 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucination in Financial Retrieval-Augmented Generation via Fine-Grained Knowledge Verification
Feb 05, 2026In financial Retrieval-Augmented Generation (RAG) systems, models frequently rely on retrieved documents to generate accurate responses due to the time-sensitive nature of the financial domain. While retrieved documents help address knowledge gaps, model-generated responses still suffer from hallucinations that contradict the retrieved information. To mitigate this inconsistency, we propose a Reinforcement Learning framework enhanced with Fine-grained Knowledge Verification (RLFKV). Our method decomposes financial responses into atomic knowledge units and assesses the correctness of each unit to compute the fine-grained faithful reward. This reward offers more precise optimization signals, thereby improving alignment with the retrieved documents. Additionally, to prevent reward hacking (e.g., overly concise replies), we incorporate an informativeness reward that encourages the policy model to retain at least as many knowledge units as the base model. Experiments conducted on the public Financial Data Description (FDD) task and our newly proposed FDD-ANT dataset demonstrate consistent improvements, confirming the effectiveness of our approach.
Improving Dialogue Discourse Parsing through Discourse-aware Utterance Clarification
Jun 18, 2025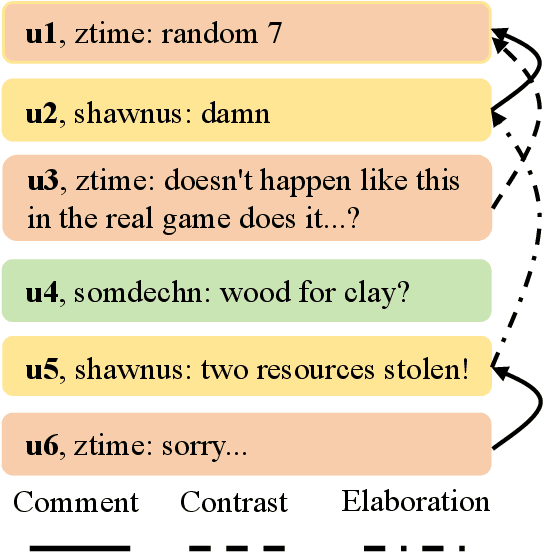
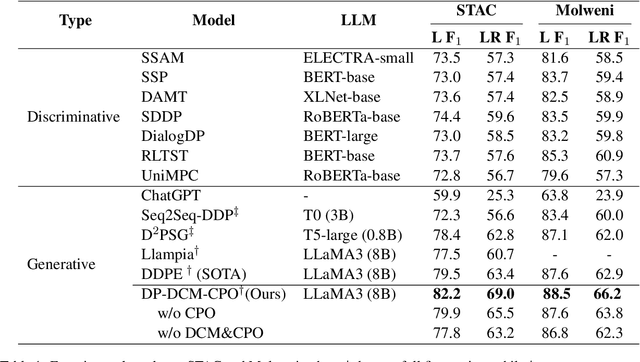
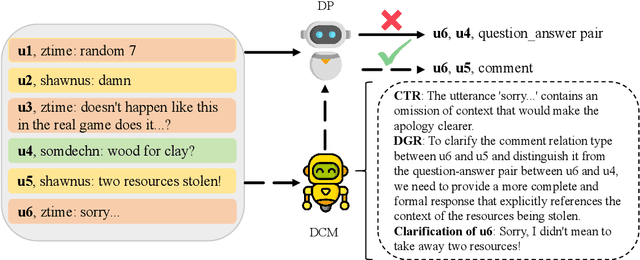
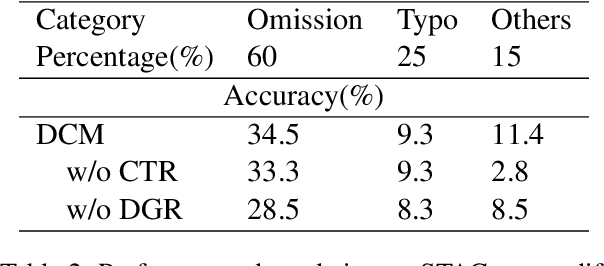
Dialogue discourse parsing aims to identify and analyze discourse relations between the utterances within dialogues. However, linguistic features in dialogues, such as omission and idiom, frequently introduce ambiguities that obscure the intended discourse relations, posing significant challenges for parsers. To address this issue, we propose a Discourse-aware Clarification Module (DCM) to enhance the performance of the dialogue discourse parser. DCM employs two distinct reasoning processes: clarification type reasoning and discourse goal reasoning. The former analyzes linguistic features, while the latter distinguishes the intended relation from the ambiguous one. Furthermore, we introduce Contribution-aware Preference Optimization (CPO) to mitigate the risk of erroneous clarifications, thereby reducing cascading errors. CPO enables the parser to assess the contributions of the clarifications from DCM and provide feedback to optimize the DCM, enhancing its adaptability and alignment with the parser's requirements. Extensive experiments on the STAC and Molweni datasets demonstrate that our approach effectively resolves ambiguities and significantly outperforms the state-of-the-art (SOTA) baselines.
Enhancing Goal-oriented Proactive Dialogue Systems via Consistency Reflection and Correction
Jun 16, 2025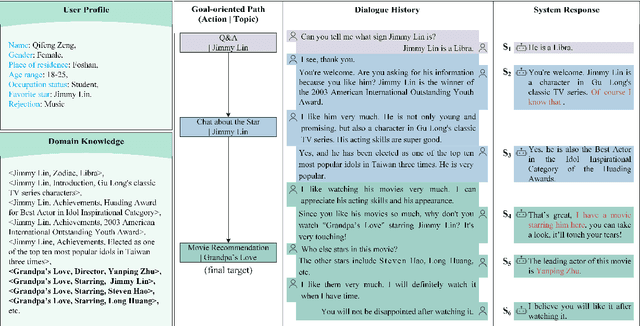
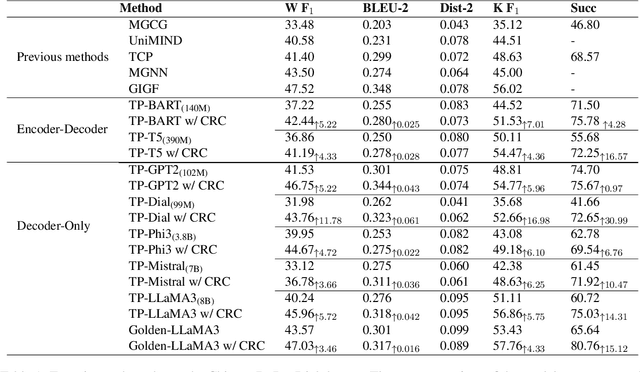
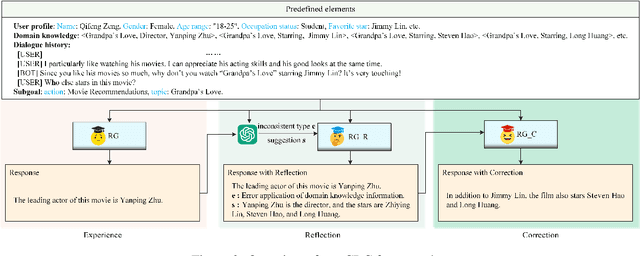
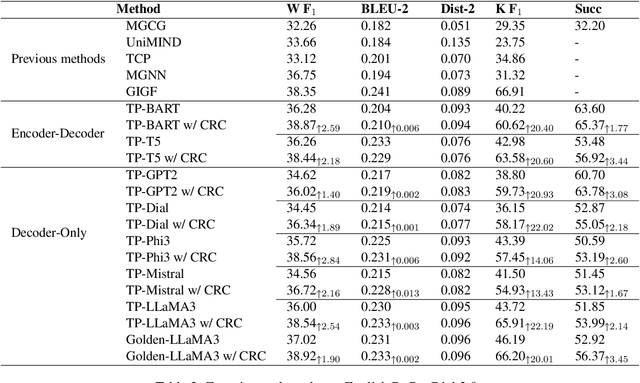
This paper proposes a consistency reflection and correction method for goal-oriented dialogue systems.
Incomplete Utterance Rewriting with Editing Operation Guidance and Utterance Augmentation
Mar 20, 2025Although existing fashionable generation methods on Incomplete Utterance Rewriting (IUR) can generate coherent utterances, they often result in the inclusion of irrelevant and redundant tokens in rewritten utterances due to their inability to focus on critical tokens in dialogue context. Furthermore, the limited size of the training datasets also contributes to the insufficient training of the IUR model. To address the first issue, we propose a multi-task learning framework EO-IUR (Editing Operation-guided Incomplete Utterance Rewriting) that introduces the editing operation labels generated by sequence labeling module to guide generation model to focus on critical tokens. Furthermore, we introduce a token-level heterogeneous graph to represent dialogues. To address the second issue, we propose a two-dimensional utterance augmentation strategy, namely editing operation-based incomplete utterance augmentation and LLM-based historical utterance augmentation. The experimental results on three datasets demonstrate that our EO-IUR outperforms previous state-of-the-art (SOTA) baselines in both open-domain and task-oriented dialogue. The code will be available at https://github.com/Dewset/EO-IUR.
Two-stage Incomplete Utterance Rewriting on Editing Operation
Mar 20, 2025Previous work on Incomplete Utterance Rewriting (IUR) has primarily focused on generating rewritten utterances based solely on dialogue context, ignoring the widespread phenomenon of coreference and ellipsis in dialogues. To address this issue, we propose a novel framework called TEO (\emph{Two-stage approach on Editing Operation}) for IUR, in which the first stage generates editing operations and the second stage rewrites incomplete utterances utilizing the generated editing operations and the dialogue context. Furthermore, an adversarial perturbation strategy is proposed to mitigate cascading errors and exposure bias caused by the inconsistency between training and inference in the second stage. Experimental results on three IUR datasets show that our TEO outperforms the SOTA models significantly.
From General to Specific: Utilizing General Hallucation to Automatically Measure the Role Relationship Fidelity for Specific Role-Play Agents
Nov 12, 2024
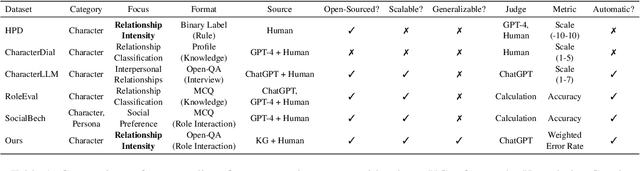
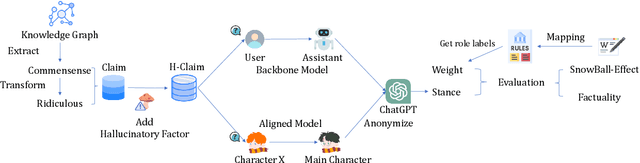
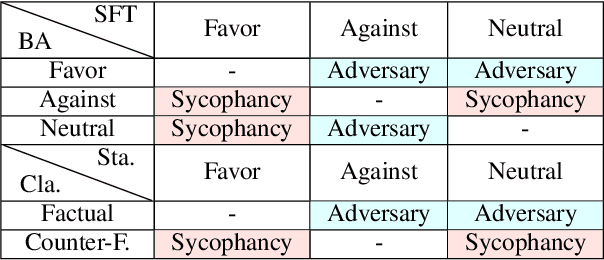
The advanced role-playing capabilities of Large Language Models (LLMs) have paved the way for developing Role-Playing Agents (RPAs). However, existing benchmarks, such as HPD, which incorporates manually scored character relationships into the context for LLMs to sort coherence, and SocialBench, which uses specific profiles generated by LLMs in the context of multiple-choice tasks to assess character preferences, face limitations like poor generalizability, implicit and inaccurate judgments, and excessive context length. To address the above issues, we propose an automatic, scalable, and generalizable paradigm. Specifically, we construct a benchmark by extracting relations from a general knowledge graph and leverage RPA's inherent hallucination properties to prompt it to interact across roles, employing ChatGPT for stance detection and defining relationship hallucination along with three related metrics. Extensive experiments validate the effectiveness and stability of our metrics. Our findings further explore factors influencing these metrics and discuss the trade-off between relationship hallucination and factuality.
Quantify Health-Related Atomic Knowledge in Chinese Medical Large Language Models: A Computational Analysis
Oct 18, 2023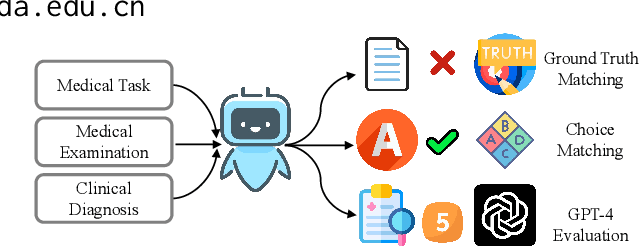
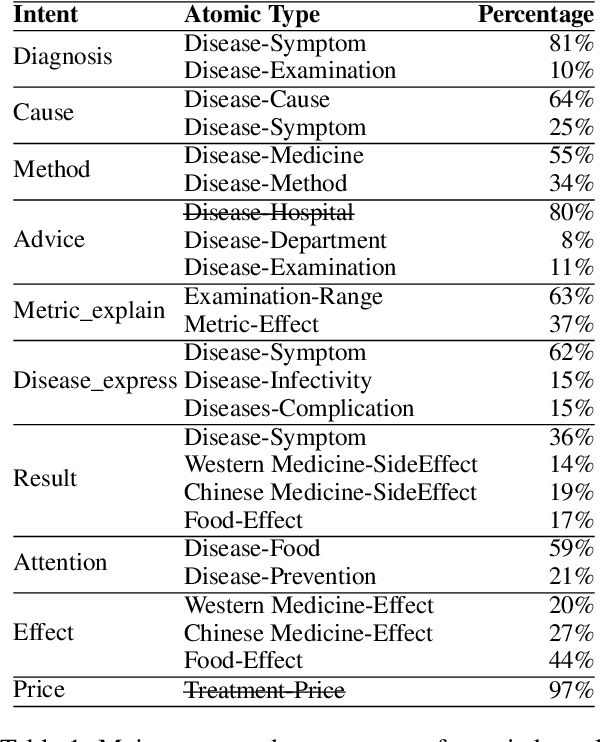

Large Language Models (LLMs) have the potential to revolutionize the way users self-diagnose through search engines by offering direct and efficient suggestions. Recent studies primarily focused on the quality of LLMs evaluated by GPT-4 or their ability to pass medical exams, no studies have quantified the extent of health-related atomic knowledge stored in LLMs' memory, which is the basis of LLMs to provide more factual suggestions. In this paper, we first constructed a benchmark, including the most common types of atomic knowledge in user self-diagnosis queries, with 17 atomic types and a total of 14, 048 pieces of atomic knowledge. Then, we evaluated both generic and specialized LLMs on the benchmark. The experimental results showcased that generic LLMs perform better than specialized LLMs in terms of atomic knowledge and instruction-following ability. Error analysis revealed that both generic and specialized LLMs are sycophantic, e.g., always catering to users' claims when it comes to unknown knowledge. Besides, generic LLMs showed stronger safety, which can be learned by specialized LLMs through distilled data. We further explored different types of data commonly adopted for fine-tuning specialized LLMs, i.e., real-world, semi-distilled, and distilled data, and found that distilled data can benefit LLMs most.
Large Language Model as a User Simulator
Aug 23, 2023

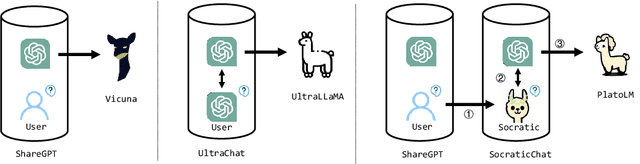

The unparalleled performance of closed-sourced ChatGPT has sparked efforts towards its democratization, with notable strides made by leveraging real user and ChatGPT conversations, as evidenced by Vicuna. However, while current endeavors like Baize and UltraChat aim to auto-generate conversational data due to challenges in gathering human participation, they primarily rely on ChatGPT to simulate human behaviors based on directives rather than genuine human learning. This results in a limited scope, diminished diversity, and an absence of genuine multi-round conversational dynamics. To address the above issues, we innovatively target human questions extracted from genuine human-machine conversations as a learning goal and train a user simulator, UserGPT, to produce a high-quality human-centric synthetic conversation dataset, RealChat. Subsequently, this dataset trains our assistant model, ReaLM. Experimentally, ReaLM outpaces baseline models in both Vicuna-Bench and MT-Bench by pairwise comparison when considering equivalent training set sizes, and manual evaluation also shows that our model is highly competitive. Impressively, when fine-tuned with the latest LLaMA 2 model, ReaLM secured a leading score of 6.33 in the MT-Bench, outshining the contemporary same-scale models, including the LLaMA-2-7B-chat model. Further in-depth analysis demonstrates the scalability and transferability of our approach. A preliminary exploration into the interplay between training set data quality and resultant model performance is also undertaken, laying a robust groundwork for future investigations. The code is available at https://github.com/FreedomIntelligence/ReaLM.
GrammarGPT: Exploring Open-Source LLMs for Native Chinese Grammatical Error Correction with Supervised Fine-Tuning
Aug 17, 2023Grammatical error correction aims to correct ungrammatical sentences automatically. Recently, some work has demonstrated the excellent capabilities of closed-source Large Language Models (LLMs, e.g., ChatGPT) in grammatical error correction. However, the potential of open-source LLMs remains unexplored. In this paper, we introduced GrammarGPT, an open-source LLM, to preliminary explore its potential for native Chinese grammatical error correction. The core recipe of GrammarGPT is to leverage the hybrid dataset of ChatGPT-generated and human-annotated. For grammatical errors with clues, we proposed a heuristic method to guide ChatGPT to generate ungrammatical sentences by providing those clues. For grammatical errors without clues, we collected ungrammatical sentences from publicly available websites and manually corrected them. In addition, we employed an error-invariant augmentation method to enhance the ability of the model to correct native Chinese grammatical errors. We ultimately constructed about 1k parallel data and utilized these data to fine-tune open-source LLMs (e.g., Phoenix, released by The Chinese University of Hong Kong, Shenzhen) with instruction tuning. The experimental results show that GrammarGPT outperforms the existing SOTA system significantly. Although model parameters are 20x larger than the SOTA baseline, the required amount of data for instruction tuning is 1200x smaller, illustrating the potential of open-source LLMs on native CGEC. Our GrammarGPT ranks $3^{rd}$ on NLPCC2023 SharedTask1, demonstrating our approach's effectiveness. The code and data are available at \url{https://github.com/FreedomIntelligence/GrammarGPT}.
Multi-Granularity Prompts for Topic Shift Detection in Dialogue
May 23, 2023
The goal of dialogue topic shift detection is to identify whether the current topic in a conversation has changed or needs to change. Previous work focused on detecting topic shifts using pre-trained models to encode the utterance, failing to delve into the various levels of topic granularity in the dialogue and understand dialogue contents. To address the above issues, we take a prompt-based approach to fully extract topic information from dialogues at multiple-granularity, i.e., label, turn, and topic. Experimental results on our annotated Chinese Natural Topic Dialogue dataset CNTD and the publicly available English TIAGE dataset show that the proposed model outperforms the baselines. Further experiments show that the information extracted at different levels of granularity effectively helps the model comprehend the conversation topics.