 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterizing Federated Continual Learning for Reproducible Research
Jun 04, 2024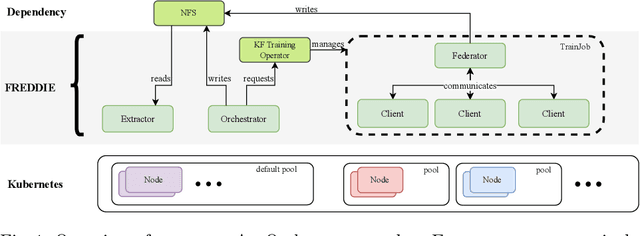

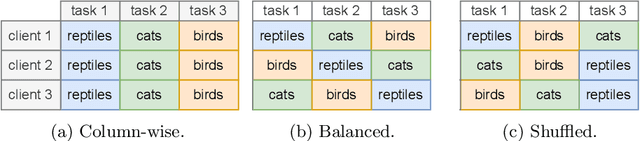
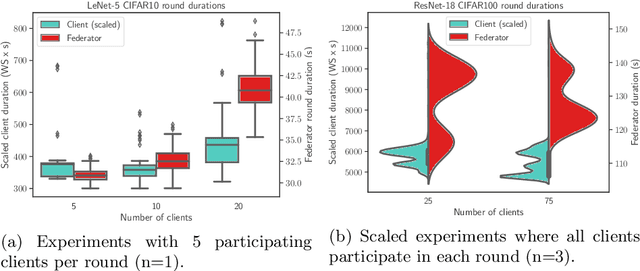
Federated Learning (FL) systems evolve in heterogeneous and ever-evolving environments that challenge their performance. Under real deployments, the learning tasks of clients can also evolve with time, which calls for the integration of methodologies such as Continual Learning. To enable research reproducibility, we propose a set of experimental best practices that precisely capture and emulate complex learning scenarios. Our framework, Freddie, is the first entirely configurable framework for Federated Continual Learning (FCL), and it can be seamlessly deployed on a large number of machines thanks to the use of Kubernetes and containerization. We demonstrate the effectiveness of Freddie on two use cases, (i) large-scale FL on CIFAR100 and (ii) heterogeneous task sequence on FCL, which highlight unaddressed performance challenges in FCL scenarios.
Duwak: Dual Watermarks in Large Language Models
Mar 12, 2024As large language models (LLM) are increasingly used for text generation tasks, it is critical to audit their usages, govern their applications, and mitigate their potential harms. Existing watermark techniques are shown effective in embedding single human-imperceptible and machine-detectable patterns without significantly affecting generated text quality and semantics. However, the efficiency in detecting watermarks, i.e., the minimum number of tokens required to assert detection with significance and robustness against post-editing, is still debatable. In this paper, we propose, Duwak, to fundamentally enhance the efficiency and quality of watermarking by embedding dual secret patterns in both token probability distribution and sampling schemes. To mitigate expression degradation caused by biasing toward certain tokens, we design a contrastive search to watermark the sampling scheme, which minimizes the token repetition and enhances the diversity. We theoretically explain the interdependency of the two watermarks within Duwak. We evaluate Duwak extensively on Llama2 under various post-editing attacks, against four state-of-the-art watermarking techniques and combinations of them. Our results show that Duwak marked text achieves the highest watermarked text quality at the lowest required token count for detection, up to 70% tokens less than existing approaches, especially under post paraphrasing.