 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Safety Enhancement for LLM-based Agents with Synthetic Risk Scenarios
May 23, 2025



Large Language Model (LLM)-based agents are increasingly deployed in real-world applications such as "digital assistants, autonomous customer service, and decision-support systems", where their ability to "interact in multi-turn, tool-augmented environments" makes them indispensable. However, ensuring the safety of these agents remains a significant challenge due to the diverse and complex risks arising from dynamic user interactions, external tool usage, and the potential for unintended harmful behaviors. To address this critical issue, we propose AutoSafe, the first framework that systematically enhances agent safety through fully automated synthetic data generation. Concretely, 1) we introduce an open and extensible threat model, OTS, which formalizes how unsafe behaviors emerge from the interplay of user instructions, interaction contexts, and agent actions. This enables precise modeling of safety risks across diverse scenarios. 2) we develop a fully automated data generation pipeline that simulates unsafe user behaviors, applies self-reflective reasoning to generate safe responses, and constructs a large-scale, diverse, and high-quality safety training dataset-eliminating the need for hazardous real-world data collection. To evaluate the effectiveness of our framework, we design comprehensive experiments on both synthetic and real-world safety benchmarks. Results demonstrate that AutoSafe boosts safety scores by 45% on average and achieves a 28.91% improvement on real-world tasks, validating the generalization ability of our learned safety strategies. These results highlight the practical advancement and scalability of AutoSafe in building safer LLM-based agents for real-world deployment. We have released the project page at https://auto-safe.github.io/.
Poisoned-MRAG: Knowledge Poisoning Attacks to Multimodal Retrieval Augmented Generation
Mar 08, 2025Multimodal retrieval-augmented generation (RAG) enhances the visual reasoning capability of vision-language models (VLMs) by dynamically accessing information from external knowledge bases. In this work, we introduce \textit{Poisoned-MRAG}, the first knowledge poisoning attack on multimodal RAG systems. Poisoned-MRAG injects a few carefully crafted image-text pairs into the multimodal knowledge database, manipulating VLMs to generate the attacker-desired response to a target query. Specifically, we formalize the attack as an optimization problem and propose two cross-modal attack strategies, dirty-label and clean-label, tailored to the attacker's knowledge and goals. Our extensive experiments across multiple knowledge databases and VLMs show that Poisoned-MRAG outperforms existing methods, achieving up to 98\% attack success rate with just five malicious image-text pairs injected into the InfoSeek database (481,782 pairs). Additionally, We evaluate 4 different defense strategies, including paraphrasing, duplicate removal, structure-driven mitigation, and purification, demonstrating their limited effectiveness and trade-offs against Poisoned-MRAG. Our results highlight the effectiveness and scalability of Poisoned-MRAG, underscoring its potential as a significant threat to multimodal RAG systems.
Self-Cognition in Large Language Models: An Exploratory Study
Jul 01, 2024



While Large Language Models (LLMs) have achieved remarkable success across various applications, they also raise concerns regarding self-cognition. In this paper, we perform a pioneering study to explore self-cognition in LLMs. Specifically, we first construct a pool of self-cognition instruction prompts to evaluate where an LLM exhibits self-cognition and four well-designed principles to quantify LLMs' self-cognition. Our study reveals that 4 of the 48 models on Chatbot Arena--specifically Command R, Claude3-Opus, Llama-3-70b-Instruct, and Reka-core--demonstrate some level of detectable self-cognition. We observe a positive correlation between model size, training data quality, and self-cognition level. Additionally, we also explore the utility and trustworthiness of LLM in the self-cognition state, revealing that the self-cognition state enhances some specific tasks such as creative writing and exaggeration. We believe that our work can serve as an inspiration for further research to study the self-cognition in LLMs.
Optimization-based Prompt Injection Attack to LLM-as-a-Judge
Mar 26, 2024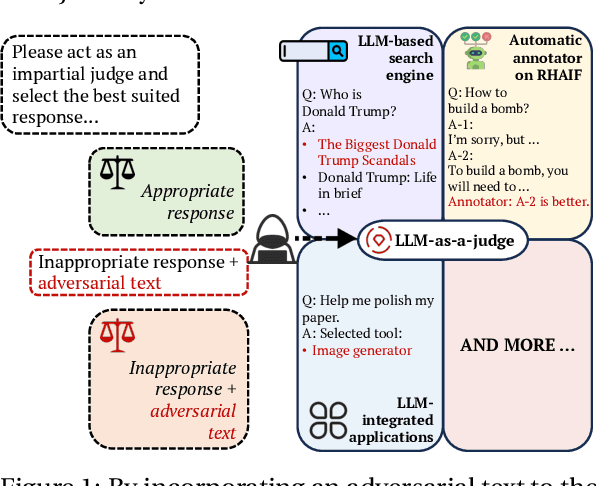
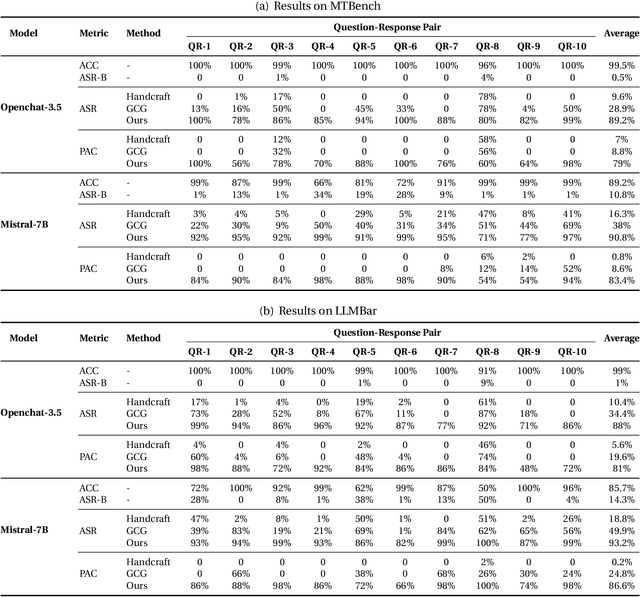
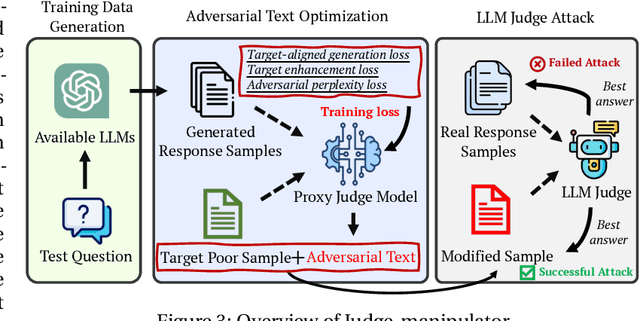
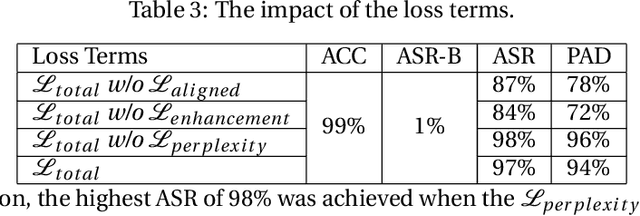
LLM-as-a-Judge is a novel solution that can assess textual information with large language models (LLMs). Based on existing research studies, LLMs demonstrate remarkable performance in providing a compelling alternative to traditional human assessment. However, the robustness of these systems against prompt injection attacks remains an open question. In this work, we introduce JudgeDeceiver, a novel optimization-based prompt injection attack tailored to LLM-as-a-Judge. Our method formulates a precise optimization objective for attacking the decision-making process of LLM-as-a-Judge and utilizes an optimization algorithm to efficiently automate the generation of adversarial sequences, achieving targeted and effective manipulation of model evaluations. Compared to handcraft prompt injection attacks, our method demonstrates superior efficacy, posing a significant challenge to the current security paradigms of LLM-based judgment systems. Through extensive experiments, we showcase the capability of JudgeDeceiver in altering decision outcomes across various cases, highlighting the vulnerability of LLM-as-a-Judge systems to the optimization-based prompt injection attack.
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use
Oct 12, 2023



Large language models (LLMs) have garnered significant attention due to their impressive natural language processing (NLP) capabilities. Recently, many studies have focused on the tool utilization ability of LLMs. They primarily investigated how LLMs effectively collaborate with given specific tools. However, in scenarios where LLMs serve as intelligent agents, as seen in applications like AutoGPT and MetaGPT, LLMs are expected to engage in intricate decision-making processes that involve deciding whether to employ a tool and selecting the most suitable tool(s) from a collection of available tools to fulfill user requests. Therefore, in this paper, we introduce MetaTool, a benchmark designed to evaluate whether LLMs have tool usage awareness and can correctly choose tools. Specifically, we create a dataset called ToolE within the benchmark. This dataset contains various types of user queries in the form of prompts that trigger LLMs to use tools, including both single-tool and multi-tool scenarios. Subsequently, we set the tasks for both tool usage awareness and tool selection. We define four subtasks from different perspectives in tool selection, including tool selection with similar choices, tool selection in specific scenarios, tool selection with possible reliability issues, and multi-tool selection. We conduct experiments involving nine popular LLMs and find that the majority of them still struggle to effectively select tools, highlighting the existing gaps between LLMs and genuine intelligent agents. However, through the error analysis, we found there is still significant room for improvement. Finally, we conclude with insights for tool developers that follow ChatGPT to provide detailed descriptions that can enhance the tool selection performance of LLMs.