 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen is Your LLM Steerable?
Jun 10, 2026Activation steering offers a lightweight approach to control language models' behavior at inference time, but whether it succeeds or fails heavily depends on the prompt, concept, model, and steering configuration. Finding the regime and boundaries of successful steering typically requires expensive grid searches and post-hoc evaluation of full autoregressive rollouts. In this work, we investigate whether steerability can be predicted from the model's internal states at the beginning of the generation process, e.g., after generating the first few tokens, and how to leverage such a predictor to improve steering success rate. To this end, we first introduce ASTEER, a testbed including 1.4M steered generations, spanning 150 concepts with each steering success/failure labeled. Leveraging this testbed, we analyze the model's early decoding dynamics by extracting features that compare hidden states before and after steering across layers and initial decoding steps. These features help us understand how steering's effects propagate along layers and token positions, which provide key information for steerability prediction. We then train a Gradient Boosting Decision Trees (GBDT) classifier on these features to predict whether an intervention will under-steer, succeed, or over-steer without requiring full rollout. Our predictor achieves around 0.7 macro-F1 score on unseen concepts, demonstrating that early hidden states encode substantial, structured information about eventual steering efficacy. We further leverage this steerability predictor as guidance for steering strength searching, achieving near-optimal performance with a small fraction of decoding cost.
Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
May 13, 2026Large language models (LLMs) increasingly act as autonomous agents that must decide when to answer directly vs. when to invoke external tools. Prior work studying adaptive tool use has largely treated tool necessity as a model-agnostic property, annotated by human or LLM judge, and mostly cover cases where the answer is obvious (e.g., fetching the weather vs. paraphrasing text). However, tool necessity in the wild is more nuanced due to the divergence of capability boundaries across models: a problem solvable by a strong model on its own may still require tools for a weaker one. In this work, we introduce a model-adaptive definition of tool-necessity, grounded in each model's empirical performance. Following this definition, we compare the necessity against observed tool-call behavior across four models on arithmetic and factual QA dataset, and find substantial mismatches of 26.5-54.0% and 30.8-41.8%, respectively. To diagnose the failure, we decompose tool use into two stages: an internal cognition stage that reflects whether a model believes a tool is necessary, and an execution stage that determines whether the model actually makes a tool-call action. By probing the LLM hidden states, we find that both signals are often linearly decodable, yet their probe directions become nearly orthogonal in the late-layer, last-token regime that drives the next-token action. By tracing the trajectory of samples in the two-stage process, we further discover that the majority of mismatch is concentrated in the cognition-to-action transition, not in cognition itself. These results reveal a knowing-doing gap in LLM tool-use: improving tool-use reliability requires not only better recognition of when tools are needed, but also better translation of that recognition into action.
Schoenfeld's Anatomy of Mathematical Reasoning by Language Models
Dec 23, 2025
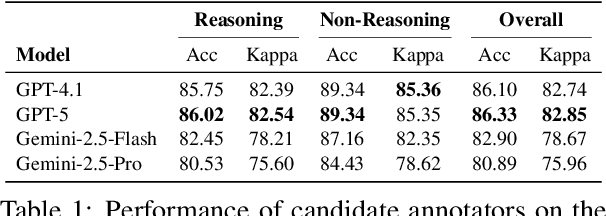

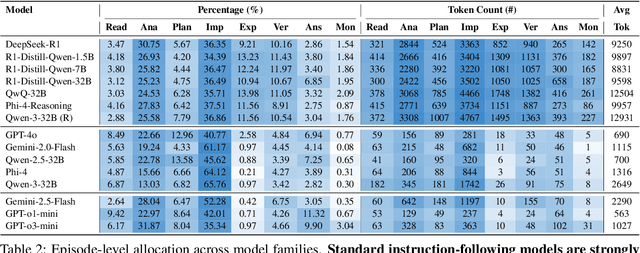
Large language models increasingly expose reasoning traces, yet their underlying cognitive structure and steps remain difficult to identify and analyze beyond surface-level statistics. We adopt Schoenfeld's Episode Theory as an inductive, intermediate-scale lens and introduce ThinkARM (Anatomy of Reasoning in Models), a scalable framework that explicitly abstracts reasoning traces into functional reasoning steps such as Analysis, Explore, Implement, Verify, etc. When applied to mathematical problem solving by diverse models, this abstraction reveals reproducible thinking dynamics and structural differences between reasoning and non-reasoning models, which are not apparent from token-level views. We further present two diagnostic case studies showing that exploration functions as a critical branching step associated with correctness, and that efficiency-oriented methods selectively suppress evaluative feedback steps rather than uniformly shortening responses. Together, our results demonstrate that episode-level representations make reasoning steps explicit, enabling systematic analysis of how reasoning is structured, stabilized, and altered in modern language models.
V-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions
Dec 12, 2025While many vision-language models (VLMs) are developed to answer well-defined, straightforward questions with highly specified targets, as in most benchmarks, they often struggle in practice with complex open-ended tasks, which usually require multiple rounds of exploration and reasoning in the visual space. Such visual thinking paths not only provide step-by-step exploration and verification as an AI detective but also produce better interpretations of the final answers. However, these paths are challenging to evaluate due to the large exploration space of intermediate steps. To bridge the gap, we develop an evaluation suite, ``Visual Reasoning with multi-step EXploration (V-REX)'', which is composed of a benchmark of challenging visual reasoning tasks requiring native multi-step exploration and an evaluation protocol. V-REX covers rich application scenarios across diverse domains. V-REX casts the multi-step exploratory reasoning into a Chain-of-Questions (CoQ) and disentangles VLMs' capability to (1) Planning: breaking down an open-ended task by selecting a chain of exploratory questions; and (2) Following: answering curated CoQ sequentially to collect information for deriving the final answer. By curating finite options of questions and answers per step, V-REX achieves a reliable quantitative and fine-grained analysis of the intermediate steps. By assessing SOTA proprietary and open-sourced VLMs, we reveal consistent scaling trends, significant differences between planning and following abilities, and substantial room for improvement in multi-step exploratory reasoning.
Understanding the Thinking Process of Reasoning Models: A Perspective from Schoenfeld's Episode Theory
Sep 18, 2025While Large Reasoning Models (LRMs) generate extensive chain-of-thought reasoning, we lack a principled framework for understanding how these thoughts are structured. In this paper, we introduce a novel approach by applying Schoenfeld's Episode Theory, a classic cognitive framework for human mathematical problem-solving, to analyze the reasoning traces of LRMs. We annotated thousands of sentences and paragraphs from model-generated solutions to math problems using seven cognitive labels (e.g., Plan, Implement, Verify). The result is the first publicly available benchmark for the fine-grained analysis of machine reasoning, including a large annotated corpus and detailed annotation guidebooks. Our preliminary analysis reveals distinct patterns in LRM reasoning, such as the transition dynamics between cognitive states. This framework provides a theoretically grounded methodology for interpreting LRM cognition and enables future work on more controllable and transparent reasoning systems.
Where to find Grokking in LLM Pretraining? Monitor Memorization-to-Generalization without Test
Jun 26, 2025Grokking, i.e., test performance keeps improving long after training loss converged, has been recently witnessed in neural network training, making the mechanism of generalization and other emerging capabilities such as reasoning mysterious. While prior studies usually train small models on a few toy or highly-specific tasks for thousands of epochs, we conduct the first study of grokking on checkpoints during one-pass pretraining of a 7B large language model (LLM), i.e., OLMoE. We compute the training loss and evaluate generalization on diverse benchmark tasks, including math reasoning, code generation, and commonsense/domain-specific knowledge retrieval tasks. Our study, for the first time, verifies that grokking still happens in the pretraining of large-scale foundation models, though different data may enter grokking stages asynchronously. We further demystify grokking's "emergence of generalization" by investigating LLM internal dynamics. Specifically, we find that training samples' pathways (i.e., expert choices across layers) evolve from random, instance-specific to more structured and shareable between samples during grokking. Also, the complexity of a sample's pathway reduces despite the converged loss. These indicate a memorization-to-generalization conversion, providing a mechanistic explanation of delayed generalization. In the study, we develop two novel metrics to quantify pathway distance and the complexity of a single pathway. We show their ability to predict the generalization improvement on diverse downstream tasks. They are efficient, simple to compute and solely dependent on training data. Hence, they have practical value for pretraining, enabling us to monitor the generalization performance without finetuning and test. Theoretically, we show that more structured pathways reduce model complexity and improve the generalization bound.
ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness
Apr 10, 2025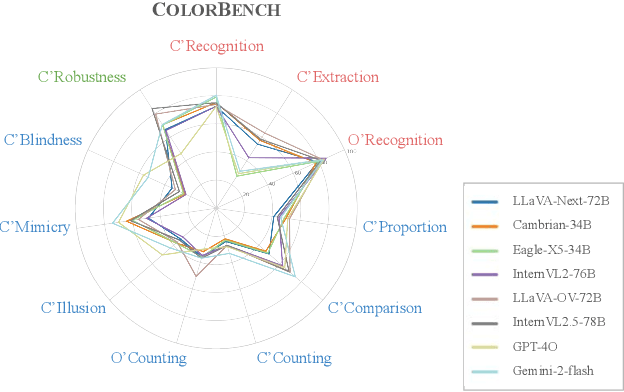
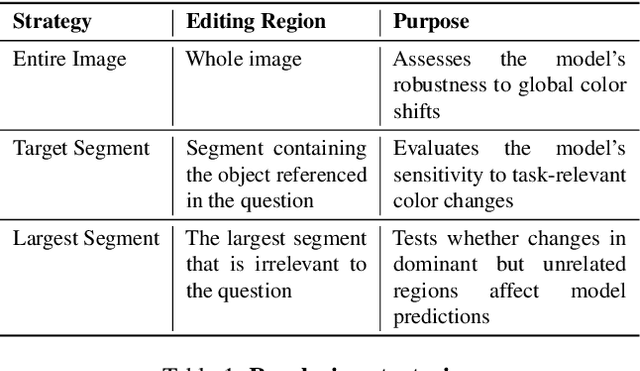
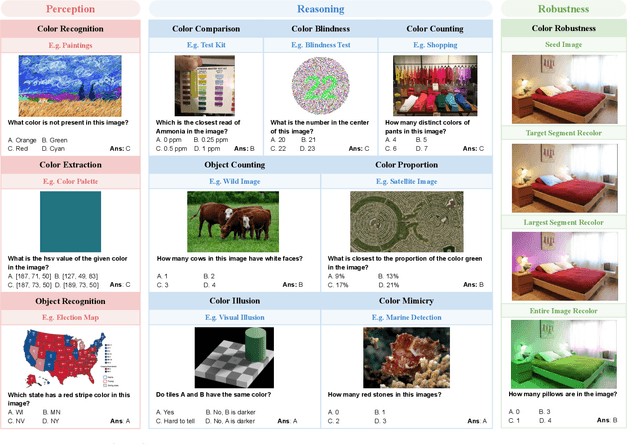
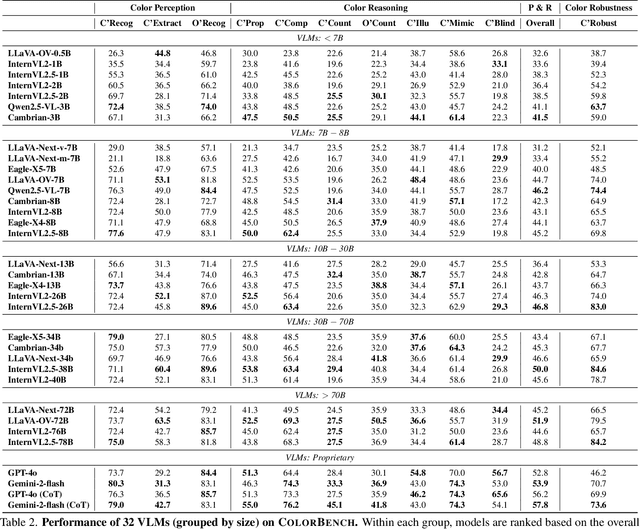
Color plays an important role in human perception and usually provides critical clues in visual reasoning. However, it is unclear whether and how vision-language models (VLMs) can perceive, understand, and leverage color as humans. This paper introduces ColorBench, an innovative benchmark meticulously crafted to assess the capabilities of VLMs in color understanding, including color perception, reasoning, and robustness. By curating a suite of diverse test scenarios, with grounding in real applications, ColorBench evaluates how these models perceive colors, infer meanings from color-based cues, and maintain consistent performance under varying color transformations. Through an extensive evaluation of 32 VLMs with varying language models and vision encoders, our paper reveals some undiscovered findings: (i) The scaling law (larger models are better) still holds on ColorBench, while the language model plays a more important role than the vision encoder. (ii) However, the performance gaps across models are relatively small, indicating that color understanding has been largely neglected by existing VLMs. (iii) CoT reasoning improves color understanding accuracies and robustness, though they are vision-centric tasks. (iv) Color clues are indeed leveraged by VLMs on ColorBench but they can also mislead models in some tasks. These findings highlight the critical limitations of current VLMs and underscore the need to enhance color comprehension. Our ColorBenchcan serve as a foundational tool for advancing the study of human-level color understanding of multimodal AI.
Missing Premise exacerbates Overthinking: Are Reasoning Models losing Critical Thinking Skill?
Apr 09, 2025We find that the response length of reasoning LLMs, whether trained by reinforcement learning or supervised learning, drastically increases for ill-posed questions with missing premises (MiP), ending up with redundant and ineffective thinking. This newly introduced scenario exacerbates the general overthinking issue to a large extent, which we name as the MiP-Overthinking. Such failures are against the ``test-time scaling law'' but have been widely observed on multiple datasets we curated with MiP, indicating the harm of cheap overthinking and a lack of critical thinking. Surprisingly, LLMs not specifically trained for reasoning exhibit much better performance on the MiP scenario, producing much shorter responses that quickly identify ill-posed queries. This implies a critical flaw of the current training recipe for reasoning LLMs, which does not encourage efficient thinking adequately, leading to the abuse of thinking patterns. To further investigate the reasons behind such failures, we conduct fine-grained analyses of the reasoning length, overthinking patterns, and location of critical thinking on different types of LLMs. Moreover, our extended ablation study reveals that the overthinking is contagious through the distillation of reasoning models' responses. These results improve the understanding of overthinking and shed novel insights into mitigating the problem.
Federated Time Series Generation on Feature and Temporally Misaligned Data
Oct 28, 2024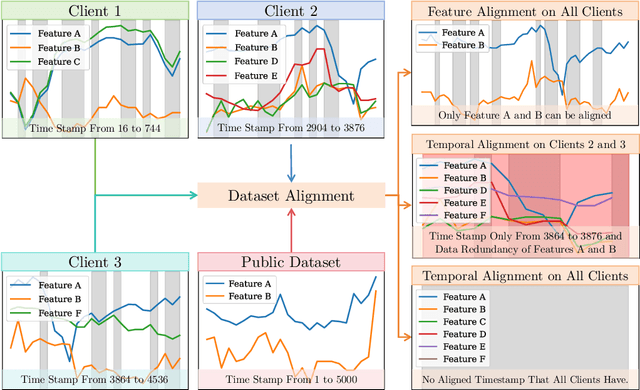

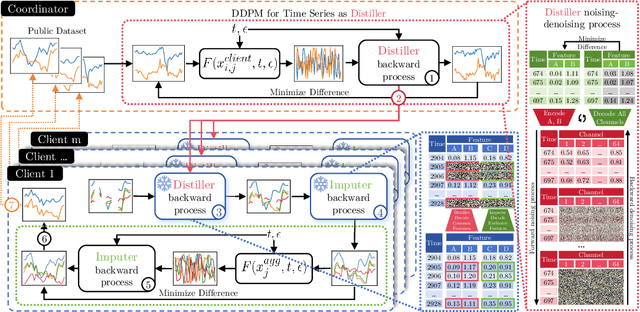
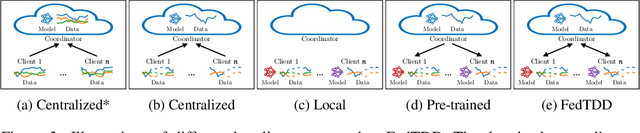
Distributed time series data presents a challenge for federated learning, as clients often possess different feature sets and have misaligned time steps. Existing federated time series models are limited by the assumption of perfect temporal or feature alignment across clients. In this paper, we propose FedTDD, a novel federated time series diffusion model that jointly learns a synthesizer across clients. At the core of FedTDD is a novel data distillation and aggregation framework that reconciles the differences between clients by imputing the misaligned timesteps and features. In contrast to traditional federated learning, FedTDD learns the correlation across clients' time series through the exchange of local synthetic outputs instead of model parameters. A coordinator iteratively improves a global distiller network by leveraging shared knowledge from clients through the exchange of synthetic data. As the distiller becomes more refined over time, it subsequently enhances the quality of the clients' local feature estimates, allowing each client to then improve its local imputations for missing data using the latest, more accurate distiller. Experimental results on five datasets demonstrate FedTDD's effectiveness compared to centralized training, and the effectiveness of sharing synthetic outputs to transfer knowledge of local time series. Notably, FedTDD achieves 79.4% and 62.8% improvement over local training in Context-FID and Correlational scores.
1+1>2: Can Large Language Models Serve as Cross-Lingual Knowledge Aggregators?
Jun 20, 2024
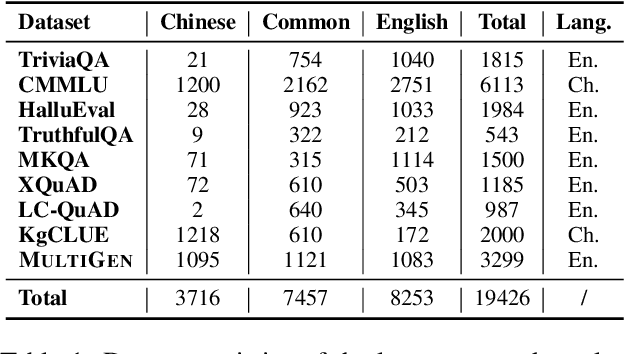

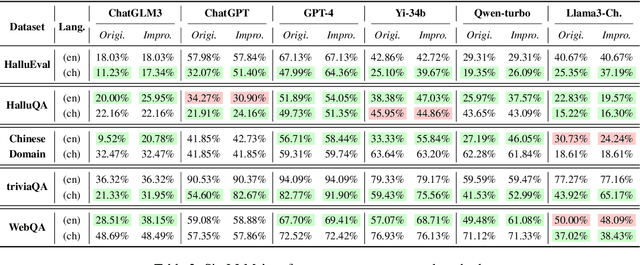
Large Language Models (LLMs) have garnered significant attention due to their remarkable ability to process information across various languages. Despite their capabilities, they exhibit inconsistencies in handling identical queries in different languages, presenting challenges for further advancement. This paper introduces a method to enhance the multilingual performance of LLMs by aggregating knowledge from diverse languages. This approach incorporates a low-resource knowledge detector specific to a language, a language selection process, and mechanisms for answer replacement and integration. Our experiments demonstrate notable performance improvements, particularly in reducing language performance disparity. An ablation study confirms that each component of our method significantly contributes to these enhancements. This research highlights the inherent potential of LLMs to harmonize multilingual capabilities and offers valuable insights for further exploration.