 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAergia: Leveraging Heterogeneity in Federated Learning Systems
Paper and Code

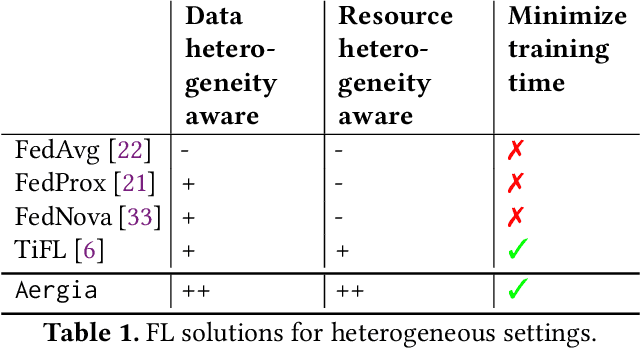
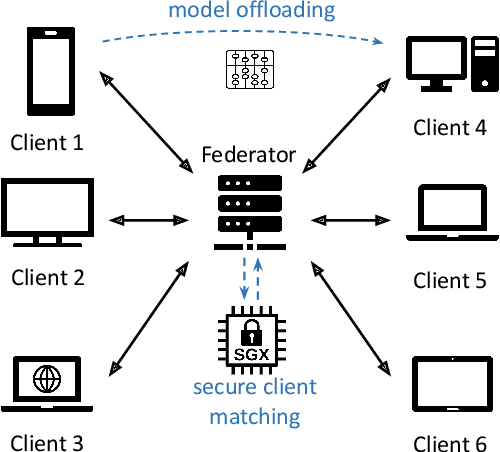
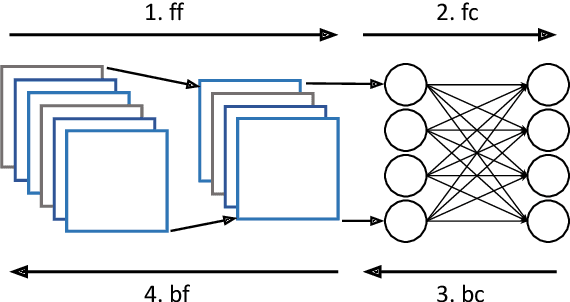
Federated Learning (FL) is a popular approach for distributed deep learning that prevents the pooling of large amounts of data in a central server. FL relies on clients to update a global model using their local datasets. Classical FL algorithms use a central federator that, for each training round, waits for all clients to send their model updates before aggregating them. In practical deployments, clients might have different computing powers and network capabilities, which might lead slow clients to become performance bottlenecks. Previous works have suggested to use a deadline for each learning round so that the federator ignores the late updates of slow clients, or so that clients send partially trained models before the deadline. To speed up the training process, we instead propose Aergia, a novel approach where slow clients (i) freeze the part of their model that is the most computationally intensive to train; (ii) train the unfrozen part of their model; and (iii) offload the training of the frozen part of their model to a faster client that trains it using its own dataset. The offloading decisions are orchestrated by the federator based on the training speed that clients report and on the similarities between their datasets, which are privately evaluated thanks to a trusted execution environment. We show through extensive experiments that Aergia maintains high accuracy and significantly reduces the training time under heterogeneous settings by up to 27% and 53% compared to FedAvg and TiFL, respectively.