 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom General to Specific: Utilizing General Hallucation to Automatically Measure the Role Relationship Fidelity for Specific Role-Play Agents
Paper and Code

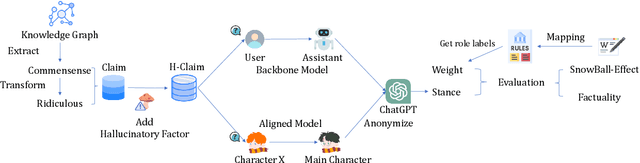
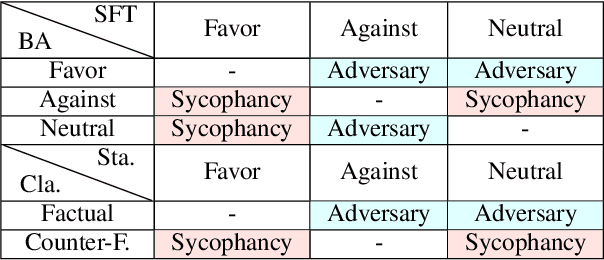
The advanced role-playing capabilities of Large Language Models (LLMs) have paved the way for developing Role-Playing Agents (RPAs). However, existing benchmarks, such as HPD, which incorporates manually scored character relationships into the context for LLMs to sort coherence, and SocialBench, which uses specific profiles generated by LLMs in the context of multiple-choice tasks to assess character preferences, face limitations like poor generalizability, implicit and inaccurate judgments, and excessive context length. To address the above issues, we propose an automatic, scalable, and generalizable paradigm. Specifically, we construct a benchmark by extracting relations from a general knowledge graph and leverage RPA's inherent hallucination properties to prompt it to interact across roles, employing ChatGPT for stance detection and defining relationship hallucination along with three related metrics. Extensive experiments validate the effectiveness and stability of our metrics. Our findings further explore factors influencing these metrics and discuss the trade-off between relationship hallucination and factuality.