 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vector Quantization with Distributional Matching: A Theoretical and Empirical Study
Jun 18, 2025The success of autoregressive models largely depends on the effectiveness of vector quantization, a technique that discretizes continuous features by mapping them to the nearest code vectors within a learnable codebook. Two critical issues in existing vector quantization methods are training instability and codebook collapse. Training instability arises from the gradient discrepancy introduced by the straight-through estimator, especially in the presence of significant quantization errors, while codebook collapse occurs when only a small subset of code vectors are utilized during training. A closer examination of these issues reveals that they are primarily driven by a mismatch between the distributions of the features and code vectors, leading to unrepresentative code vectors and significant data information loss during compression. To address this, we employ the Wasserstein distance to align these two distributions, achieving near 100\% codebook utilization and significantly reducing the quantization error. Both empirical and theoretical analyses validate the effectiveness of the proposed approach.
Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents
May 29, 2025Long-horizon robotic manipulation poses significant challenges for autonomous systems, requiring extended reasoning, precise execution, and robust error recovery across complex sequential tasks. Current approaches, whether based on static planning or end-to-end visuomotor policies, suffer from error accumulation and lack effective verification mechanisms during execution, limiting their reliability in real-world scenarios. We present Agentic Robot, a brain-inspired framework that addresses these limitations through Standardized Action Procedures (SAP)--a novel coordination protocol governing component interactions throughout manipulation tasks. Drawing inspiration from Standardized Operating Procedures (SOPs) in human organizations, SAP establishes structured workflows for planning, execution, and verification phases. Our architecture comprises three specialized components: (1) a large reasoning model that decomposes high-level instructions into semantically coherent subgoals, (2) a vision-language-action executor that generates continuous control commands from real-time visual inputs, and (3) a temporal verifier that enables autonomous progression and error recovery through introspective assessment. This SAP-driven closed-loop design supports dynamic self-verification without external supervision. On the LIBERO benchmark, Agentic Robot achieves state-of-the-art performance with an average success rate of 79.6\%, outperforming SpatialVLA by 6.1\% and OpenVLA by 7.4\% on long-horizon tasks. These results demonstrate that SAP-driven coordination between specialized components enhances both performance and interpretability in sequential manipulation, suggesting significant potential for reliable autonomous systems. Project Github: https://agentic-robot.github.io.
Aligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025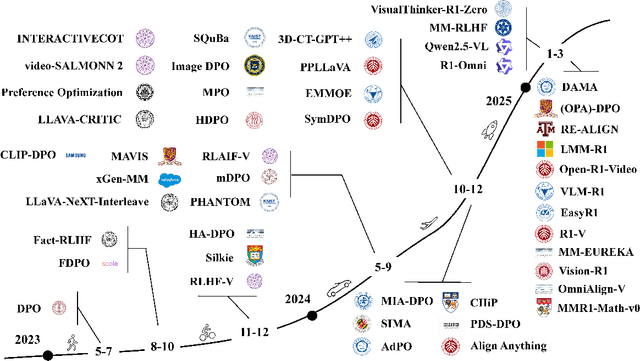
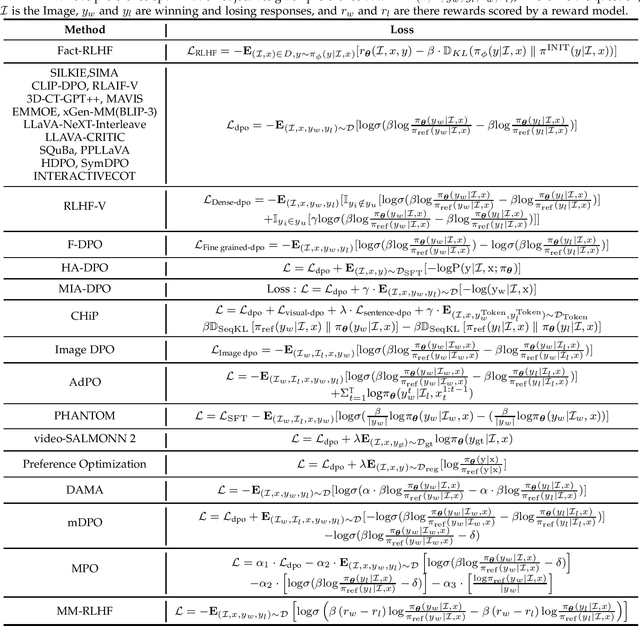
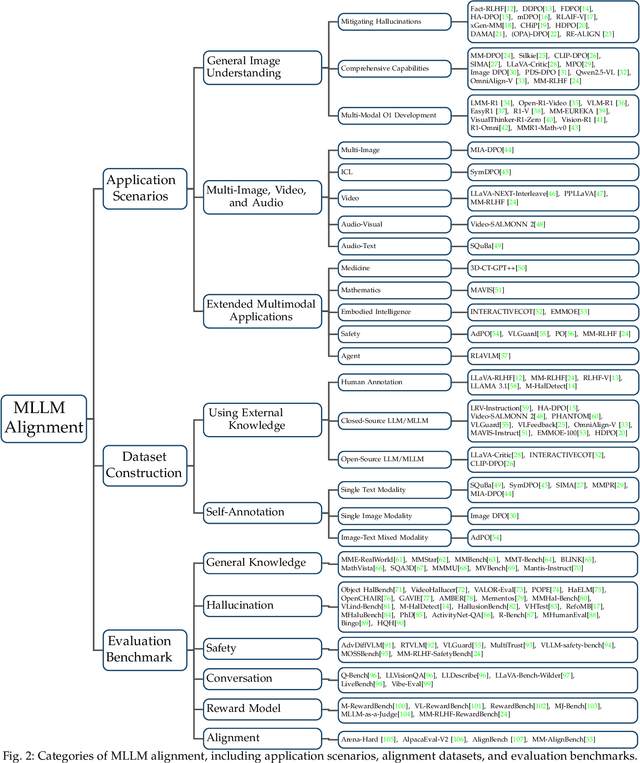
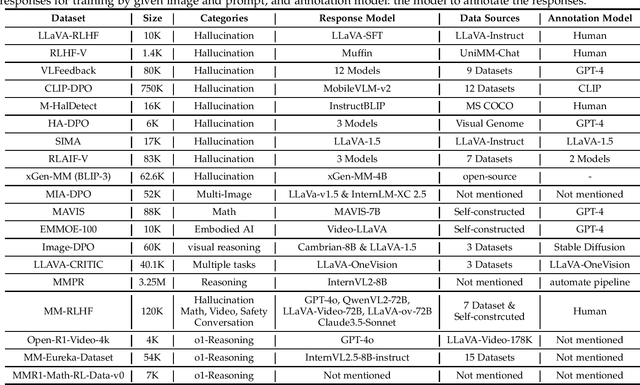
Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
A Survey on Post-training of Large Language Models
Mar 08, 2025The emergence of Large Language Models (LLMs) has fundamentally transformed natural language processing, making them indispensable across domains ranging from conversational systems to scientific exploration. However, their pre-trained architectures often reveal limitations in specialized contexts, including restricted reasoning capacities, ethical uncertainties, and suboptimal domain-specific performance. These challenges necessitate advanced post-training language models (PoLMs) to address these shortcomings, such as OpenAI-o1/o3 and DeepSeek-R1 (collectively known as Large Reasoning Models, or LRMs). This paper presents the first comprehensive survey of PoLMs, systematically tracing their evolution across five core paradigms: Fine-tuning, which enhances task-specific accuracy; Alignment, which ensures alignment with human preferences; Reasoning, which advances multi-step inference despite challenges in reward design; Efficiency, which optimizes resource utilization amidst increasing complexity; and Integration and Adaptation, which extend capabilities across diverse modalities while addressing coherence issues. Charting progress from ChatGPT's foundational alignment strategies to DeepSeek-R1's innovative reasoning advancements, we illustrate how PoLMs leverage datasets to mitigate biases, deepen reasoning capabilities, and enhance domain adaptability. Our contributions include a pioneering synthesis of PoLM evolution, a structured taxonomy categorizing techniques and datasets, and a strategic agenda emphasizing the role of LRMs in improving reasoning proficiency and domain flexibility. As the first survey of its scope, this work consolidates recent PoLM advancements and establishes a rigorous intellectual framework for future research, fostering the development of LLMs that excel in precision, ethical robustness, and versatility across scientific and societal applications.
From Correctness to Comprehension: AI Agents for Personalized Error Diagnosis in Education
Feb 19, 2025



Large Language Models (LLMs), such as GPT-4, have demonstrated impressive mathematical reasoning capabilities, achieving near-perfect performance on benchmarks like GSM8K. However, their application in personalized education remains limited due to an overemphasis on correctness over error diagnosis and feedback generation. Current models fail to provide meaningful insights into the causes of student mistakes, limiting their utility in educational contexts. To address these challenges, we present three key contributions. First, we introduce \textbf{MathCCS} (Mathematical Classification and Constructive Suggestions), a multi-modal benchmark designed for systematic error analysis and tailored feedback. MathCCS includes real-world problems, expert-annotated error categories, and longitudinal student data. Evaluations of state-of-the-art models, including \textit{Qwen2-VL}, \textit{LLaVA-OV}, \textit{Claude-3.5-Sonnet} and \textit{GPT-4o}, reveal that none achieved classification accuracy above 30\% or generated high-quality suggestions (average scores below 4/10), highlighting a significant gap from human-level performance. Second, we develop a sequential error analysis framework that leverages historical data to track trends and improve diagnostic precision. Finally, we propose a multi-agent collaborative framework that combines a Time Series Agent for historical analysis and an MLLM Agent for real-time refinement, enhancing error classification and feedback generation. Together, these contributions provide a robust platform for advancing personalized education, bridging the gap between current AI capabilities and the demands of real-world teaching.
On the Compositional Generalization of Multimodal LLMs for Medical Imaging
Dec 28, 2024



Multimodal large language models (MLLMs) hold significant potential in the medical field, but their capabilities are often limited by insufficient data in certain medical domains, highlighting the need for understanding what kinds of images can be used by MLLMs for generalization. Current research suggests that multi-task training outperforms single-task as different tasks can benefit each other, but they often overlook the internal relationships within these tasks, providing limited guidance on selecting datasets to enhance specific tasks. To analyze this phenomenon, we attempted to employ compositional generalization (CG)-the ability of models to understand novel combinations by recombining learned elements-as a guiding framework. Since medical images can be precisely defined by Modality, Anatomical area, and Task, naturally providing an environment for exploring CG. Therefore, we assembled 106 medical datasets to create Med-MAT for comprehensive experiments. The experiments confirmed that MLLMs can use CG to understand unseen medical images and identified CG as one of the main drivers of the generalization observed in multi-task training. Additionally, further studies demonstrated that CG effectively supports datasets with limited data and delivers consistent performance across different backbones, highlighting its versatility and broad applicability. Med-MAT is publicly available at https://github.com/FreedomIntelligence/Med-MAT.
BlenderLLM: Training Large Language Models for Computer-Aided Design with Self-improvement
Dec 16, 2024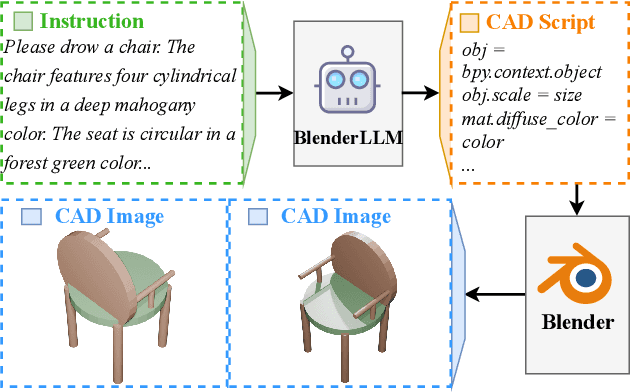
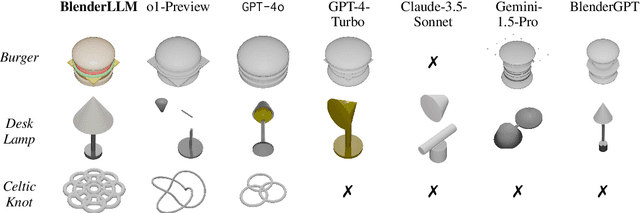
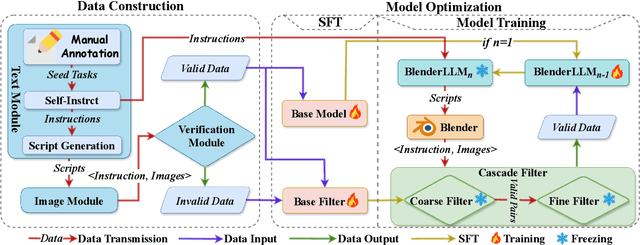
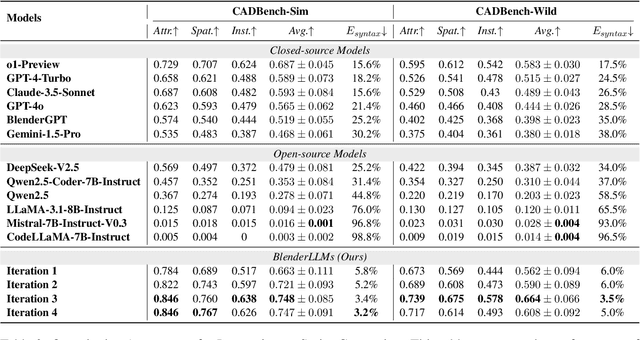
The application of Large Language Models (LLMs) in Computer-Aided Design (CAD) remains an underexplored area, despite their remarkable advancements in other domains. In this paper, we present BlenderLLM, a novel framework for training LLMs specifically for CAD tasks leveraging a self-improvement methodology. To support this, we developed a bespoke training dataset, BlendNet, and introduced a comprehensive evaluation suite, CADBench. Our results reveal that existing models demonstrate significant limitations in generating accurate CAD scripts. However, through minimal instruction-based fine-tuning and iterative self-improvement, BlenderLLM significantly surpasses these models in both functionality and accuracy of CAD script generation. This research establishes a strong foundation for the application of LLMs in CAD while demonstrating the transformative potential of self-improving models in advancing CAD automation. We encourage further exploration and adoption of these methodologies to drive innovation in the field. The dataset, model, benchmark, and source code are publicly available at https://github.com/FreedomIntelligence/BlenderLLM
Both Text and Images Leaked! A Systematic Analysis of Multimodal LLM Data Contamination
Nov 06, 2024



The rapid progression of multimodal large language models (MLLMs) has demonstrated superior performance on various multimodal benchmarks. However, the issue of data contamination during training creates challenges in performance evaluation and comparison. While numerous methods exist for detecting dataset contamination in large language models (LLMs), they are less effective for MLLMs due to their various modalities and multiple training phases. In this study, we introduce a multimodal data contamination detection framework, MM-Detect, designed for MLLMs. Our experimental results indicate that MM-Detect is sensitive to varying degrees of contamination and can highlight significant performance improvements due to leakage of the training set of multimodal benchmarks. Furthermore, We also explore the possibility of contamination originating from the pre-training phase of LLMs used by MLLMs and the fine-tuning phase of MLLMs, offering new insights into the stages at which contamination may be introduced.
Less is More: A Simple yet Effective Token Reduction Method for Efficient Multi-modal LLMs
Sep 17, 2024The rapid advancement of Multimodal Large Language Models (MLLMs) has led to remarkable performances across various domains. However, this progress is accompanied by a substantial surge in the resource consumption of these models. We address this pressing issue by introducing a new approach, Token Reduction using CLIP Metric (TRIM), aimed at improving the efficiency of MLLMs without sacrificing their performance. Inspired by human attention patterns in Visual Question Answering (VQA) tasks, TRIM presents a fresh perspective on the selection and reduction of image tokens. The TRIM method has been extensively tested across 12 datasets, and the results demonstrate a significant reduction in computational overhead while maintaining a consistent level of performance. This research marks a critical stride in efficient MLLM development, promoting greater accessibility and sustainability of high-performing models.
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
Sep 04, 2024



Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is crucial for video understanding, high-resolution image understanding, and multi-modal agents. This involves a series of systematic optimizations, including model architecture, data construction and training strategy, particularly addressing challenges such as \textit{degraded performance with more images} and \textit{high computational costs}. In this paper, we adapt the model architecture to a hybrid of Mamba and Transformer blocks, approach data construction with both temporal and spatial dependencies among multiple images and employ a progressive training strategy. The released model \textbf{LongLLaVA}~(\textbf{Long}-Context \textbf{L}arge \textbf{L}anguage \textbf{a}nd \textbf{V}ision \textbf{A}ssistant) is the first hybrid MLLM, which achieved a better balance between efficiency and effectiveness. LongLLaVA not only achieves competitive results across various benchmarks, but also maintains high throughput and low memory consumption. Especially, it could process nearly a thousand images on a single A100 80GB GPU, showing promising application prospects for a wide range of tasks.