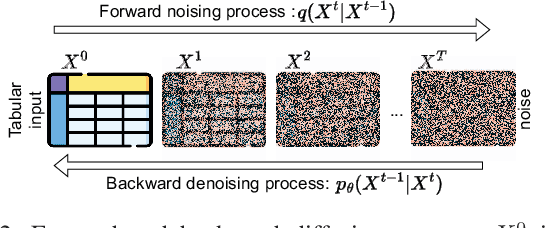
Synthetic tabular data is crucial for sharing and augmenting data across silos, especially for enterprises with proprietary data. However, existing synthesizers are designed for centrally stored data. Hence, they struggle with real-world scenarios where features are distributed across multiple silos, necessitating on-premise data storage. We introduce SiloFuse, a novel generative framework for high-quality synthesis from cross-silo tabular data. To ensure privacy, SiloFuse utilizes a distributed latent tabular diffusion architecture. Through autoencoders, latent representations are learned for each client's features, masking their actual values. We employ stacked distributed training to improve communication efficiency, reducing the number of rounds to a single step. Under SiloFuse, we prove the impossibility of data reconstruction for vertically partitioned synthesis and quantify privacy risks through three attacks using our benchmark framework. Experimental results on nine datasets showcase SiloFuse's competence against centralized diffusion-based synthesizers. Notably, SiloFuse achieves 43.8 and 29.8 higher percentage points over GANs in resemblance and utility. Experiments on communication show stacked training's fixed cost compared to the growing costs of end-to-end training as the number of training iterations increases. Additionally, SiloFuse proves robust to feature permutations and varying numbers of clients.