 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Topology Optimization for Non-IID Data in Decentralized Learning
Feb 03, 2026Decentralized learning (DL) enables a set of nodes to train a model collaboratively without central coordination, offering benefits for privacy and scalability. However, DL struggles to train a high accuracy model when the data distribution is non-independent and identically distributed (non-IID) and when the communication topology is static. To address these issues, we propose Morph, a topology optimization algorithm for DL. In Morph, nodes adaptively choose peers for model exchange based on maximum model dissimilarity. Morph maintains a fixed in-degree while dynamically reshaping the communication graph through gossip-based peer discovery and diversity-driven neighbor selection, thereby improving robustness to data heterogeneity. Experiments on CIFAR-10 and FEMNIST with up to 100 nodes show that Morph consistently outperforms static and epidemic baselines, while closely tracking the fully connected upper bound. On CIFAR-10, Morph achieves a relative improvement of 1.12x in test accuracy compared to the state-of-the-art baselines. On FEMNIST, Morph achieves an accuracy that is 1.08x higher than Epidemic Learning. Similar trends hold for 50 node deployments, where Morph narrows the gap to the fully connected upper bound within 0.5 percentage points on CIFAR-10. These results demonstrate that Morph achieves higher final accuracy, faster convergence, and more stable learning as quantified by lower inter-node variance, while requiring fewer communication rounds than baselines and no global knowledge.
Training Diffusion Models with Federated Learning
Jun 18, 2024


The training of diffusion-based models for image generation is predominantly controlled by a select few Big Tech companies, raising concerns about privacy, copyright, and data authority due to their lack of transparency regarding training data. To ad-dress this issue, we propose a federated diffusion model scheme that enables the independent and collaborative training of diffusion models without exposing local data. Our approach adapts the Federated Averaging (FedAvg) algorithm to train a Denoising Diffusion Model (DDPM). Through a novel utilization of the underlying UNet backbone, we achieve a significant reduction of up to 74% in the number of parameters exchanged during training,compared to the naive FedAvg approach, whilst simultaneously maintaining image quality comparable to the centralized setting, as evaluated by the FID score.
Parameterizing Federated Continual Learning for Reproducible Research
Jun 04, 2024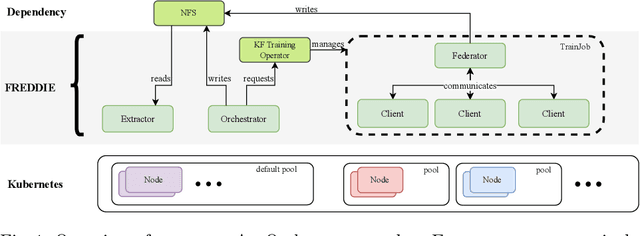

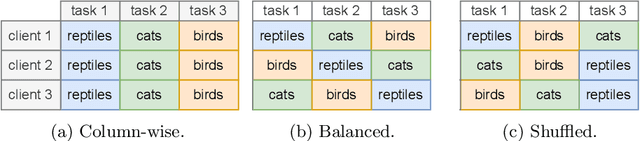
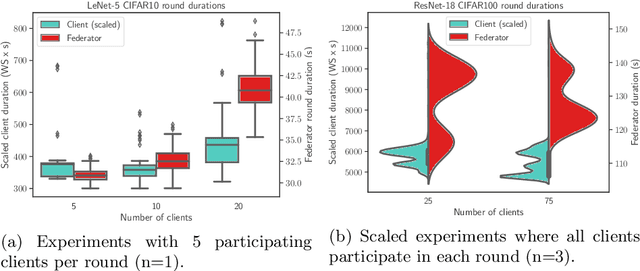
Federated Learning (FL) systems evolve in heterogeneous and ever-evolving environments that challenge their performance. Under real deployments, the learning tasks of clients can also evolve with time, which calls for the integration of methodologies such as Continual Learning. To enable research reproducibility, we propose a set of experimental best practices that precisely capture and emulate complex learning scenarios. Our framework, Freddie, is the first entirely configurable framework for Federated Continual Learning (FCL), and it can be seamlessly deployed on a large number of machines thanks to the use of Kubernetes and containerization. We demonstrate the effectiveness of Freddie on two use cases, (i) large-scale FL on CIFAR100 and (ii) heterogeneous task sequence on FCL, which highlight unaddressed performance challenges in FCL scenarios.
Asynchronous Multi-Server Federated Learning for Geo-Distributed Clients
Jun 03, 2024



Federated learning (FL) systems enable multiple clients to train a machine learning model iteratively through synchronously exchanging the intermediate model weights with a single server. The scalability of such FL systems can be limited by two factors: server idle time due to synchronous communication and the risk of a single server becoming the bottleneck. In this paper, we propose a new FL architecture, to our knowledge, the first multi-server FL system that is entirely asynchronous, and therefore addresses these two limitations simultaneously. Our solution keeps both servers and clients continuously active. As in previous multi-server methods, clients interact solely with their nearest server, ensuring efficient update integration into the model. Differently, however, servers also periodically update each other asynchronously, and never postpone interactions with clients. We compare our solution to three representative baselines - FedAvg, FedAsync and HierFAVG - on the MNIST and CIFAR-10 image classification datasets and on the WikiText-2 language modeling dataset. Our solution converges to similar or higher accuracy levels than previous baselines and requires 61% less time to do so in geo-distributed settings.
Asynchronous Byzantine Federated Learning
Jun 03, 2024Federated learning (FL) enables a set of geographically distributed clients to collectively train a model through a server. Classically, the training process is synchronous, but can be made asynchronous to maintain its speed in presence of slow clients and in heterogeneous networks. The vast majority of Byzantine fault-tolerant FL systems however rely on a synchronous training process. Our solution is one of the first Byzantine-resilient and asynchronous FL algorithms that does not require an auxiliary server dataset and is not delayed by stragglers, which are shortcomings of previous works. Intuitively, the server in our solution waits to receive a minimum number of updates from clients on its latest model to safely update it, and is later able to safely leverage the updates that late clients might send. We compare the performance of our solution with state-of-the-art algorithms on both image and text datasets under gradient inversion, perturbation, and backdoor attacks. Our results indicate that our solution trains a model faster than previous synchronous FL solution, and maintains a higher accuracy, up to 1.54x and up to 1.75x for perturbation and gradient inversion attacks respectively, in the presence of Byzantine clients than previous asynchronous FL solutions.
Aergia: Leveraging Heterogeneity in Federated Learning Systems
Oct 12, 2022
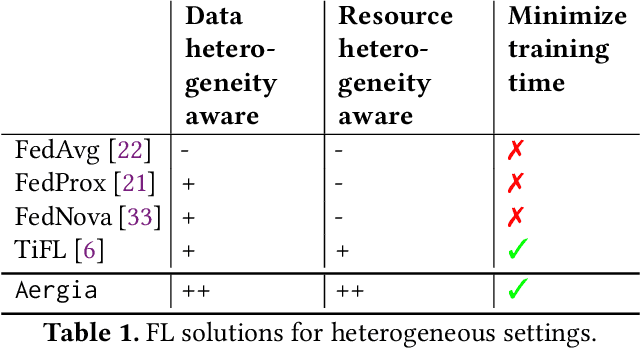
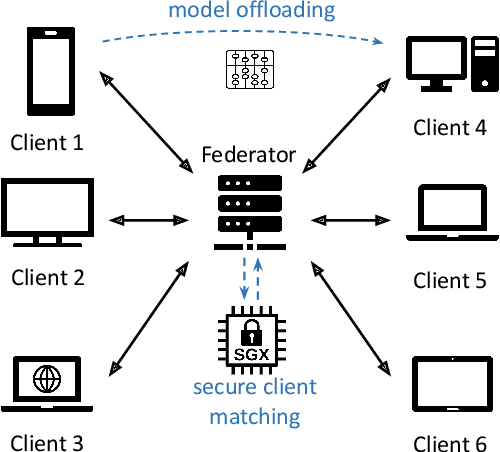
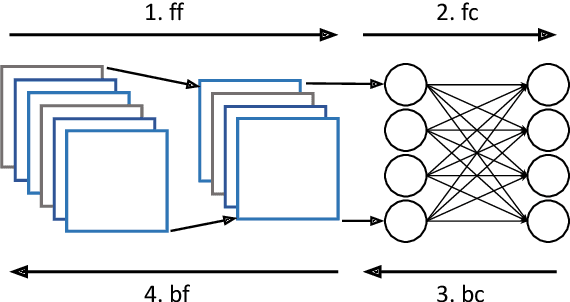
Federated Learning (FL) is a popular approach for distributed deep learning that prevents the pooling of large amounts of data in a central server. FL relies on clients to update a global model using their local datasets. Classical FL algorithms use a central federator that, for each training round, waits for all clients to send their model updates before aggregating them. In practical deployments, clients might have different computing powers and network capabilities, which might lead slow clients to become performance bottlenecks. Previous works have suggested to use a deadline for each learning round so that the federator ignores the late updates of slow clients, or so that clients send partially trained models before the deadline. To speed up the training process, we instead propose Aergia, a novel approach where slow clients (i) freeze the part of their model that is the most computationally intensive to train; (ii) train the unfrozen part of their model; and (iii) offload the training of the frozen part of their model to a faster client that trains it using its own dataset. The offloading decisions are orchestrated by the federator based on the training speed that clients report and on the similarities between their datasets, which are privately evaluated thanks to a trusted execution environment. We show through extensive experiments that Aergia maintains high accuracy and significantly reduces the training time under heterogeneous settings by up to 27% and 53% compared to FedAvg and TiFL, respectively.