 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantify Health-Related Atomic Knowledge in Chinese Medical Large Language Models: A Computational Analysis
Paper and Code
Oct 18, 2023
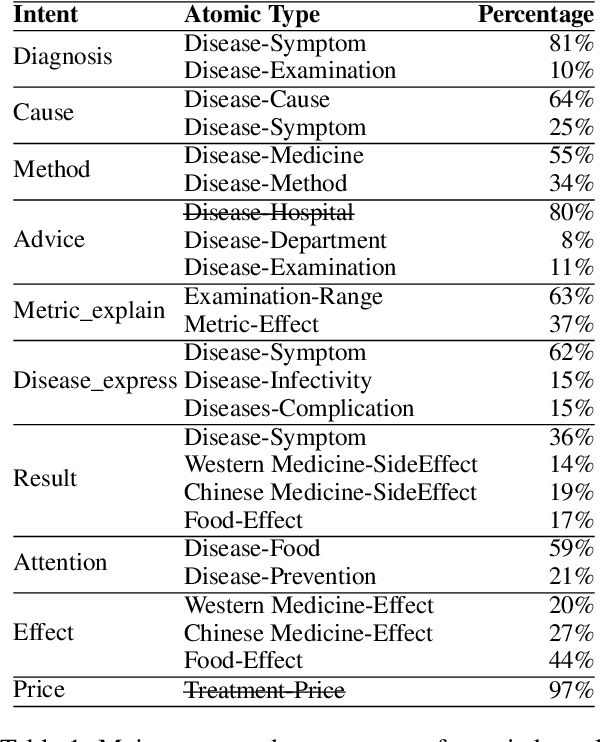
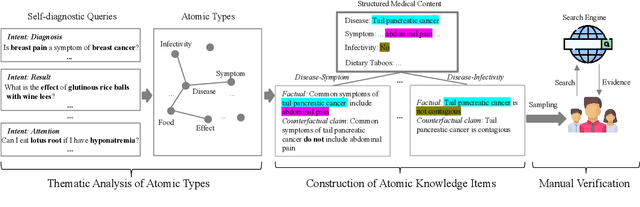

Large Language Models (LLMs) have the potential to revolutionize the way users self-diagnose through search engines by offering direct and efficient suggestions. Recent studies primarily focused on the quality of LLMs evaluated by GPT-4 or their ability to pass medical exams, no studies have quantified the extent of health-related atomic knowledge stored in LLMs' memory, which is the basis of LLMs to provide more factual suggestions. In this paper, we first constructed a benchmark, including the most common types of atomic knowledge in user self-diagnosis queries, with 17 atomic types and a total of 14, 048 pieces of atomic knowledge. Then, we evaluated both generic and specialized LLMs on the benchmark. The experimental results showcased that generic LLMs perform better than specialized LLMs in terms of atomic knowledge and instruction-following ability. Error analysis revealed that both generic and specialized LLMs are sycophantic, e.g., always catering to users' claims when it comes to unknown knowledge. Besides, generic LLMs showed stronger safety, which can be learned by specialized LLMs through distilled data. We further explored different types of data commonly adopted for fine-tuning specialized LLMs, i.e., real-world, semi-distilled, and distilled data, and found that distilled data can benefit LLMs most.