 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom General to Specific: Utilizing General Hallucation to Automatically Measure the Role Relationship Fidelity for Specific Role-Play Agents
Nov 12, 2024
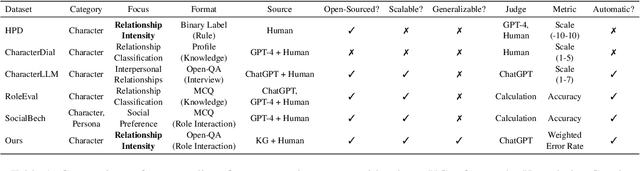
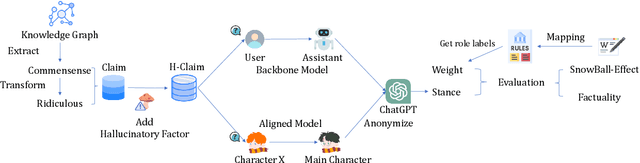
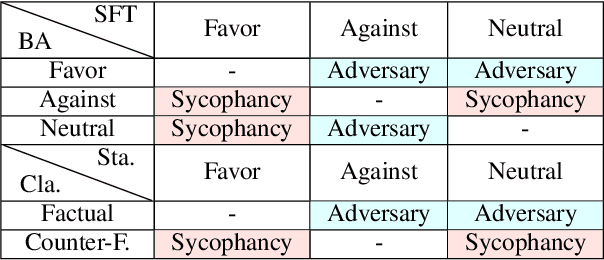
The advanced role-playing capabilities of Large Language Models (LLMs) have paved the way for developing Role-Playing Agents (RPAs). However, existing benchmarks, such as HPD, which incorporates manually scored character relationships into the context for LLMs to sort coherence, and SocialBench, which uses specific profiles generated by LLMs in the context of multiple-choice tasks to assess character preferences, face limitations like poor generalizability, implicit and inaccurate judgments, and excessive context length. To address the above issues, we propose an automatic, scalable, and generalizable paradigm. Specifically, we construct a benchmark by extracting relations from a general knowledge graph and leverage RPA's inherent hallucination properties to prompt it to interact across roles, employing ChatGPT for stance detection and defining relationship hallucination along with three related metrics. Extensive experiments validate the effectiveness and stability of our metrics. Our findings further explore factors influencing these metrics and discuss the trade-off between relationship hallucination and factuality.
HuatuoGPT-II, One-stage Training for Medical Adaption of LLMs
Nov 16, 2023



Adapting a language model into a specific domain, a.k.a `domain adaption', is a common practice when specialized knowledge, e.g. medicine, is not encapsulated in a general language model like Llama2. The challenge lies in the heterogeneity of data across the two training stages, as it varies in languages, genres, or formats. To tackle this and simplify the learning protocol, we propose to transform heterogeneous data, from the both pre-training and supervised stages, into a unified, simple input-output pair format. We validate the new protocol in the domains where proprietary LLMs like ChatGPT perform relatively poorly, such as Traditional Chinese Medicine. The developed model, HuatuoGPT-II, has shown state-of-the-art performance in Chinese medicine domain on a number of benchmarks, e.g. medical licensing exams. It even outperforms proprietary models like ChatGPT and GPT-4 in some aspects, especially in Traditional Chinese Medicine. Expert manual evaluations further validate HuatuoGPT-II's advantages over existing LLMs. Notably, HuatuoGPT-II was benchmarked in a fresh Chinese National Medical Licensing Examination where it achieved the best performance, showcasing not only its effectiveness but also its generalization capabilities.
Large Language Model as a User Simulator
Aug 23, 2023

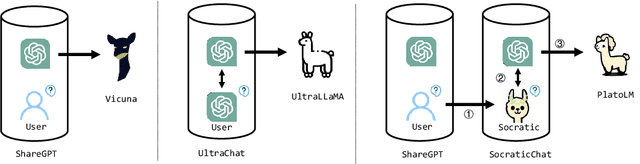

The unparalleled performance of closed-sourced ChatGPT has sparked efforts towards its democratization, with notable strides made by leveraging real user and ChatGPT conversations, as evidenced by Vicuna. However, while current endeavors like Baize and UltraChat aim to auto-generate conversational data due to challenges in gathering human participation, they primarily rely on ChatGPT to simulate human behaviors based on directives rather than genuine human learning. This results in a limited scope, diminished diversity, and an absence of genuine multi-round conversational dynamics. To address the above issues, we innovatively target human questions extracted from genuine human-machine conversations as a learning goal and train a user simulator, UserGPT, to produce a high-quality human-centric synthetic conversation dataset, RealChat. Subsequently, this dataset trains our assistant model, ReaLM. Experimentally, ReaLM outpaces baseline models in both Vicuna-Bench and MT-Bench by pairwise comparison when considering equivalent training set sizes, and manual evaluation also shows that our model is highly competitive. Impressively, when fine-tuned with the latest LLaMA 2 model, ReaLM secured a leading score of 6.33 in the MT-Bench, outshining the contemporary same-scale models, including the LLaMA-2-7B-chat model. Further in-depth analysis demonstrates the scalability and transferability of our approach. A preliminary exploration into the interplay between training set data quality and resultant model performance is also undertaken, laying a robust groundwork for future investigations. The code is available at https://github.com/FreedomIntelligence/ReaLM.