 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Topic Segmentation and Outline Generation in Chinese Texts: The Paragraph-level Topic Representation, Corpus, and Benchmark
May 24, 2023

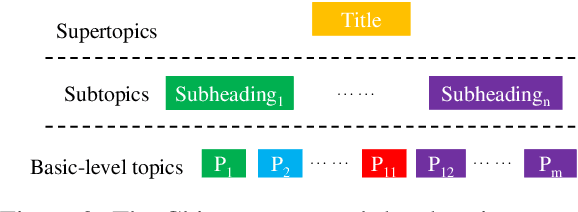

Topic segmentation and outline generation strive to divide a document into coherent topic sections and generate corresponding subheadings. Such a process unveils the discourse topic structure of a document that benefits quickly grasping and understanding the overall context of the document from a higher level. However, research and applications in this field have been restrained due to the lack of proper paragraph-level topic representations and large-scale, high-quality corpora in Chinese compared to the success achieved in English. Addressing these issues, we introduce a hierarchical paragraph-level topic structure representation with title, subheading, and paragraph that comprehensively models the document discourse topic structure. In addition, we ensure a more holistic representation of topic distribution within the document by using sentences instead of keywords to represent sub-topics. Following this representation, we construct the largest Chinese Paragraph-level Topic Structure corpus (CPTS), four times larger than the previously largest one. We also employ a two-stage man-machine collaborative annotation method to ensure the high quality of the corpus both in form and semantics. Finally, we validate the computability of CPTS on two fundamental tasks (topic segmentation and outline generation) by several strong baselines, and its efficacy has been preliminarily confirmed on the downstream task: discourse parsing. The representation, corpus, and benchmark we established will provide a solid foundation for future studies.
Multi-Granularity Prompts for Topic Shift Detection in Dialogue
May 23, 2023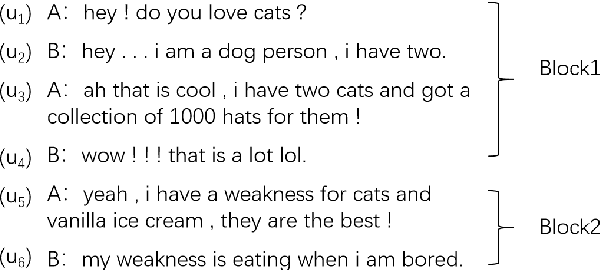
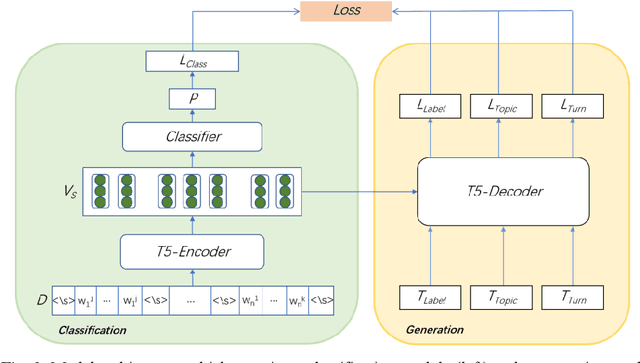
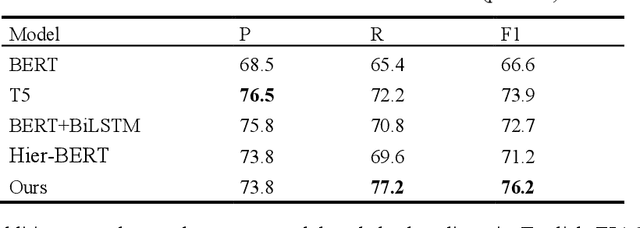
The goal of dialogue topic shift detection is to identify whether the current topic in a conversation has changed or needs to change. Previous work focused on detecting topic shifts using pre-trained models to encode the utterance, failing to delve into the various levels of topic granularity in the dialogue and understand dialogue contents. To address the above issues, we take a prompt-based approach to fully extract topic information from dialogues at multiple-granularity, i.e., label, turn, and topic. Experimental results on our annotated Chinese Natural Topic Dialogue dataset CNTD and the publicly available English TIAGE dataset show that the proposed model outperforms the baselines. Further experiments show that the information extracted at different levels of granularity effectively helps the model comprehend the conversation topics.
Topic Shift Detection in Chinese Dialogues: Corpus and Benchmark
May 02, 2023



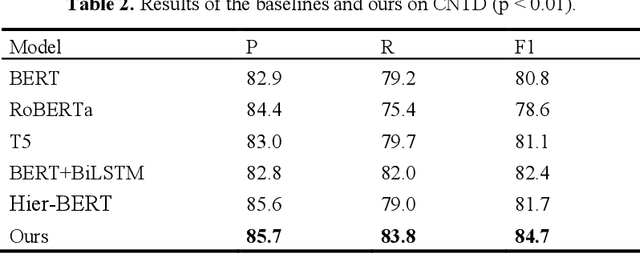
Dialogue topic shift detection is to detect whether an ongoing topic has shifted or should shift in a dialogue, which can be divided into two categories, i.e., response-known task and response-unknown task. Currently, only a few investigated the latter, because it is still a challenge to predict the topic shift without the response information. In this paper, we first annotate a Chinese Natural Topic Dialogue (CNTD) corpus consisting of 1308 dialogues to fill the gap in the Chinese natural conversation topic corpus. And then we focus on the response-unknown task and propose a teacher-student framework based on hierarchical contrastive learning to predict the topic shift without the response. Specifically, the response at high-level teacher-student is introduced to build the contrastive learning between the response and the context, while the label contrastive learning is constructed at low-level student. The experimental results on our Chinese CNTD and English TIAGE show the effectiveness of our proposed model.
SemanticCAP: Chromatin Accessibility Prediction Enhanced by Features Learning from a Language Model
Apr 06, 2022
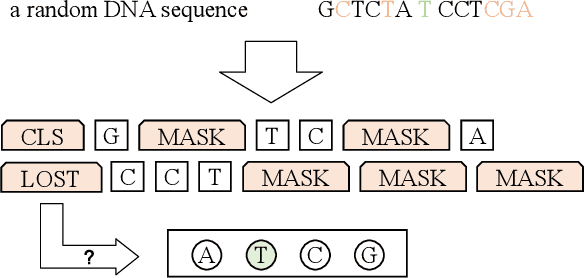
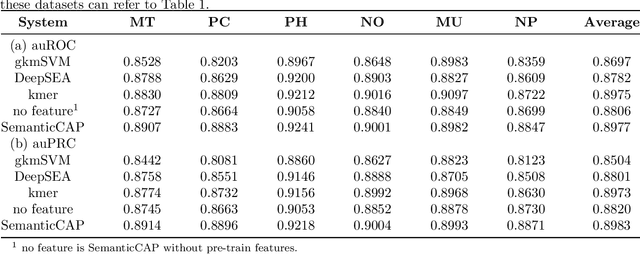
A large number of inorganic and organic compounds are able to bind DNA and form complexes, among which drug-related molecules are important. Chromatin accessibility changes not only directly affects drug-DNA interactions, but also promote or inhibit the expression of critical genes associated with drug resistance by affecting the DNA binding capacity of TFs and transcriptional regulators. However, Biological experimental techniques for measuring it are expensive and time consuming. In recent years, several kinds of computational methods have been proposed to identify accessible regions of the genome. Existing computational models mostly ignore the contextual information of bases in gene sequences. To address these issues, we proposed a new solution named SemanticCAP. It introduces a gene language model which models the context of gene sequences, thus being able to provide an effective representation of a certain site in gene sequences. Basically, we merge the features provided by the gene language model into our chromatin accessibility model. During the process, we designed some methods to make feature fusion smoother. Compared with other systems under public benchmarks, our model proved to have better performance.