 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSentinel: Detecting and Localizing Prompt Injection Attacks for Web Agents
Feb 03, 2026Prompt injection attacks manipulate webpage content to cause web agents to execute attacker-specified tasks instead of the user's intended ones. Existing methods for detecting and localizing such attacks achieve limited effectiveness, as their underlying assumptions often do not hold in the web-agent setting. In this work, we propose WebSentinel, a two-step approach for detecting and localizing prompt injection attacks in webpages. Given a webpage, Step I extracts \emph{segments of interest} that may be contaminated, and Step II evaluates each segment by checking its consistency with the webpage content as context. We show that WebSentinel is highly effective, substantially outperforming baseline methods across multiple datasets of both contaminated and clean webpages that we collected. Our code is available at: https://github.com/wxl-lxw/WebSentinel.
WAInjectBench: Benchmarking Prompt Injection Detections for Web Agents
Oct 01, 2025Multiple prompt injection attacks have been proposed against web agents. At the same time, various methods have been developed to detect general prompt injection attacks, but none have been systematically evaluated for web agents. In this work, we bridge this gap by presenting the first comprehensive benchmark study on detecting prompt injection attacks targeting web agents. We begin by introducing a fine-grained categorization of such attacks based on the threat model. We then construct datasets containing both malicious and benign samples: malicious text segments generated by different attacks, benign text segments from four categories, malicious images produced by attacks, and benign images from two categories. Next, we systematize both text-based and image-based detection methods. Finally, we evaluate their performance across multiple scenarios. Our key findings show that while some detectors can identify attacks that rely on explicit textual instructions or visible image perturbations with moderate to high accuracy, they largely fail against attacks that omit explicit instructions or employ imperceptible perturbations. Our datasets and code are released at: https://github.com/Norrrrrrr-lyn/WAInjectBench.
Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents
May 29, 2025Long-horizon robotic manipulation poses significant challenges for autonomous systems, requiring extended reasoning, precise execution, and robust error recovery across complex sequential tasks. Current approaches, whether based on static planning or end-to-end visuomotor policies, suffer from error accumulation and lack effective verification mechanisms during execution, limiting their reliability in real-world scenarios. We present Agentic Robot, a brain-inspired framework that addresses these limitations through Standardized Action Procedures (SAP)--a novel coordination protocol governing component interactions throughout manipulation tasks. Drawing inspiration from Standardized Operating Procedures (SOPs) in human organizations, SAP establishes structured workflows for planning, execution, and verification phases. Our architecture comprises three specialized components: (1) a large reasoning model that decomposes high-level instructions into semantically coherent subgoals, (2) a vision-language-action executor that generates continuous control commands from real-time visual inputs, and (3) a temporal verifier that enables autonomous progression and error recovery through introspective assessment. This SAP-driven closed-loop design supports dynamic self-verification without external supervision. On the LIBERO benchmark, Agentic Robot achieves state-of-the-art performance with an average success rate of 79.6\%, outperforming SpatialVLA by 6.1\% and OpenVLA by 7.4\% on long-horizon tasks. These results demonstrate that SAP-driven coordination between specialized components enhances both performance and interpretability in sequential manipulation, suggesting significant potential for reliable autonomous systems. Project Github: https://agentic-robot.github.io.
Poisoned-MRAG: Knowledge Poisoning Attacks to Multimodal Retrieval Augmented Generation
Mar 08, 2025Multimodal retrieval-augmented generation (RAG) enhances the visual reasoning capability of vision-language models (VLMs) by dynamically accessing information from external knowledge bases. In this work, we introduce \textit{Poisoned-MRAG}, the first knowledge poisoning attack on multimodal RAG systems. Poisoned-MRAG injects a few carefully crafted image-text pairs into the multimodal knowledge database, manipulating VLMs to generate the attacker-desired response to a target query. Specifically, we formalize the attack as an optimization problem and propose two cross-modal attack strategies, dirty-label and clean-label, tailored to the attacker's knowledge and goals. Our extensive experiments across multiple knowledge databases and VLMs show that Poisoned-MRAG outperforms existing methods, achieving up to 98\% attack success rate with just five malicious image-text pairs injected into the InfoSeek database (481,782 pairs). Additionally, We evaluate 4 different defense strategies, including paraphrasing, duplicate removal, structure-driven mitigation, and purification, demonstrating their limited effectiveness and trade-offs against Poisoned-MRAG. Our results highlight the effectiveness and scalability of Poisoned-MRAG, underscoring its potential as a significant threat to multimodal RAG systems.
Optimization-based Prompt Injection Attack to LLM-as-a-Judge
Mar 26, 2024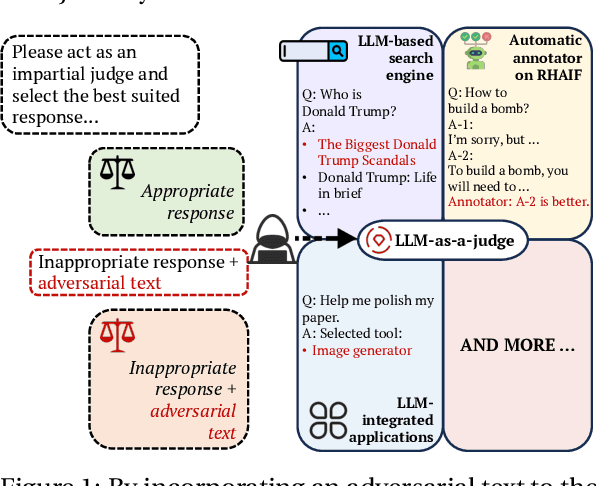
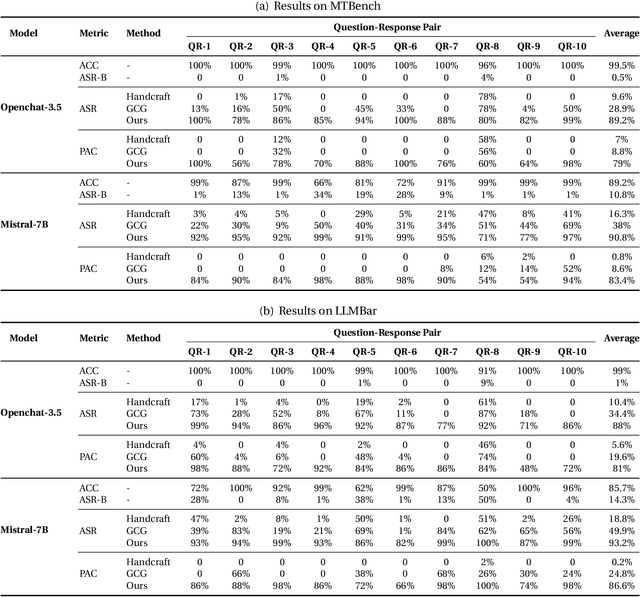
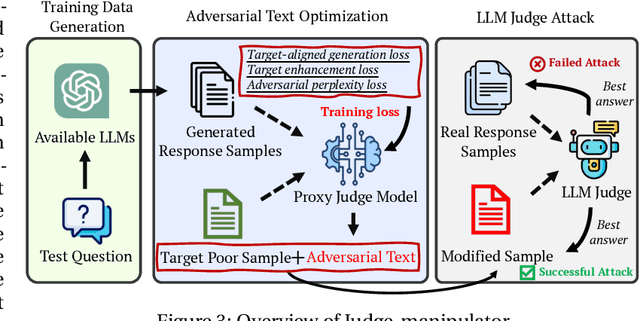
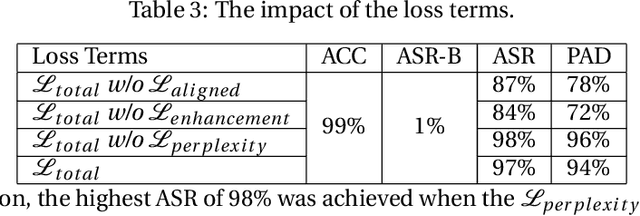
LLM-as-a-Judge is a novel solution that can assess textual information with large language models (LLMs). Based on existing research studies, LLMs demonstrate remarkable performance in providing a compelling alternative to traditional human assessment. However, the robustness of these systems against prompt injection attacks remains an open question. In this work, we introduce JudgeDeceiver, a novel optimization-based prompt injection attack tailored to LLM-as-a-Judge. Our method formulates a precise optimization objective for attacking the decision-making process of LLM-as-a-Judge and utilizes an optimization algorithm to efficiently automate the generation of adversarial sequences, achieving targeted and effective manipulation of model evaluations. Compared to handcraft prompt injection attacks, our method demonstrates superior efficacy, posing a significant challenge to the current security paradigms of LLM-based judgment systems. Through extensive experiments, we showcase the capability of JudgeDeceiver in altering decision outcomes across various cases, highlighting the vulnerability of LLM-as-a-Judge systems to the optimization-based prompt injection attack.
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Feb 07, 2024Multimodal Large Language Models (MLLMs) have gained significant attention recently, showing remarkable potential in artificial general intelligence. However, assessing the utility of MLLMs presents considerable challenges, primarily due to the absence multimodal benchmarks that align with human preferences. Inspired by LLM-as-a-Judge in LLMs, this paper introduces a novel benchmark, termed MLLM-as-a-Judge, to assess the ability of MLLMs in assisting judges including three distinct tasks: Scoring Evaluation, Pair Comparison, and Batch Ranking. Our study reveals that, while MLLMs demonstrate remarkable human-like discernment in Pair Comparisons, there is a significant divergence from human preferences in Scoring Evaluation and Batch Ranking tasks. Furthermore, MLLMs still face challenges in judgment, including diverse biases, hallucinatory responses, and inconsistencies, even for advanced models such as GPT-4V. These findings emphasize the pressing need for enhancements and further research efforts regarding MLLMs as fully reliable evaluators. Code and dataset are available at https://github.com/Dongping-Chen/MLLM-as-a-Judge.